APSUM:稀疏主题模型用于在线评论的细粒度摘要生成
PDF格式 | 1.8MB |
更新于2025-01-16
| 197 浏览量 | 举报
"在线评论中生成细粒度摘要:稀疏主题模型(APSUM)"
本文主要探讨了如何利用一种名为APSUM(Aspect-based Summarization with Sparse Topic Model)的稀疏主题模型,从在线评论中抽取特定方面的摘要,以帮助消费者在购买决策过程中更有效地获取信息。随着电子商务的发展,消费者在购买产品前会参考大量的在线评论,但这些评论往往数量庞大,难以逐一阅读。针对这一问题,APSUM模型旨在生成细粒度的摘要,将评论的关键信息归纳到不同的产品方面,如性能、功能或质量等。
APSUM模型的核心在于处理方面稀疏性的问题。一方面,它采用了尖峰和厚板先验(spike-and-slab prior)来调整文档的主题分布,这种分布允许模型在识别主题时保持一定的灵活性,同时也能捕捉到与特定方面相关的稀疏信息。另一方面,模型还引入了语言监督词(linguistic supervision word)来引导主题建模,确保生成的摘要能够紧密围绕消费者关心的特定方面。
在实验部分,APSUM模型在多个数据集上与其他先进的方面摘要模型进行了比较,结果表明APSUM在性能上优于现有方法,能生成更具洞察力的细粒度摘要。这些摘要可以帮助消费者快速定位他们关注的产品特性,从而简化购买决策过程。
该研究进一步关联了几个计算机科学领域的关键概念,如数据挖掘、信息检索、文档主题模型和机器学习。其中,主题建模是APSUM模型的核心技术,通过概率生成模型分析文本数据,识别出隐藏的主题结构。信息检索则涉及如何从大量评论中提取与消费者查询相关的信息。
APSUM模型为在线评论的处理提供了新的视角,通过细致入微的摘要生成,提升了消费者获取产品信息的效率,同时也为电子商务平台提供了优化用户体验的工具。该研究对于理解和改进在线评论的处理方式具有重要的理论与实践意义。
主题:
Web Search and
Mining
WWW 2018
,
2018
年
4
月
23
日至
27
日,法
国里昂
1575
- -
- -
- -
- -
k
,
v
∈
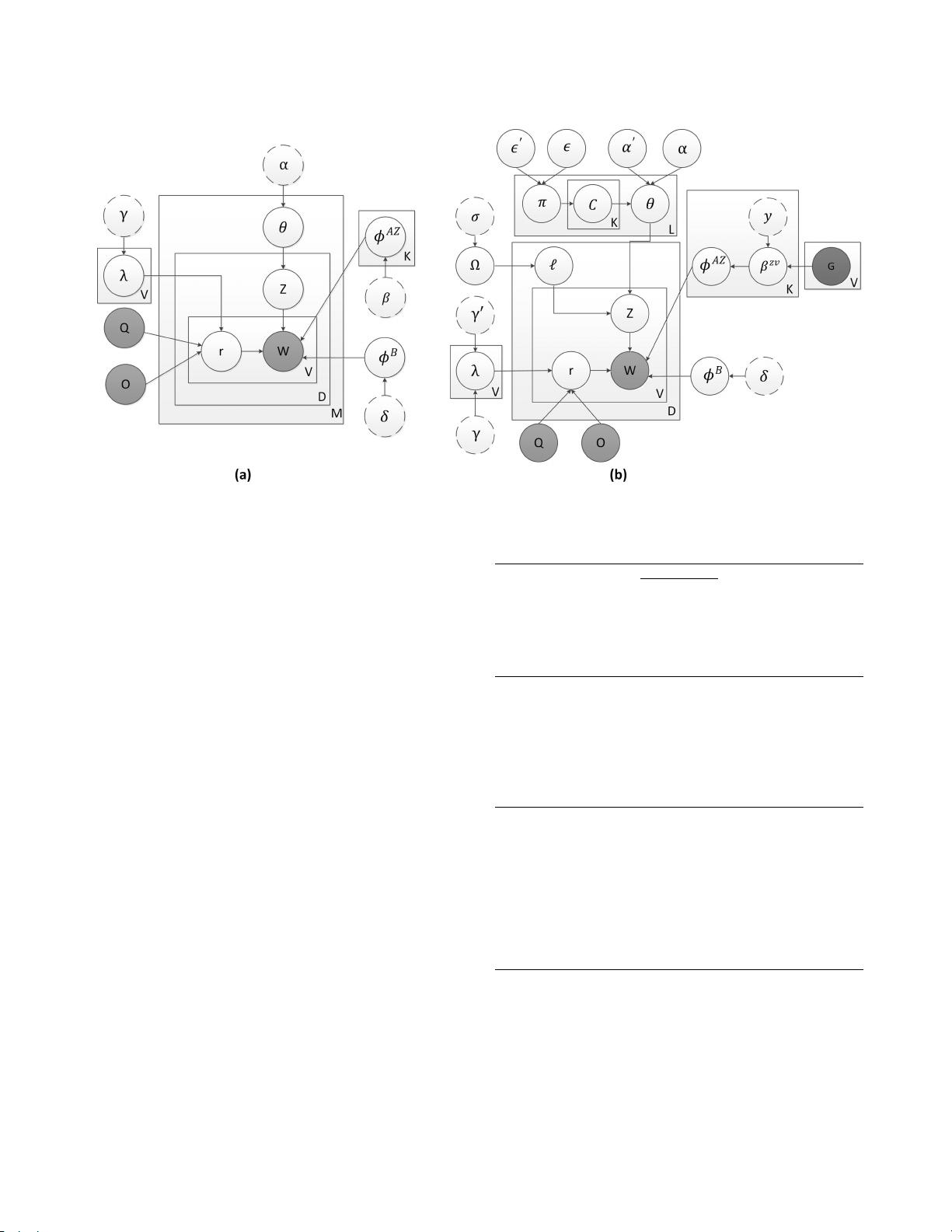
图2:(a)简单方面模型M-ASUM和(b)所提出的方面概括模型AP-SUM的图形结构
优先于文档主题空间,以及(
c
)
在词主题超参数上这些组件在
下文中更详细地解释:
减轻方面稀疏性:在第1节中,我们提到
对应于查询的评论可能非常稀疏。
这基本上转化为
短文本中缺
乏单词共现因此,我们引入了一个变量l,作为一个
文档聚合
器
来克服这个问题。模型的生成过程开始于对每个文档采样
l
。现在,当对文档
d
的主题进行采样时,我们使用
l
而不是
d
的
主题分布。
约束文档主题空间:
spike
和
slab
技术最初由Wang等人引入 [26]以控制主题混合物的导航和概
率单纯形中的单词分布
,后来扩展到包括弱平滑器
[13]
。在我们
的模型中(如图
2
(
b
)所示),我们使用伯努利变量
c
引入该技
术
,该伯努利变量c
通过开启
引入尖峰(即,将其分配给1)
或关闭(即,分配
表1:本文中使用的符号列表
符号描述
D=
d
i
文档集,
d
i
表示单个文档
V
=
v
j
单词集
C
用于
尖峰
主题分布
的
Z=
z
i
潜在主题的集合
K
主题数
Q,O
分别观察用户查询和意见语料
θ
文档
-
主题分布
AZ
方面主题分布
B
背景词分布
Ω
文档聚合器分发
Π
聚合器
-
主题分配分布
λ
词相关性分布
Dirichlet
先验
的
α
,
β
,
δ
,
σ
超
参数
γ
,
γ
′
,
ε
,
ε
′
Beta先验n的
超
参数
ZV
a
#词
v
分配给主题
k
它到
0
)特定主题
z
。然后通过下式引入平滑
超参数
α
和
α
′
。这确保了每个文档(即,
综述)主题分布θ在狭
窄的
主题空间
上高度集中,同时避免文档主题分布变得不明
确。因此,在上一步中对
l
进行采样之后,我们对每个主题
z K
的主题选择器c
进行
采样。约束词主题空间:为了获得关注于
用户查询的方面,重要的是不仅约束词主题空间,而且约束
词主题空间。
n
V
v
LC
l
,
c
LD
l,d
Z L
z,l
RV
r
,
w
#背景词v
b
#times选择变量c被分配给聚合器l#聚合器l被分配给
文档d
#分配给聚合器l中的主题z的词#分配给
相关性r={0, 1}的词w
文献
-
话题比例,还有词
-
话题比例。
为此,我们以词关联的形式
在模型中注入了一些监督。在图
2
(
b
)中,该分量被示出为观测
变量
G
。这个公式背后的基本原理很简单,
如果我们知道单词lens
和zoom是相关的,那么
我们可以使用这个监督信息来关联这些
单词的主题分布。
两个字
。因此,我们以变量y的形式在词主题平滑器β上引入
下游
条件。通过这种方式,单词主题稀疏性被自然地注入到
模型中,同时避免了过度拟合的问题在[18]中,
作者使用类似
的技术将监督纳入
B
n
n
n
n
剩余10页未读,继续阅读
相关推荐



cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网页自动刷新工具 v1.1 - 自定义时间间隔与关机
- pt-1.4协程源码深度解析
- EP4CE6E22C8芯片三相正弦波发生器设计与实现
- 高效处理超大XML文件的查看工具介绍
- 64K极限挑战:国际程序设计大赛优秀3D作品展
- ENVI软件全面应用教程指南
- 学生档案管理系统设计与开发
- 网络伪书:社区驱动的在线音乐制图平台
- Lettuce 5.0.3中文API文档完整包下载指南
- 雅虎通Yahoo! Messenger v0.8.115即时聊天功能详解
- 将Android手机转变为IP监控摄像机
- PLSQL入门教程:变量声明与程序交互
- 掌握.NET三层架构:实例学习与源码解析
- WPF中Devexpress GridControl分组功能实例分析
- H3Viewer: VS2010专用高效帮助文档查看工具
- STM32CubeMX LED与按键初始化及外部中断处理教程
