带类别转移的弱监督目标检测
PDF格式 | 805KB |
更新于2025-01-16
| 174 浏览量 | 举报
3070
CaT:带类别转移的弱监督目标检测
曹天跃
1
杜
连宇
1
张 晓云
1
* 陈
思恒
1
,
2
张雅
1
,
2
王
艳峰
1
,
2
上海交通
大学合作媒体创新中心
1
上海人工智能实验室
2
{
vanessa,dulianyu,xiaoyun.zhang,sihengc,ya zhang,wangyanfeng
}
@ sjtu.edu.cn
摘要
在全监督对象检测和弱监督对象检测之间存在很大
的差距。为了缩小这一差距,一些方法考虑从附加的
全监督数据集转移知识。但是这些方法没有充分利用
全监督数据集中的判别类别信息,从而导致低
mAP
。
为了解决这个问题,我们提出了一种新的类别转移框
架弱监督对象检测。直觉是充分利用完全监督数据集
中的视觉区分和语义相关类别信息,以增强对象分类
能力。
弱监督数据集
双监督平均教师网络
语义图
卷积网络
弱监督检测器的性能。为了处理重叠的类别转移,我
们提出了一个双监督平均教师收集共同的类别信息和
桥梁之间的领域差距两个数据集。为了处理非重叠类
别转移,我们提出了一个语义图卷积网络,以促进相
关类别之间的语义特征的聚合实验以
Pascal VOC 2007
为目标弱监督数据集,
COCO
为源全监督数据集。我
们 的 类 别 转 移 框 架 实 现 了
63.5%
的
mAP
和
80.3%
的
CorLoc
,两个数据集之间有
5
个代码可在
https
:
//github.com/MediaBrain-SJTU/CaT
网站。
1.
介绍
目标检测是计算机视觉中最基本的任务之一[44]。
在过去的十年中,基于深度神经网络,许多方法[16,
26,27]取得了巨大的成功。然而,大多数方法都遵循
完全监督的设置,这需要大量的高质量注释,包括对
象的精确边界框及其相应的类别标签。这一套-
*
张晓云为通讯作者。
本工作得到了国家重点研发计划(2019YFB1804304)、国家自
然科学基金(61771306)、超高清视音频制作与呈现国家重点实验
室 、 上 海 市 数 字 媒 体 处 理 与 传 输 重 点 实 验 室 ( STCSM
18DZ2270700)和111计划(BP0719010)的部分支持。
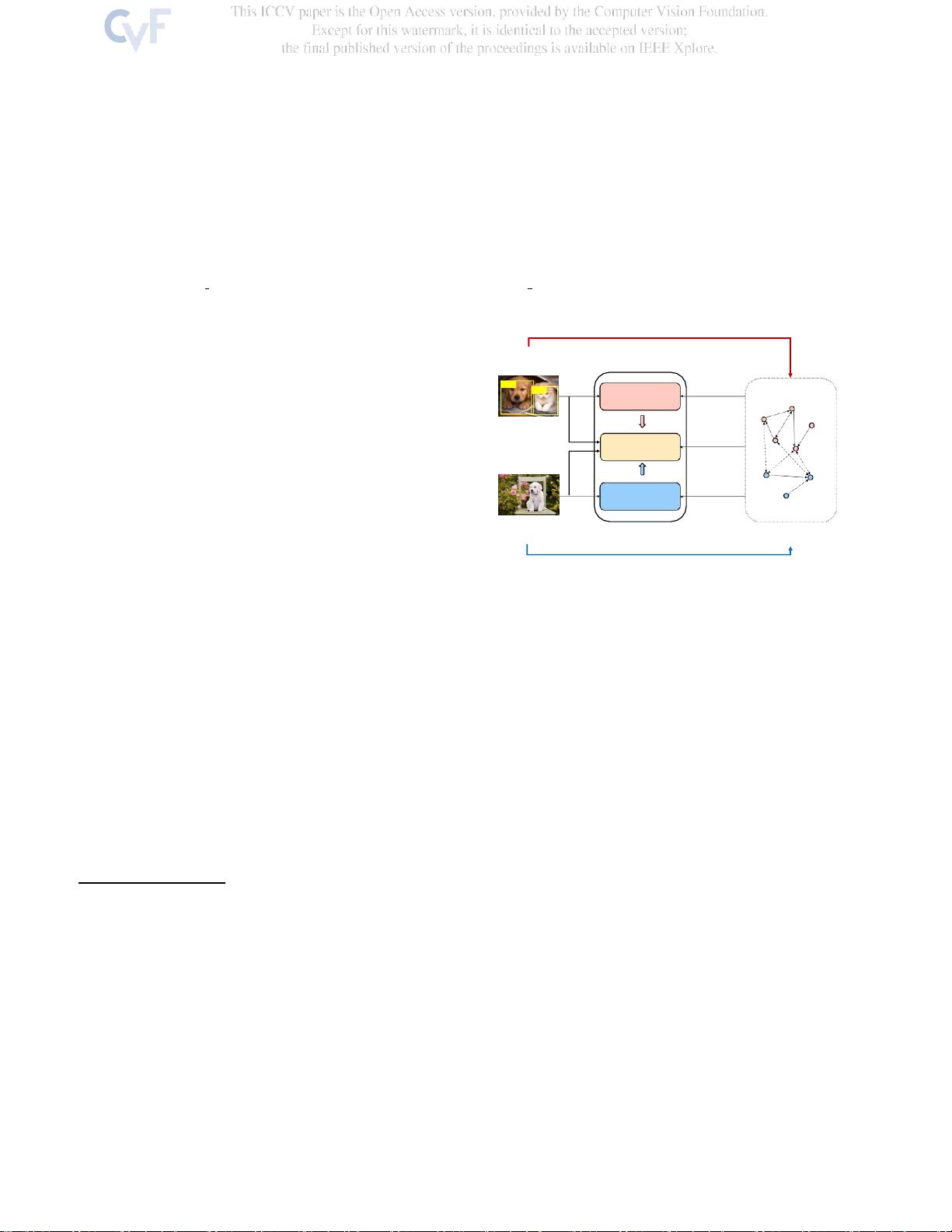
图1.我们的类别转移框架的示意图。我们
利用双监督平均教师网络传递重叠的类别和对象知识
;
并使
用语义图卷积网络来传递非重叠的类别知识。最后的预测是
由教师生成的。
提取通常花费大量的时间和资源来获取这样的注释。
为 了 降 低 注 释 成 本 , 提 出 了 弱 监 督 对 象 检 测
(WSOD)[2,32,33]来训练仅具有图像级类别标签
的检测模型然而,缺乏边界框级别的监督导致重大问
题,如实例歧义和低质量的建议。因此,在全监督对
象检测(89.1% mAP,SOTA [10])和弱监督对象检测
(56.8% mAP,SOTA [13])之间仍然存在很大的性能
差距
为了缩小这一差距,一些以前的方法考虑从额外的
数据的知识转移。主要有两种方法:对象转移方法和
半监督方法。例如,[18,29,43]在源数据上训练通
用对象检测器并将其应用于目标数据;然而,这种对象
传递方法忽略了源数据集中的类别信息,导致分类效
果下降。[11,37,35,15]用部分完全注释的数据遵
循半监督设置,并将图像分类器转换为对象检测器。
这样的半监督方法利用了框和类别信息,但通常不能
解决数据集之间的领域差距,特别是类别不一致性问
题.
全监督数据集
狗
猫
全监督
学生
重叠
范畴迁移
车
狗
猫
教师
儿童
人
分类标签:狗,椅子
非重叠范畴转移
弱监管
学生
狗
椅子
人


剩余10页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebDrive v16.00.4368: 简易易用的Windows风格FTP工具
- FirexKit:Python的FireX库组件
- Labview登录界面设计与主界面跳转实现指南
- ASP.NET JS引用管理器:解决重复问题
- HTML5 canvas绘图技术源代码下载
- 昆仑通态嵌入版ASD操舵仪软件应用解析
- JavaScript实现最小公倍数和最大公约数算法
- C++中实现XML操作类的方法与应用
- 设计编程工具集:材料重量快速计算指南
- Fancybox:Jquery图片轮播幻灯弹窗插件推荐
- Splunk Fitbit:全方位分析您的活动与睡眠数据
- Emoji表情编码资源及数据库查询实现
- JavaScript实现图片编辑:截取、旋转、缩放功能详解
- QNMS系统架构与应用实践
- 微软高薪面试题解析:通向世界500强的挑战
- 绿色全屏大气园林设计企业整站源码与多技术项目资源
