深度模块化协同注意网络:提升可视化问答的性能
PDF格式 | 2.13MB |
更新于2025-01-16
| 78 浏览量 | 举报
"深度模块化协同注意网络在可视化问答中的应用"
本文主要探讨了深度模块化协同注意力网络(MCAN)在视觉问答(VQA)任务中的应用,该任务涉及图像与文本理解,属于多模态学习领域。现有的VQA方法大多依赖于浅层的共同注意模型,而MCAN则提出了一种深度且模块化的解决方案。
深度模块化协同注意力网络(MCAN)由多个模块化协同注意力(MCA)层堆叠而成,每个MCA层包含问题的自我注意和问题引导的图像注意,通过两个基本的注意单元模块化组合。这种设计使得模型能够更深入地理解和关联图像的视觉信息与问题的文本信息。
在VQA-v2数据集上,MCAN进行了定量和定性的评估,以及广泛的消融研究,以揭示其有效性。实验结果显示,MCAN显著优于先前的最先进的方法,其最佳单一模型在测试开发集上的整体准确率达到70.63%。这表明,深度模型在VQA任务中的表现优于浅层模型,尤其是当它们采用模块化设计时,能够更好地捕获和融合多模态信息。
图1展示了不同深度的共同注意力模型在VQA-v2验证集上的精度对比,MCAN在深度增加时性能提升,这与其他仅使用浅层共同注意力模型的方法形成了鲜明对比。值得注意的是,所有比较方法都使用了相同的自下而上的注意力视觉特征表示图像,唯有DCN因使用卷积视觉特征而导致性能较差。
注意力机制在VQA任务中扮演了关键角色,从输入问题中学习并引导对图像区域的视觉注意力。最早由[27]提出的注意力概念已被广泛应用于视觉、语言和语音等单模态任务,以及多模态任务,如VQA。MCAN的创新之处在于将这一机制进一步深化并模块化,从而更有效地处理复杂的视觉与语言交互。
MCAN的提出是多模态学习领域的一个重要进步,它为解决VQA任务提供了一个强大的工具,通过深度和模块化的协同注意力机制,提高了模型的理解能力和预测准确性。这一成果不仅对于VQA任务有直接的应用价值,也为其他涉及图像和文本理解的多模态任务提供了新的研究思路。
6283
添加
LayerNorm
前馈
添加LayerNorm
多头注意力
K V Q
添加图层规范
前馈
添加LayerNorm
多头注意力
K V Q
Y
X
∈
∈
∈
∈
∈
∈
∈
∈
∈
J
J
J
√
j
jj
Z
Z
(a)
ID
(
Y
)
-GA
(
X
,
Y
)
(b)
SA(Y)-GA
(
X
,
Y
)
(c)
SA
(
Y
)
-SGA
(
X
,
Y)
X
(a)
自我注意(
SA
)
(
b
)引导注意(
GA
)
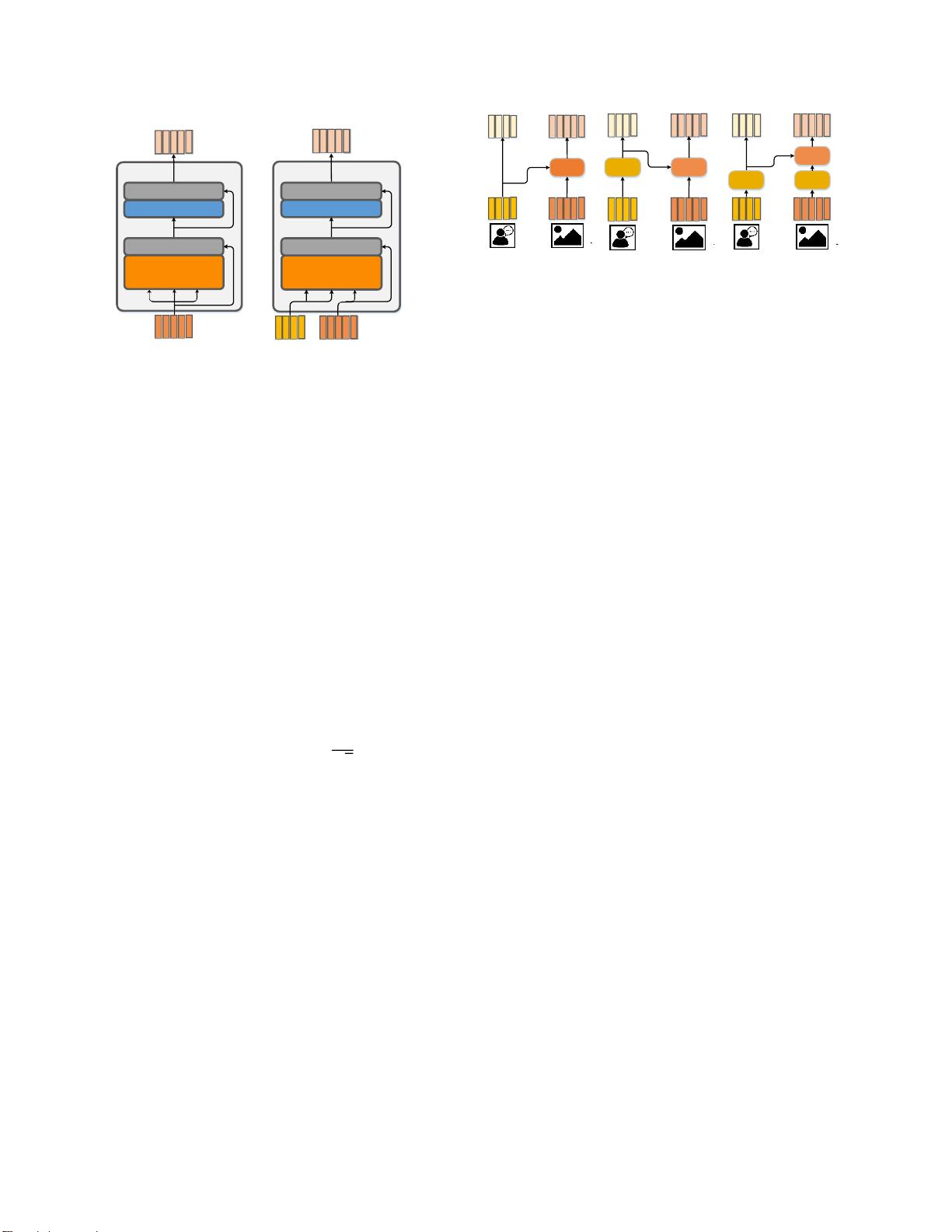
图2:两个基本的注意力单元,用于不同类型的输入。
SA取一组输入特征X,输出X的关注特征Z; GA取两组
输入特征X和Y,在Y
的
引导下输出X的关注特征Z。
[29]第10段。使用不同的组合,我们得到三个MCA的
变体具有不同的动机。
3.1. 自我注意和引导注意单元
标度点积注意力的输入由维 度
dkey
的 查 询 和 关 键
字
以及维度
dval
的值 组 成
。对于简单的
y
,
d
k
e
y
和
d
v
au
e
通
常被设置
为相同的数字d。我们计算查询与所有键的点
积,将每个键除以d,并应用softmax函数来获得值的
注意力权重给定查询q
R
1
×
d
,
n个键值对(打包成键
矩阵K
R
n
×
d
和值矩阵V R
n
×
d
),关注特征
f
R
1
×
d
是通过关于从q和K学习的注意力的所有值V的
加权求和获得的:
QK
f
=
A(q
,
K
,
V)
=
softmax(
q
d
)V
(
1
)
为了进一步提高被关注特征的表示能力,在[29]中
引入了
多头注意
,其由h
个
并行的“头”组成。每个头对
应于一个独立的缩放的点积注意力函数。关注输出特
征
f
由下式给出:
f
=
MA(q
,
K
,
V)
=
[
头
1
,
头
2
,
...
,
头
h
]
W
o
(
2
)
头
j
=
A
(
qW
Q
,
KW
K
,
V W
V
)
(
3
)
其中
W
Q
,
W
K
,
W
V
∈
Rd
×
dh
是第
j
个
头的投影矩阵,
W
o
Rh
<
$
d
h
×
d
.d
h
是来自每个头部的输出特征为了防止
多头注意力模型变得过于
图3:VQA的三种MCA变体的流程图。(Y)和(X)分
别表示问题和图像特征
大的,我们通常有
d
h
=
d/h。
在实践中,我们可以计
算一组
m
个查询
Q
=
[
q
1
;
q
2
;
.]
的注意力函数。
;
qm
]
∈
Rm
×
d
无缝地通过
在等式中用Q
替换
q
。(
2
)求出伴随输出
特征
F
∈
Rm
×
d
。
我们建立了两个注意力单元的多头注意处理多模态
输入功能的VQA,即
自我注意
(SA)单元和
引导注意
(GA)单元。SA单元(见图2a)由多头注意层和逐
点前馈层组成。取一组输入特征X
=
[x
1
;. ;x
m
]
R
m
×
d
x
,多
头注意学习X内成对样本x
i
,
x
j
>
之间的成对关系,并
通过对X内所有实例的加权求和输出关注输出特征Z
R
m
×
d
。
<
前馈层采用多头注意
力层的输出特征,并通过两个具有ReLU激活和丢弃的
全连接层(FC(4d)-ReLU-Dropout(0.1)-FC
(d))进一步将其转换。此外,将残差连接[12]和层
归一化[3]应用于两个层的输出,以促进优化。GA单元
(见图2b)采用两组
输入特征
X
R
m
×
d
x
并且
Y
=
[
y
1
;
.
;
yn
]
R
n
×
dy
,其中Y指导X的注意学习。注
意,X和Y的形状是灵活的,因此它们可以用于表示不
同模态的特征(
例如
,问题和图片)。GA单元分别对
来自X和Y
的每个配对样本
xi
,
yi
之间的成对
关系进行
释义:由于在
Eq.
(
2
)在两个注意单元中起着关
键作用,我们仔细研究它,看看它如何与不同类
型的输入有关。对于具有输入特征X的
SA
单元,
对于每个
xi
∈
X,其伴随特征
fi
=
MA(
xi
,
X
,
X)
可
以被理解为通过所有样本
重构
xi
在
X
中,关于它们与
X
的归一化相似性
,
i
。类似
地,对于具有输入特征
X
和
Y
的
GA
单元,针对
xi
∈
X
的关注特征
fi
=
MA(
xi
,
Y
,
Y
)通过由
Y
中的所有样
本关于它们与
xi
的归一化跨模态相似性重构
xi
来获
得。
GA
(
Y
)
(
十
)
SA
GA
(
Y
)
(
十
)
SA
GA
SA
(
Y
)
(
十
)
剩余10页未读,继续阅读
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- A7Demo.appstudio:探索JavaScript应用开发
- 百度地图范围内的标注点技术实现
- Foobar2000绿色汉化版:全面提升音频播放体验
- Rhythm Core .NET库:字符串与集合扩展方法详解
- 深入了解Tomcat源码及其依赖包结构
- 物流节约里程法的文档整理与实践分享
- NUnit3.vsix:快速安装NUnit三件套到VS2017及以上版本
- JQuery核心函数使用速查手册详解
- 多种风格的Select下拉框美化插件及其js代码下载
- Mac用户必备:SmartSVN版本控制工具介绍
- ELTE IK Web编程与Web开发课程内容详解
- QuartusII环境下的Verilog锁相环实现
- 横版过关游戏完整VC源码及资源包
- MVC后台管理框架2021版:源码与代码生成器详解
- 宗成庆主讲的自然语言理解课程PPT解析
- Memcached与Tomcat会话共享与Kryo序列化配置指南
