硬感知深度度量学习:挖掘全部样本信息的新框架
PDF格式 | 1.76MB |
更新于2025-01-16
| 86 浏览量 | 举报
"硬感知深度度量学习框架是针对深度度量学习中的一种新方法,旨在优化数据嵌入,提高样本间的相似性度量。该框架通过线性插值和标签合成策略,解决传统深度度量学习方法中训练样本不足的问题,从而充分利用所有样本信息,提升度量的挑战性和准确性。在CUB-200-2011、Cars196和StanfordOnlineProducts等数据集上,该方法展现出优秀的性能。"
深度度量学习是机器学习领域的一个重要分支,其目标是学习一个映射,将原始数据转换到一个特征空间,使得在这个空间中,相似的数据点之间的距离更小,不相似的数据点之间的距离更大。深度神经网络常被用作构建这个映射,因为它能学习到复杂的非线性特征表示。
传统的深度度量学习方法通常依赖于“硬否定挖掘”策略,这种方法只选取部分训练样本进行处理,可能导致丢失全局嵌入空间的几何信息。为解决这一问题,硬感知深度度量学习(HDML)框架引入了线性插值。线性插值用于调整样本的“硬水平”,即样本所属类别间的距离,以此生成新的合成样本。这些合成样本保留了原始标签,同时通过调整它们的“硬度”(类间距离),能够更好地反映全局嵌入空间的结构。
此外,HDML框架还利用了一个标签合成器,它能够在保持原有标签不变的情况下,生成新的训练样本,这有助于再循环训练,确保所有样本的信息都被充分挖掘。这种自适应的硬度控制策略不会改变同一类别内样本的距离,确保了类内的紧密度,同时增加了类间的区分度。
这种方法对于图像检索、行人重识别和地理定位等任务具有显著优势。通过在多个基准数据集上的实验,硬感知深度度量学习证明了其在提升模型性能和泛化能力方面的优越性,为深度度量学习提供了新的思路和方法。
硬感知深度度量学习框架是一种创新性的深度学习技术,它通过改进样本处理方式,增强了度量学习的效果,尤其是在处理有限样本和复杂数据分布时。这一框架的应用和研究将有助于推动深度学习在图像识别、模式匹配和相关领域的进步。
74
H
0
7UDiQiQJ
larity关系。通过最小化特定损失函数来学习网络参数
θ
*
=
arg min
θ
h
J
(
θ
h
;{
Ti
}
)
。
(三
)
公司简介
图
2.
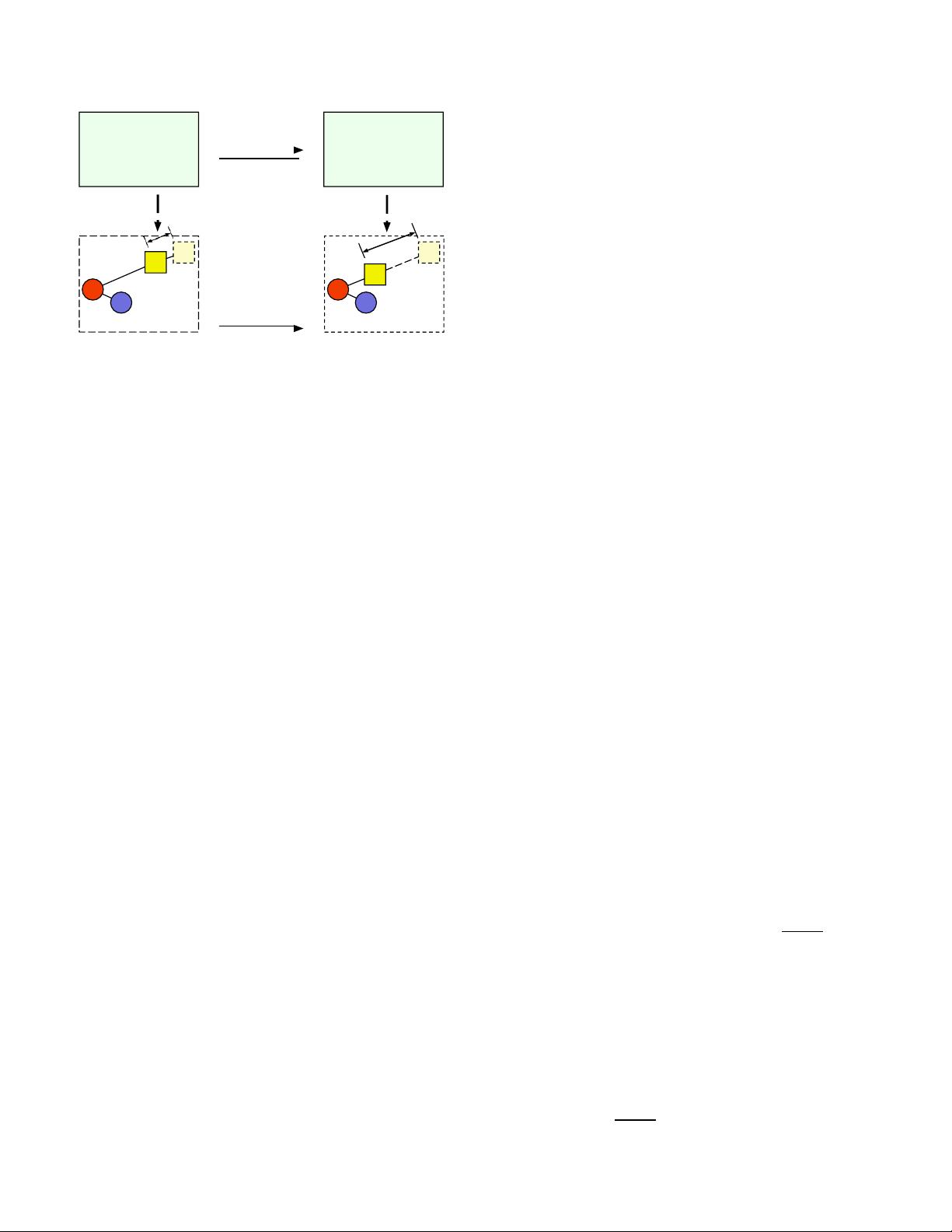
所提出的硬度感知增强的图示。具有相同形状的点来自
同一类。我们对嵌入空间中的负对进行线性插值,以获得更
硬的元组,其中硬级别由模型的训练状态控制随着训练的进
行,越来越难的元组被生成以更有效地训练度量(Best以颜色
查看)。
3.1.
问题公式化
令X 表 示数据空 间,其中 我们对一 组 数 据点
X
=
[x
1
,
x
2
,
···
,
x
N
]
进行采样。每个点
x
i
具有标
签
l
i
∈
{1
,
···
,
C
}
,其构成标签集
L
=
例如,三重丢失[25]样本三重态由三个例子组成,
锚x,与锚具有相同标记的正x
+
,以及具有不同标记的
负
x
−
三重态的损失迫使
锚点和负电极之间的距离比锚点和正电极之间的距离
大固定的余量。
此外,N-pair Loss [28]对具有不同类别的
N
个
正对的
元组进行采样,并试图将
N-1
个负对一起推开。
3.2.
硬度感知增强
在训练过程中可能存在大量可以使用的元组,但它
们中的绝大多数实际上缺乏直接信息,并且产生近似
为零的梯度。为了只在信息性的元组中进行选择,我
们将自己限制在一个小的元组集合中。然而,这个小
集合可能无法准确地表征嵌入空间的全局为了解决上
述局限性,我们提出了一种自适应
X
f
Y
硬度感知增强方法,如图所示
[
11
,
12
,
···
,
1N
]
。设
f
:
X
−
→Y
是来自数据的映射
空间到特征空间,其中提取的特征
yi
具有其对应的数据
点xi的语义特征
。
度量学习的目标是学习距离度量
在特征空间中,它可以反映实际的语义距离。距离度
量可以定义为:
D
(
xi
,
x
j
)
=
m
(
θ
m
;
yi
,
y
j
)
=
m
(
θ
m
;
f
(
xi
)
,
f
(
x
j
))
,
(
1
)
其中
m
是一致正对称函数,
θ
m
为相应参数。
深度学习方法通常使用深度神经网络提取特征。标
准的过程是首先将特征投影到嵌入空间(或度量空
间)
Z
中
G
映射
g
:Y
−
→
Z
,其中距离度量为
二、我们在嵌入空间中修改和构造了具有硬度感知的
元组,其中对样本之间的距离的操纵将直接改变元组
的硬度水平。负对之间距离的减小将导致硬电平的上
升,反之亦然。
给定一个集合,我们通常可以形成比正对更多的负
对,所以为了简单起见,我们只操纵负对的距离。对
于元组中的其他样本,我们不
执行变换,即,
z
=
z
。尽
管如此,我们的模型可以
很容易地扩展到处理正对。
在获得负对(锚z和
a negative
z
−
),我们构造一个增广的更硬的负
通过线性插值采样
然后是简单的欧几里得距离。由于投影可以并入深度
网络,我们可以直接学习
z
−
=
z
+
λ
(z
−
−
z)
,
λ
∈[0
,
1]. (四)
a
映射
h
=
g
<$
f
:
X
−
→
h
Z
从数据空间到
嵌入空间,这样
就可以训练整个模型
然而,太靠近锚点的例子很可能共享标签,因此不再
构成负对。
端到端,无需显式特征提取。 在这种情况下,
因此,设置λ
0
更为合理
D
+
d
(z
,
z
−
)
,
1]
,
距离度量被定义为:
D
(x
i
,
x
j
)=
d
(z
i
,
z
j
)=
d
(
θ
h
;
h
(x
i
)
,
h
(x
j
))
,
(
2)
其中
d
表示欧几里得距离
d
(
z
i
,
z
j
)
=
||z
i
−
z
j
||
2
,
z
=
g
(
y
)
=
h
(
x
)
是
学习
的嵌入,
θ
f
,
θ
g
其中d
+
是我们用来确定
操纵的规模(例如,正对或固定值之间的距离),且d
(
z
,
z
−
)
=
||z
−
−z||
二
、为了实现这一点,我们引入一
个变量
λ∈
(
0
,
1]
,
.
和
θ
h
分别
是映射
f
,
g
和
h
的参数
D
+
d
(z
,
z
−
)
,如果
d
(
z
,
z
−
)
> d
+
(五)
&联系我们
N
e
一
P
N
度量
&联系我们
N
e
一
P
N
度量
(
0
λ
+
(
1−
λ
)
剩余10页未读,继续阅读
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 支付宝订单监控免签工具:实时监控与信息通知
- 一键永久删除QQ空间说说的绿色软件
- Appleseeds训练营第4周JavaScript练习
- 免费HTML转CHM工具:将网页文档化简成章
- 奇热剧集站SEO优化模板下载
- Python xlrd库:实用指南与Excel文件读取
- Genegraph:通过GraphQL API使用Apache Jena展示RDF基因数据
- CRRedist2008与CRRedist2005压缩包文件对比分析
- SDB交流伺服驱动系统选型指南与性能解析
- Android平台简易PDF阅读器的实现与应用
- Mybatis实现数据库物理分页的插件源码解析
- Docker Swarm实例解析与操作指南
- iOS平台GTMBase64文件的使用及解密
- 实现jQuery自定义右键菜单的代码示例
- PDF处理必备:掌握pdfbox与fontbox jar包
- Java推箱子游戏完整源代码分享
