从视频中学习对象的声音:共同分离训练目标下的音频源分离
25 浏览量
更新于2025-01-16
收藏 2.33MB PDF 举报

1
视觉对象
高若涵UT
奥斯汀
rhgao@cs.utexas.edu
克里斯汀·格劳曼
UT Austin和Facebook AI Research
grauman@cs.utexas.edu
摘要
从视频中学习对象的声音是具有挑战性的,因为它
们通常在单个音频通道中严重重叠。用于视觉引导的
音频源分离的当前方法通过利用人工混合的视频剪辑
进行训练来回避该问题,但是这对训练数据收集施加
了笨拙的限制,并且甚至可能阻止学习
“
真实
”
混合声
音的特性。我们引入了一个
共同分离的
训练范式,允
许学习对象级的声音从未标记的多源视频。我们的新
训练目标要求深度神经网络的我们的方法在真实的测
试视频中解开声音,即使在训练过程中没有单独观察
到物体的情况下。我们获得了
MUSIC
、
AudioSet
和
AV-
Bench
数据集的视觉引导音频源分离和音频去噪
1.
介绍
多模态感知对于捕获对象、场景和事件的真实世界
感官数据的丰富性是重要的。物体发出的声音,无论
是主动产生的还是偶然发出的,都提供了关于它们的
物理特性和空间位置的有价值的信号--钹在舞台上碰
撞,鸟在树上鸣叫,卡车在街区里加速,银器在抽屉
里叮当作响。
物体通常在与周围其他物体共存或相互作用时产生
声音。因此,我们不是孤立地观察它们,而是听到它
们与来自其他来源的声音交织在一起。同样,真实的
视频记录了具有单个音频通道的各种对象,该单个音
频通道将它们的所有声学频率混合在一起。自动
分离
视频中每个对象的声音具有很大的实际意义,其应用
包括音频去噪、视听视频索引、乐器均衡、音频事件
混音和对话跟随。
而传统的方法假设访问多个
一致可识别的
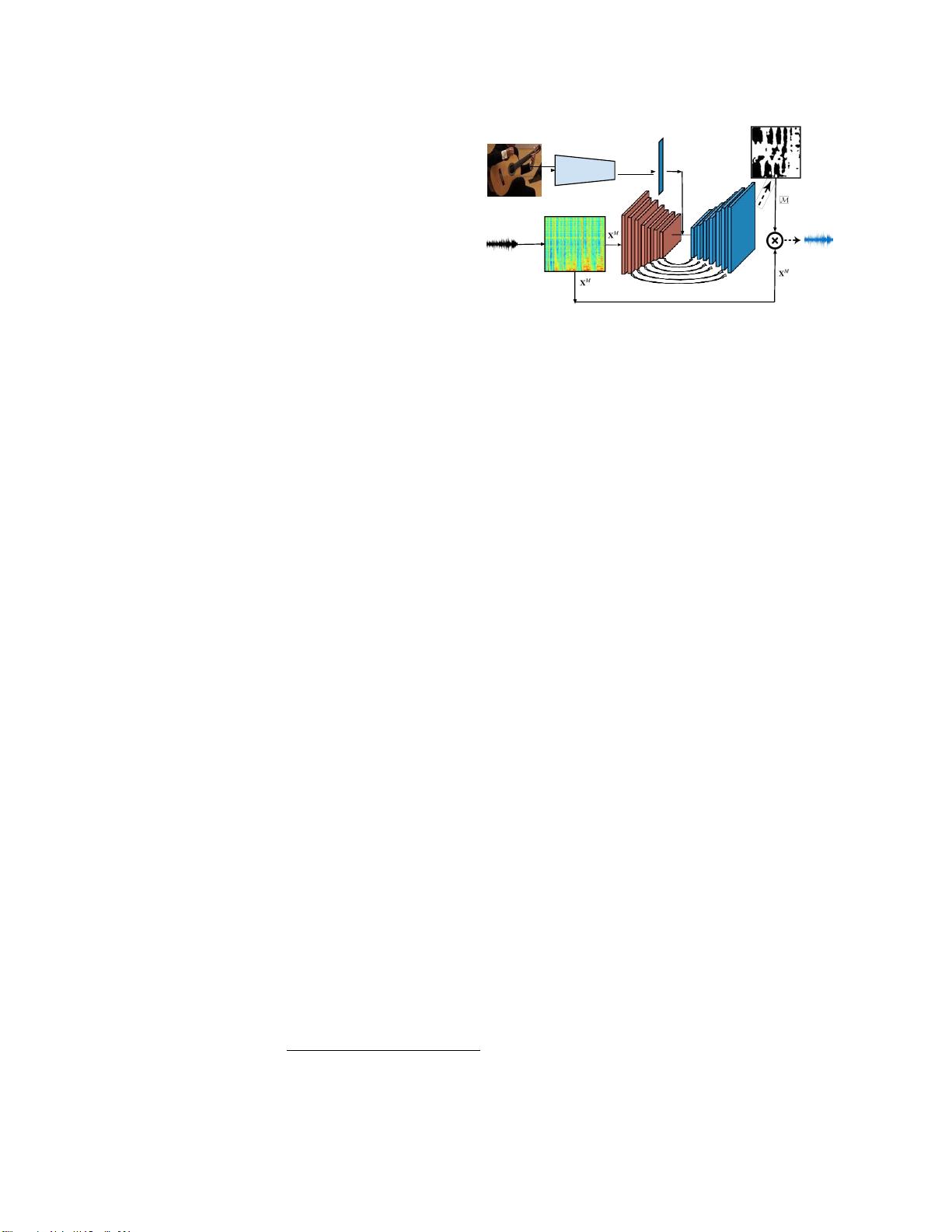
图1:我们提出了一个
共同分离
训练目标,用于从包含多个
声源的未标记视频中学习音频源分离我们的方法学习将一致
的声音与成对的训练视频中相似的对象相关联。然后,给定
一个新颖的视频,它为每个对象返回一个单独的音轨。图片
来源:
[1
,
2]
中所述。
麦克风或仔细监督的干净音频样本[22,48,9],最近
的方法使用“混合和分离”范例来解决音频(视觉)源
分离问题也就是说,这种方法随机地混合音频/视频片
段,并且学习目标是恢复原始的未混合信号。例如,
人们可以创建
目前的培训战略有两个主要限制。首先,它隐含地
假设原始真实训练视频由包含一个主要声音制造者的
单源剪辑主导。然而,收集大量这种干净的
3879
大提
琴
吉他
小提
琴
吉他

剩余11页未读,继续阅读
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 支付宝订单监控免签工具:实时监控与信息通知
- 一键永久删除QQ空间说说的绿色软件
- Appleseeds训练营第4周JavaScript练习
- 免费HTML转CHM工具:将网页文档化简成章
- 奇热剧集站SEO优化模板下载
- Python xlrd库:实用指南与Excel文件读取
- Genegraph:通过GraphQL API使用Apache Jena展示RDF基因数据
- CRRedist2008与CRRedist2005压缩包文件对比分析
- SDB交流伺服驱动系统选型指南与性能解析
- Android平台简易PDF阅读器的实现与应用
- Mybatis实现数据库物理分页的插件源码解析
- Docker Swarm实例解析与操作指南
- iOS平台GTMBase64文件的使用及解密
- 实现jQuery自定义右键菜单的代码示例
- PDF处理必备:掌握pdfbox与fontbox jar包
- Java推箱子游戏完整源代码分享
