深度学习方向感知特征:非刚性形状匹配的新突破
PDF格式 | 2.16MB |
更新于2025-01-16
| 79 浏览量 | 举报
深度方向感知功能地图(DUO-FM)是一种创新的深度学习方法,针对非刚性形状匹配问题提供了一种解决方案。传统的全内在网络在处理形状内部对称性时存在歧义,而功能图框架通过复杂功能图实现了方向保持,使用向量场转移的功能表示来强制保持形状的方向一致性。DUO-FM的核心在于结合了DiffusionNet架构,这是一种对离散化变化具有鲁棒性的模型,同时引入了基于矢量场的损失,无需依赖外部不稳定描述符,能够实现无监督下的方向感知特征学习。
该方法首先回顾了非刚性形状对应学习的重要性,它在3D形状分析中扮演着关键角色,包括统计形状分析和变形纹理转移等领域。早期的方法主要侧重于特征描述符的学习,如[26],或者通过预测每个点的对应顶点ID,如[28, 31, 37, 51]。然而,这些方法缺乏一致性,并可能受到形状离散化的敏感性影响。
近期的技术发展聚焦于整体地图谱预测,特别是函数映射表示,它们利用谱特征将映射转换为小矩阵,显著推动了这一领域的发展。关键在于学习特征函数并应用于整体预测,这种方法降低了对监督数据的需求,提供更强的正则化,使特征对离散化变化更为稳健,并且在存在固定模板形状的情况下简化了预测过程。
DUO-FM的独特之处在于其完全无监督的学习环境,通过估计描述符的梯度,确保源和目标形状在功能上保持一致。这种设计不仅提高了匹配的精度,而且减少了对大量标注数据的依赖,对于实际应用具有显著优势。此外,该方法的源代码已公开在GitHub上,方便研究人员和开发者进行进一步的研究和实践。
总结来说,深度方向感知功能地图为解决非刚性形状匹配问题提供了一个强大的工具,通过结合方向感知、鲁棒的离散化处理和无监督学习,为3D形状分析领域的研究者和实践者带来了突破性的进展。
742
深度方向感知功能地图:解决形状匹配
尼古拉斯
·
多纳蒂
LIX
,
E'cole Polytechnique
nicolas. polytechnique.edu
Etienne
Corman
CNRS
,
Inria
Etienne. cnrs.fr
Maks
Ovsjanikov
LIX,
E'colePolytechnique
maks@lix.polytechnique.fr
摘要
用于非刚性形状匹配的最先进的全内在网络无法消
除形状内部对称性之间的歧义。同时,功能图框架中
的最新进展允许通过所谓的复杂功能图,使用用于切
向量场转移的功能表示来强制方向保持。使用这种表
示,我们提出了一种新的深度学习方法,在完全不受
监督的环境中学习方向感知特征。我们的架构是建立
在
DiffusionNet
上的,这使得我们的方法对离散化变化
具有鲁棒性,同时添加了基于矢量场的损失,这可以
在不使用(通常不稳定的)外部描述符的情况下促进
我们的源代码可以在:
https
:
//github.com/nicolasdonati/DUO-FM
网站。
1.
介绍
非刚性形状对应的学习是3D形状分析中的一个关键
问题,其应用范围从统计形状分析[6,36]到变形或纹
理转移[4]。早期的方法集中于学习信息特征,使得对
应的点具有相似的特征描述符,例如,[26],或者将
形状对应建模为语义分割问题。后一类别中的方法,
例如,[28,31,37,51]旨在为表面上的每个点预测
一些地面实况模板形状上的对应顶点id。不幸的是,
这两种方法在单个点对应预测之间几乎没有一致性,
同时可能对潜在的形状离散化敏感[43]。
最近,技术集中在预测和对每对形状之间的整个
地
图
谱方法,特别是函数映射表示[ 33 ],极大地促进了
这一点,函数映射表示[ 33 ]使用谱(拉普拉斯)特征
基将映射编码为小矩阵。广泛的
图
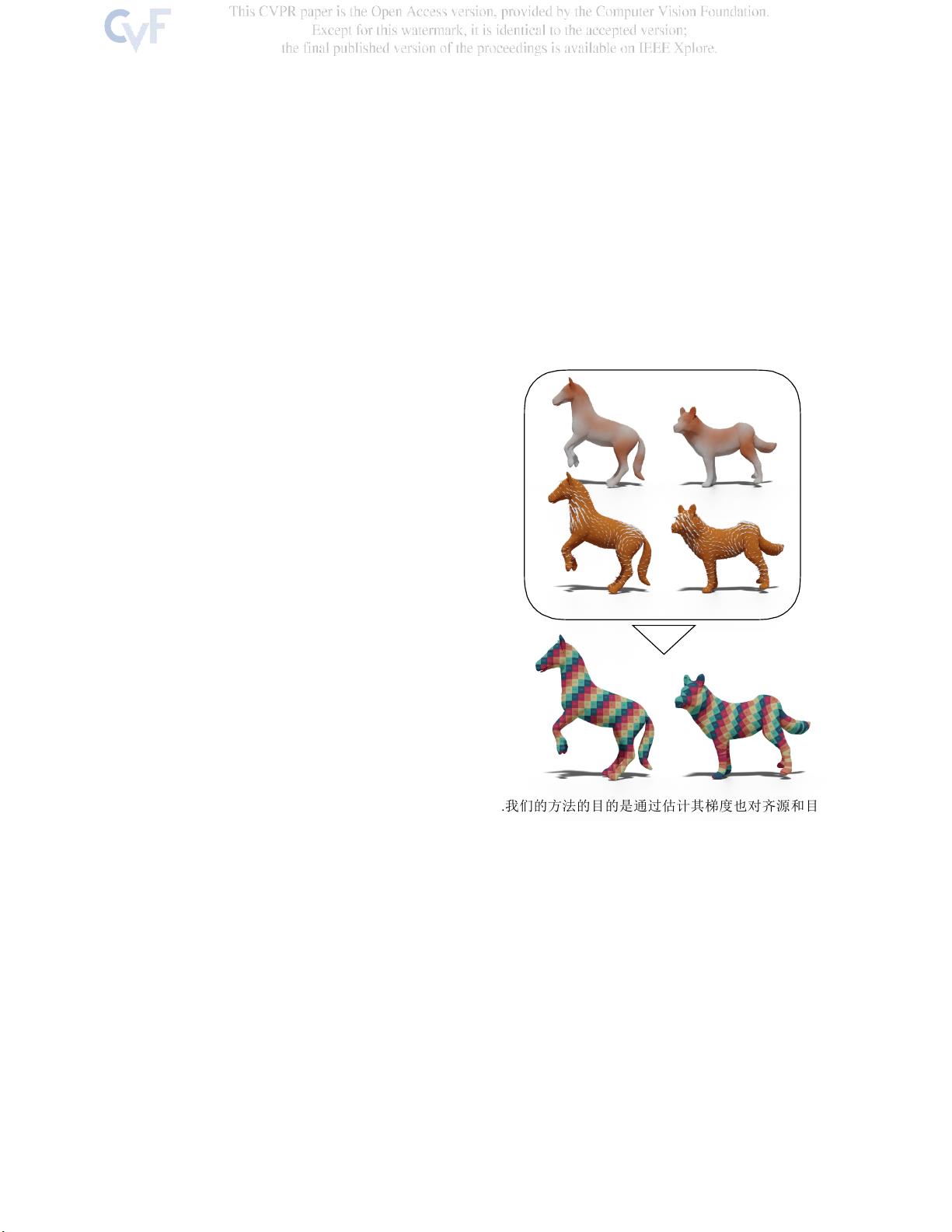
1.
我们的方法的目的是通过估计其梯度也对齐源和目标形
状的描述符,在一个完全无监督的设置中产生
方向保持
基于监督损失[9,13,23]和非监督损失[22,40]的方
法已经使用函数图表示提出所有这些方法的关键是学
习特征函数,然后将其用于
整体
预测功能图。正如多
个 最 近 的 工 作 所 示 , 这 减 少 了 必 要 的 训 练 数 据 量
[13],提供了强正则化促进平滑映射,使学习的特征
对离散化的变化具有鲁棒性[43],并简化了存在固定
模板形状的要求。
标量向量值描述子
方位感知通信
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐






cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现程序A的监控启动机制
- Delphi与C#交互加密解密技术实现与源码分析
- 高效财务发票管理软件
- VC6.0编程实现删除磁盘空白文件夹工具
- w5x00-master.zip压缩包解析:W5200/W5500系列Linux驱动程序
- 数字通信经典教材第五版及其答案分享
- Extjs多表头设计与实现技巧
- VBA压缩包子技术未来展望
- 精选多类型导航菜单,总有您钟爱的一款
- 局域网聊天新途径:Android平台UDP技术实现
- 深入浅出神经网络模式识别与实践教程
- Junit测试实例分享:纯Java与SSH框架案例
- jquery xslider插件实现图片的流畅自动及按钮控制滚动
- MVC架构下的图书馆管理系统开发指南
- 里昂理工学院RecruteSup项目:第5年实践与Java技术整合
- iOS 13.2真机调试包使用指南及安装
