级联式人-物交互识别:迈向精细视觉理解
PDF格式 | 1.75MB |
更新于2025-01-16
| 10 浏览量 | 举报
"级联式人-物交互识别及其在视觉任务中的应用"
级联式人-物交互识别(Human-Object Interaction,HOI)是一种计算机视觉领域的关键技术,它旨在识别图像中的人与物体之间的交互行为,如“人吃胡萝卜”。这一技术在视觉问答、以人为中心的理解、图像生成和活动识别等众多视觉任务中发挥着重要作用。
近年来,尽管HOI识别的研究取得了显著进步,但依然面临诸多挑战。这些挑战主要源于任务本身的复杂性,其中包括精确地定位与识别出交互的主体(人)和客体(物体),以及正确预测两者之间的交互行为(动词)。这些子任务的难度在于,它们需要模型具备高级的理解能力,以处理图像中的复杂场景和多样的交互模式。
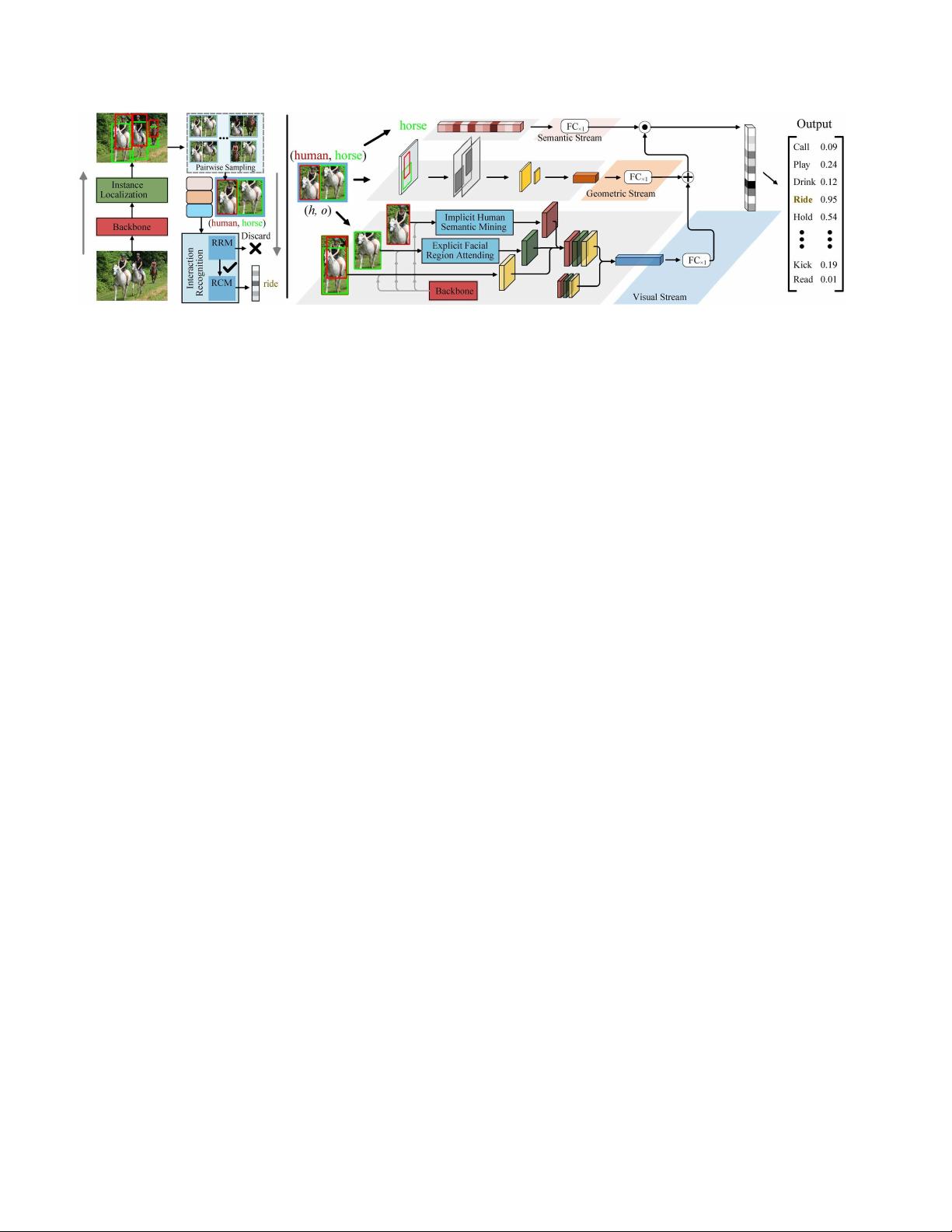
为了解决这些问题,文中提出了一种基于多阶段级联架构的HOI识别方法。这种架构以逐步细化的方式进行HOI理解,由实例本地化网络逐步优化HOI建议,并将这些信息传递给交互识别网络。实例本地化网络负责定位图像中的人和物体,而交互识别网络则专注于识别出人与物体之间的交互类别。
交互识别网络包含两个关键组件:关系排序模块和三流分类器。关系排序模块用于从多个可能的HOI建议中选择高质量的交互,而三流分类器则针对人、物体和交互关系进行分类,以实现更精确的预测。为了提高交互理解的效率,这两种模块配合使用了精心设计的以人为本的关系特征,允许模型更好地捕捉人与物体之间的语义联系。
此外,该框架不仅限于对象级别的关系检测,还能够进行像素级别的关系分割。这意味着模型可以细致到像素级别地解析出人与物体之间的交互区域,提供更深入的视觉理解,这对于精细的视觉任务尤为重要。
在实验部分,该方法在ICCV2019的Person-in-Context Challenge和V-COCO数据集上取得了优秀的成绩,证明了级联HOI识别网络的有效性。通过这种方式,研究者们为解决HOI识别的复杂性问题提供了一种新的思路,为未来的计算机视觉研究和应用奠定了坚实的基础。
4265
LOC
(a)
(b)第(1)款
图3:(a)我们的级联网络的管道,用于从输入图像中识别一个三元组:
人类,动词,对象
。(b)我们的三流关系分类模块
(RCM)的插图,实现了基于我们以人为中心的关系表示的HOI识别
在阶段
t
,L
t
将来自
L
t
-1
的检测结果
O
t
-1
作为输入,并
输出细 化结果
O
t
。然 后,从
O
t
×O
t
采样人
-
对象对
(
h
,
o
)。最后,R
t
使用(
h
,
o
)在当前和关键阶
段的关系特征
X
t
和
X
t
−
1
来估计
动词
得分向量
s
t
。关于
关系特征的更多细节在
§
3.3.1
中给出。特别是
RRM和RCM依赖于我们精心设计的以人为中心的关系
表征(第3.3.1节)。
3.3.1
以人为中心的关系表示
在每个阶段
t
,对于每个人
-
物对(
h
t
,
o
t
)
∈ O
t
×O
t
,
语义
特征
X
t
,
ge-
S
实例定位L
t
与交互识别R
t
net-t t
t
作品密切合作,在每一个阶段,和R
t
可以受益于改
进的本地化结果
O
t
的L
t
,并给出更好的相互作用的
预测。
接下来,我们将在§3.2中详细描述我们的实例定位
网络,在
§
3.3中详细描述交互识别网络。
3.2.
实例本地化网络
实例定位网络L输出一组人和对象区域,从中采样
人-对象对,并将其馈送到交互识别网络R中用于关系
分类。它建立在一系列探测器上,在阶段
t
,L
t
通过以
下方式细化从前一阶段检测到的对象区域
o
t
-1
∈O
t
-1
度量
特征
Xg
和
视觉
特征
Xv
被认为是一个彻底的关系表
示,如图所示3(b)款。在以下段落中,除非必要,
否则为简明起见省略上标
语义特征
X
s
。它捕捉了我们对
物体启示的
先验知识[13]
(
例如
,电话提供呼叫)。我们将X
s
∈R
N
构建为对象
和动作类别之间标签共现的频率[52],其中N表示HOI
数据集中预定义动作的数量。
几何特征X
g
.它表征了人与物之间的空间关系。类似于
[3,12],我们首先采用双通道掩码表示策略,获得两
个 实 体 的(
2
,
64
,
64
) -
d
特 征 张 量 。 然 后 是 两 个
conv+pooling操作,然后是一个全连接的
Y
t
=P
(
I
,
o
t
−
1
)
,
(
1)
(FC)层应用于张量以获得
X
g
∈R
256
。
〇
t
=D
t
(
Y
t
)
,
(
2
)
其中 I 是骨干 网 络的 CNN 特征 , 由 不同 阶 段共享 。
Yt
∈
RC
×
H
×
W
表示由
I
和输入RoI导出的盒特征。P和D
t
分别
表示RoIAlign [21]和箱回归头
类似于先前的级联对象检测器
[2
,
4]
,在
每个阶
段,L
t
都是用特定的联合交互
(
IoU
)阈值 训练
的,并且其输出被重新采样以训练具有更高
IoU
阈
值的下一个检测器L
t
+1
。 通过这种方式,
我们逐渐
提高了级联中更深阶段的训练数据
的质量,从而提高了
对
困难负面示例的选择性。 在每个阶段,实例本地
化损失
L
t
与
Faster R-CNN
相同
[39]
。
3.3.
交互识别网络
As shown in Fig. 3 (a), the interaction recognition net-
work R comprises a relation ranking module (RRM,
§
3.3.2)
and a relation classification module (RCM,
§
3.3.3). 两
视觉特征
X
v
.
与
X
s
和
X
g
相比,视觉特征具有更重要的
意义,对人类识别微妙的相互作用有着深远的影
响。对于每个人
-
物对
(
h
,
o
),我们有三个特征
H
∈
RC
×
H
×
W
,
O
∈
RC
×
H
×
W
和
U
∈
RC
×
H
×
W
,分别
来自人、
物及其联合区域:
H
=
P(I
,
h
)
,
O
=
P(I
,
o
)
,
U
=
P
(I
,
(
h
,
o
))
.
(三)
这里,
H
、
O
和
U
是等式1中的RoIAlign特征
Y
的具体实
例。(1,2),它们被重新命名,以明确它们来自不
同的地区。
为了更好地捕捉HOI中的底层语义,我们引入了两
种功能增强机制:隐
式的人的语义挖掘
,以提高人的
特征H和
显式的面部区域参加
,以提高对象的特征O。
然后我们有视觉特征:
X
v
=
[
H
<$
,
O
<$
,
U
]
∈
R
3
C
×
H
×
W
,
(
4
)
S
t
S
X
t
∈
R
N
S
X
t
∈
R
256
G
S
不
G
L
X
t
S
X
t
G
X
t
不
v
H
不
N
X
t
∈
R
3
C
×
H
×
W
s∈
[0
,
1]
v
§3.3.2
O
不
S
t
v
X
<$
t
∈
R
1
024
v
§3.3.3
ROI
我
U
t
∈
R
C
×
H
×
W
X
t
−
1
v
R
剩余11页未读,继续阅读
相关推荐




8 浏览量
7 浏览量
4 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- VB通过Modbus协议控制三菱PLC通讯实操指南
- simfinapi:R语言中简化SimFin数据获取与分析的包
- LabVIEW温度控制上位机程序开发指南
- 西门子工业网络通信实例解析与CP243-1应用
- 清华紫光全能王V9.1软件深度体验与功能解析
- VB实现Access数据库数据同步操作指南
- VB实现MSChart绘制实时监控曲线
- VC6.0通过实例深入访问Excel文件技巧
- 自动机可视化工具:编程语言与正则表达式的图形化解释
- 赛义德·莫比尼:揭秘其开创性技术成果
- 微信小程序开发教程:如何实现模仿ofo共享单车应用
- TrueTable在Windows10 64位及CAD2007中的完美适配
- 图解Win7搭建IIS7+PHP+MySQL+phpMyAdmin教程
- C#与LabVIEW联合采集NI设备的电压电流信号并创建Excel文件
- LP1800-3最小系统官方资料压缩包
- Linksys WUSB54GG无线网卡驱动程序下载指南
