深度学习与连续广义零次学习:动态适应新类的框架
124 浏览量
更新于2025-01-16
收藏 1.96MB PDF 举报
"这篇论文探讨了有限监督学习的最新发展,特别是关注连续广义零次学习(Continuous Generalized Zero-Shot Learning, CGSRL)和在线设置。在这些环境中,模型需要在没有大量标记数据的情况下适应新类别的出现。文章介绍了深度神经网络(DNNs)在计算机视觉应用中的广泛使用,但也指出了它们对大规模标记数据的依赖限制了其在现实世界中的应用。现实世界的数据分布往往遵循长尾分布,导致部分类别难以获取充分的标注样本。"
1. 知识点解析
(1) 有限监督学习:有限监督学习是指在有限的标记样本下训练模型,目标是让模型能够泛化到未见过的样本或类别。在这种情况下,模型必须学会从少量示例中学习抽象特征。
(2) 广义零次学习(Generalized Zero-Shot Learning, GSTOL):在GSTOL中,模型在训练时并未接触过所有类别的数据,但在测试时需要识别新类别。这通常通过利用类别之间的先验知识(如属性或语义关系)来实现。
(3) 连续广义零次学习(Continuous Generalized Zero-Shot Learning, CGSRL):CGSRL扩展了GSTOL,允许模型在运行过程中不断适应新的可见和不可见类别,这更符合实际场景,其中新类别可能会不断出现。
(4) 在线学习:在线学习是一种动态学习方式,模型在接收新数据时不断更新,无需重新训练整个数据集。这对于处理连续流式数据和适应新类别至关重要。
(5) 灾难性遗忘:当模型在学习新任务时忘记旧任务,称为灾难性遗忘。这是在线学习和终身学习中的一个挑战,因为它会导致模型的泛化性能下降。
(6) 双向增量对齐:为了克服灾难性遗忘和适应新类别,论文提出了一种统一的特征生成框架——CGCARL,利用双向增量对齐方法,使模型能够在不丢失已有类别知识的同时,有效学习新类别的特征。
(7) 基准数据集:论文通过在五个基准数据集上进行实验,评估了提出的CGCARL方法的效果,这表明其在CGSRL和更实用的在线设置上都优于现有方法。
2. 技术应用
深度神经网络在计算机视觉任务中广泛应用,但对大量标记数据的依赖限制了它们在现实世界中的有效性。CGSRL和在线学习的研究旨在解决这个问题,使模型能够处理现实世界的动态变化。CGCARL框架提供了一种灵活且适应性强的方法,它能够在新类别出现时动态调整,且不受标记数据的限制。
3. 结论
该研究对于有限监督学习领域具有重要意义,它推动了模型在实际场景中的应用,尤其是在新类别不断出现的情况下。提出的CGCARL框架为解决连续广义零次学习中的挑战提供了一种实用的解决方案,有助于提升模型的泛化能力和适应性。
9247
不
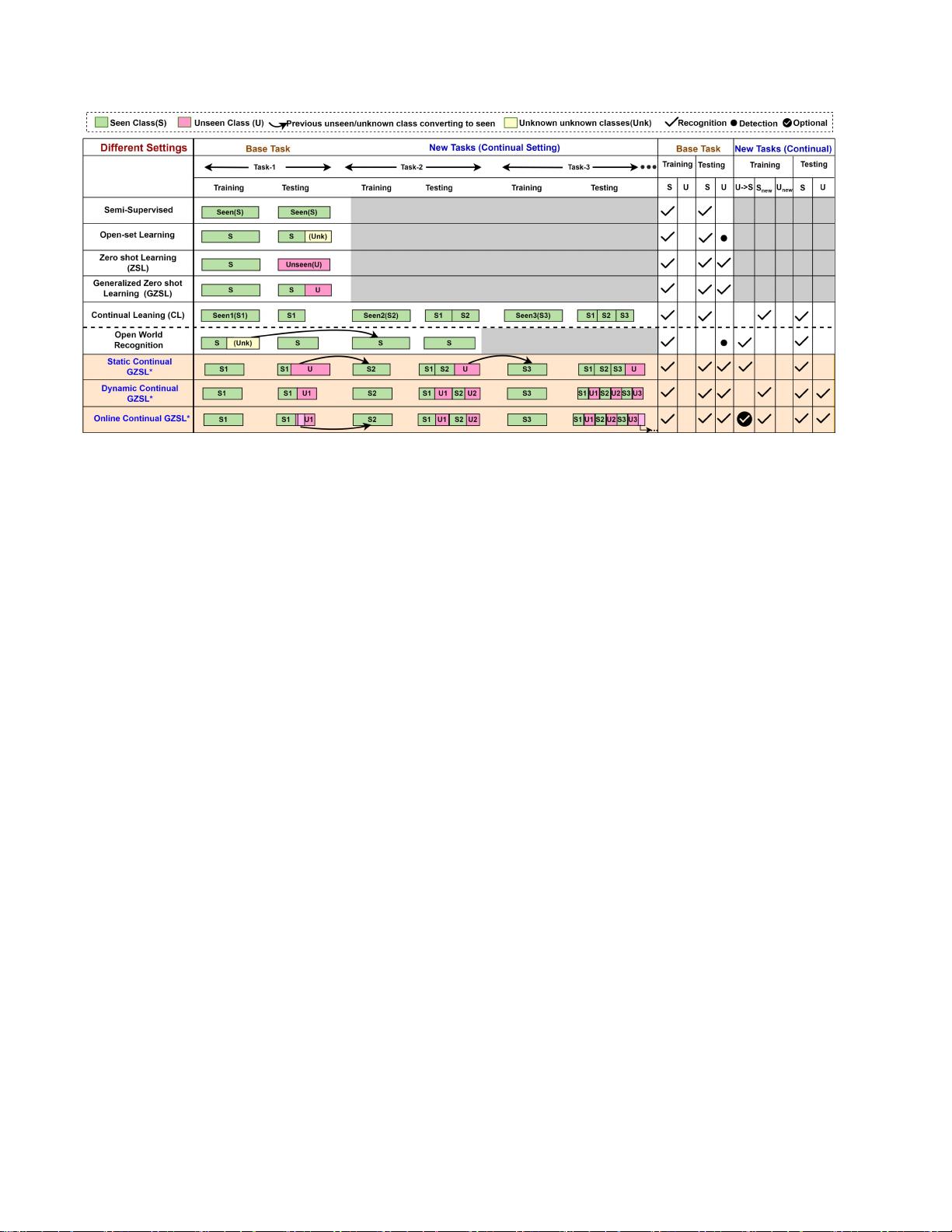
图
2. 建议设置与其他已知设置的比较。在CNOL中,模型在可见的类上进行训练,并在不可见的类上进行评估。在GALML中,模型在可见和
不可见的类上进行测试。CL模型在顺序到达的类上进行训练,但在训练或测试期间没有看不见的类。在这项工作中,提出了连续的GHEL
(CGHEL)设置(用 * 突出显示)。在static-CGRML中,将来到达的类被认为是不可见的。在Dynamic-CGRML中,每个任务都有一组不相交
的可见类和不可见Online-CGRQL允许将以前看不见的类转换为可见的类(基于数据的可用性),此外还可以在每个任务中处理新的可见和不
可见类
在实践中具有限制性的设置(第二节)(3)第三章。
[6,7]最近制定的CGRQL作为一个问题,其中每个任
务 都 有 自 己 的 一 组 可见和 不 可 见 的 类 , 并 在
动 态
CGRQL设置中工作。虽然此设置是对
静态
CGRQL设置
的改进,但它仍然是限制性的,因为它不允许在数据
随着时间的推移变得可用时动态转换看不见的类。此
外,为每个任务学习新的VAE [9]或存储先前任务的示
例样本[7]会导致内存需求逐渐增加,这是低效的。另
一方面,[6]采用了一种基于排练的策略,但没有考虑
到随着时间的推移,由于新类别的增加,视觉空间
3.
CGCARL:设置和公式
在 本 节 中, 我 们 将 对 最 近 的 努力所 处 理 的 各 种
CGGML设置进行整合和提供全面的概述,并详细讨论
其制定中的主要差异。我们还描述了我们提出的
在线
CGCQL设置,它更灵活,更接近真实世界的场景。图
2示出了各种CGRQL设置的图形表示,并努力将它们
与相对于其他相关的有限监督和持续学习环境。我们
现在在下面描述每个CGRQL设置变体
静态-CGAXL。在这种设置中[8,9,26,29],数据集
被划分为T个子集,模型随着时间的推移以增量方式遇
到每个子集。该设置假定所有以前遇到的任务都是可
见的,而将来的任务由不可见的类组成。形式上,对
于A
在给定的时间步
t
,给定任务
t
,前
t
个子集,即属于当
前和先前任务的数据被认为是可见类,而未来任务
被认为是不可见的。这种设置与传统的
GSTML
不
同,因为在
第
t
任务的评估期间,先前的训练数据不可
用。因此,模型应该能够保留以前学习的知识,同
时适应新
遇到的seen类。然而,static-CGRQL提供
了一
个受约束的设置,它需要预先知道类或任务的总数
(因此称为
static
)。此外,该设置要求直到当前时
间步
t
的所有任务都被认为是可见类,只有未来任务
包含不可见类。因此,类的动态添加仅限于在连续学
习的同时遇到特定任务后将不可见类转换为可见
类。
虽然假设
看不见的类别的视觉特征在未来可能变得可用
是合理的,但假设在训练开始时未知的新的可见或不
可见类别在未来将不被添加可能是不可行的。这从根
本上限制了持续学习的概念,模型应该适应
-
能够完成任意数量的任务或添加新类。
动态-CGCGL 。考虑到
静态
CGRQL设置的局限性,
[6,7]提出了另一种设置,其中每个任务都有一组唯
一的可见和不可见类,并且模型可以随时间推移容纳
任何数量的任务我们将此设置归类为动态CGRQL,其
限制性低于
静态
CGRQL设置,因为它允许以连续的方
式添加可见和不可见的类。然而,此设置强加了一个
约束,
剩余11页未读,继续阅读
基于MATLAB的广义连续函数碰撞检测框架下的无人机运动规划:详细解析与学习参考,广义连续函数碰撞检测框架(CCD)的无人机运动规划 基于MATLAB建立广义连续函数碰撞检测框架(CCD)的无人机运动
2025-02-09 上传
125 浏览量
1389 浏览量
1492 浏览量
280 浏览量
286 浏览量
点击了解资源详情
386 浏览量
点击了解资源详情

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易酷免费影视系统:开源网站代码与简易后台管理
- Coursera美国人口普查数据集及使用指南解析
- 德加拉6800卡监控:性能评测与使用指南
- 深度解析OFDM关键技术及其在通信中的应用
- 适用于Windows7 64位和CAD2008的truetable工具
- WM9714声卡与DW9000网卡数据手册解析
- Sqoop 1.99.3版本Hadoop 2.0.0环境配置指南
- 《Super Spicy Gun Game》游戏开发资料库:Unity 2019.4.18f1
- 精易会员浏览器:小尺寸多功能抓包工具
- MySQL安装与故障排除及代码编写全攻略
- C#与SQL2000实现的银行储蓄管理系统开发教程
- 解决Windows下Pthread.dll缺失问题的方法
- I386文件深度解析与oki5530驱动应用
- PCB涂覆OSP工艺应用技术资源下载
- 三菱PLC自动调试台程序实例解析
- 解决OpenCV 3.1编译难题:配置必要的库文件
