监督新与旧:从SFM中学习SFM
129 浏览量
更新于2025-01-16
收藏 1.24MB PDF 举报

监督新与旧:从SFM中学习SFM
Maria Klodt
[0000
−
0003
−
3015
−
9584]
和Andrea Vedaldi
[0000
−
0003
−
1374
−
2858]
牛津大学视觉几何组
{klodt,vedaldi}@ robots.ox.ac.uk
抽象。最近的工作表明,可以
从未标记的视频序列
学习用于
单目深度和自我运动估计的深度神经网络,这是一个有趣
的理论发展,在应用中具有许多优势在本文中,我们提出
了一些改进这些方法。首先,由于这种自我监督的方法是
基于亮度恒定性假设,这是有效的像素的一个子集,我们
提出了一个概率
学习公式,其中网络预测分布在
变量,而不
是特定的值。由于这些分布以观察到的图像为条件,因此
网络可以学习哪些场景和对象类型可能违反模型假设,从
而导致更鲁棒的学习。 我们还建议建立在几十年的经验
,
开发手工制作的结构从运动(SFM)算法。 我们
通过使用现
成的SFM系统来为深度神经网络生成监督信号来做到这一
点。虽然这个信号也有噪声,但我们证明了我们的概率公
式可以学习和解释
SFM的缺陷,有助于整合不同的信息源并
提高网络的整体性能。
1
介绍
视觉几何是计算机视觉中少数几个传统方法部分抵制深度学习的领域
之一。然而,社区现在已经开发了几个深度网络,这些网络在诸如自
我运动估计、深度回归、3D重建和映射等问题虽然传统方法在某些
情况下可能仍然具有更好的绝对准确性,但这些网络在速度和鲁棒性
方面具有非常有趣的特性。此外,它们适用于诸如传统方法不能使用
的单细胞重建的情况。
运动恢复结构问题的一个特别有趣的方面是,它可以用于引导深
度神经网络,而无需使用人工监督。最近的几篇论文已经表明,实际
上可以仅通过观看来自移动相机(SfMLEarner [1])或立体相机对
(MonoDepth [2])的视频来学习用于自我运动和单目深度估计的这些
方法主要依赖于低级别的线索,如亮度恒定性,只有温和的假设上的
相机运动。这是特别
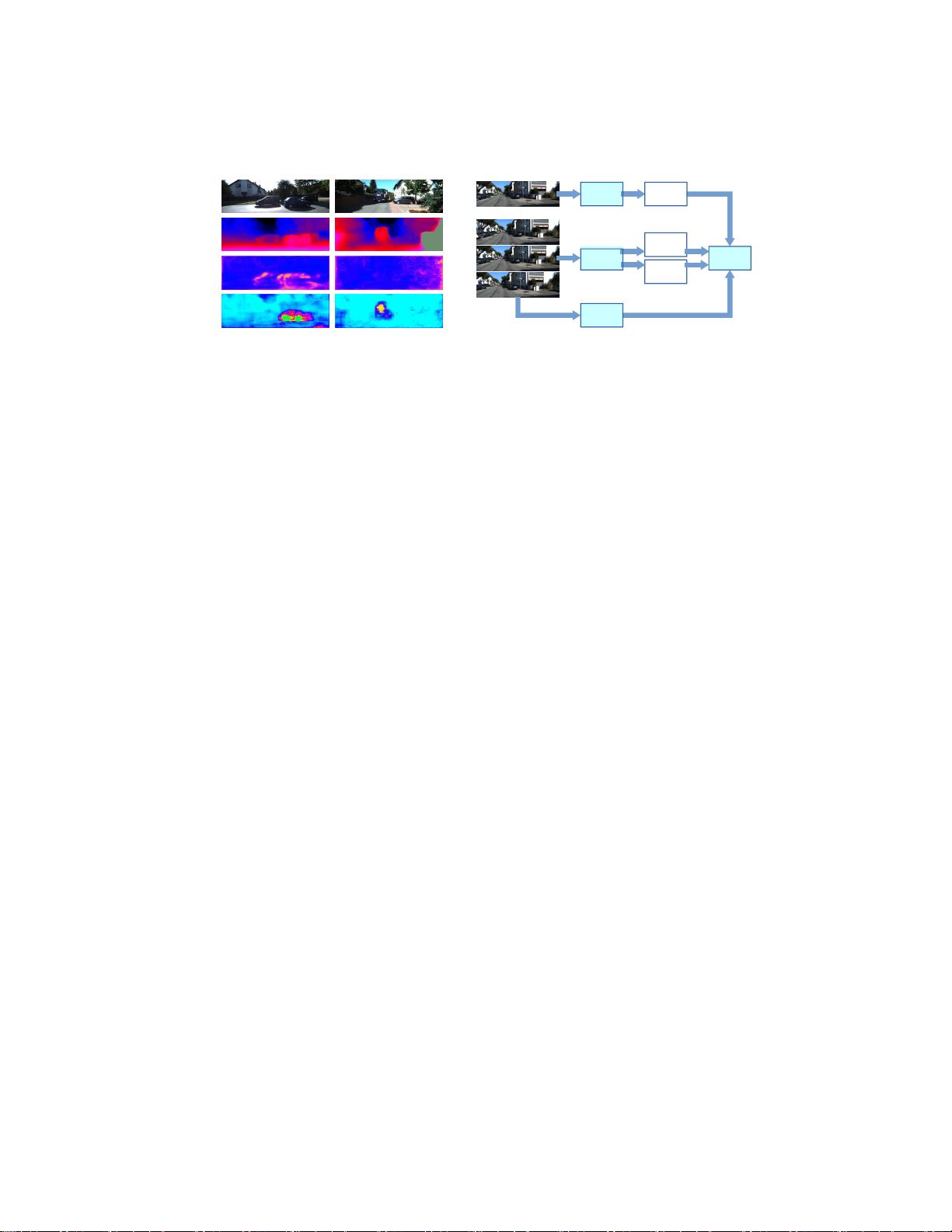


剩余15页未读,继续阅读
342 浏览量
622 浏览量
353 浏览量
2025-01-22 上传
106 浏览量
187 浏览量
150 浏览量
287 浏览量
142 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机组成原理期末试题及答案(2011参考)
- 均值漂移算法深入解析及实践应用
- 掌握npm与yarn在React和pg库中的使用
- C++开发学生信息管理系统实现多功能查询
- 深入解析SIMATIC NET OPC服务器与PLC的S7连接技术
- 离心式水泵原理与Matlab仿真教程
- 实现JS星级评论打分与滑动提示效果
- VB.NET图书馆管理系统源码及程序发布
- C#实现程序A监控与自动启动机制
- 构建简易Android拨号功能的应用开发教程
- HTML技术在在线杂志中的应用
- 网页开发中的实用树形菜单插件应用
- 高压水清洗技术在储罐维修中的关键应用
- 流量计校正方法及操作指南
- WinCE系统下SD卡磁盘性能测试工具及代码解析
- ASP.NET学生管理系统的源码与数据库教程
