一致性注意Siamese网络:深度学习人重识别的关键突破
PDF格式 | 963KB |
更新于2025-01-16
| 34 浏览量 | 举报
"本文介绍了一种新的深度学习架构——一致性注意Siamese网络,用于解决人重新识别(re-id)中的关键挑战。该方法着重于跨视角匹配中的空间定位和视图不变表示学习,旨在提高re-id在真实世界应用中的可靠性。文章的主要贡献包括:(a)一个仅依赖身份标签的注意力生成框架,(b)强调同一人图像间注意力一致性的明确机制,(c)引入一个新的暹罗框架,结合注意力和一致性,创建有原则的监督信号,同时提供对暹罗网络预测的解释能力。这种方法在多个数据集上进行了广泛的评估,表现出竞争力。
1. 人重新识别问题
人重新识别是一项技术,目标是根据在不同摄像头视角下的图像找到同一人。随着监控和其他视频分析应用的需求增长,re-id的研究日益受到关注。尽管已取得显著进步,但由于视角变化、光照差异和遮挡等因素,re-id在实际应用中仍面临挑战。
2. 一致性注意Siamese网络的创新点
- 灵活框架:该方法使用身份标签指导注意力的生成,无需额外标注,提高了模型学习的效率和效果。
- 注意力一致性:通过设计机制确保同一人的不同图像具有相似的注意力分布,增强跨视角匹配的稳定性。
- Siamese框架扩展:将注意力和一致性相结合,不仅提升了匹配性能,还允许理解模型的决策过程,增强了模型的可解释性。
3. 应用与评估
该方法在CUHK03-NP、DukeMTMC-ReID和Market-1501等标准数据集上进行了实验,展示了与现有方法相媲美的性能。这表明一致性注意Siamese网络在解决re-id任务中的空间定位和局部表示学习问题上具有潜力。
4. 结论
一致性注意Siamese网络为re-id提供了一个综合解决方案,它结合了空间定位、特征表示和跨视角匹配,有望推动re-id技术在复杂环境中的实际应用。通过端到端训练,模型能够在处理视图变化和遮挡等问题时,实现更准确的人员匹配。"
5737
n
=1
n
=1
问题所在在涉及遮挡和杂乱的场景中,这可能不是最
佳解决方案,注意力会导致更好的空间定位。为此,
与这些方法相反,我们的方法在学习过程中利用注意
力,同时还联合学习一致的空间局部化和不变特征表
示。
3.
一致注意暹罗网络
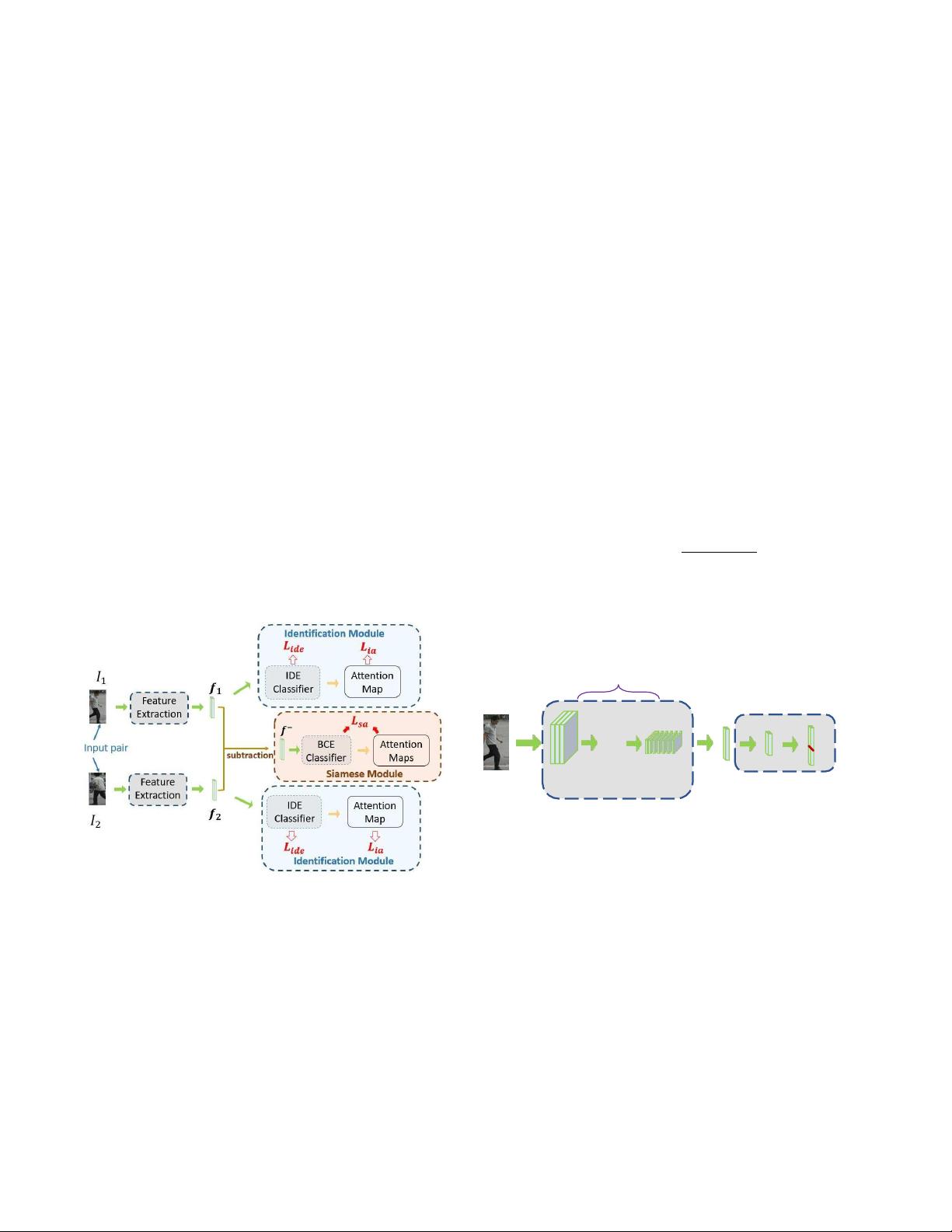
在本节中,我们将介绍我们提出的基于注意力的深
度架构,即一致性注意力连体网络(CASN),如图
2. CASN包括一个识别模块和一个Siamese模块,它们
提供了一种强大、灵活的方法来处理视点变化、遮挡
和背景杂波。识别模块(第3.1节),其明确的注意力
指导作为监督,只给出身份标签,帮助找到可靠和准
确 的 空 间 定 位 的 人 在 图 像 中 的 兴 趣 , 并 执 行 身 份
(ID)预测。暹罗模块(第3.2节)为网络提供了来自
注意力一致性的监督信号,确保我们为同一个人的图
像获得空间一致的注意力区域,以及学习-
3.1.1
IDE基线架构
IDE基线基于ResNet50架构[11],遵循[45]中的工作和
最近采用ResNet50的论文从conv1到conv5的卷积层在
ImageNet上进行预训练[10],然后由两个完全连接的层
组成的IDE分类器为输入图像生成身份预测。鉴别基
线目视总结见图3。请注意,虽然图3显示了IDE架构
[45],但这可以很容易地与任何其他可以给出特征向
量
f
的基线架构交换。例如,要使用基于部分的卷积基
线(PCB)架构[34],只需在获得f之前将图3中的“特
征提取”块与PCB的主干交换PCB是IDE的一个修改,
它用空间池代替了IDE中的全局平均池操作,用于区
分部分信息特征学习。基线模型是通过优化识别损失
来学习的,这基本上最大化了为每个训练信息预测正
确的类(身份)标签的可能性
年龄形式上,给定
N
个训练图像
{
I
n
}
,
N
属于
到
C
个
不同的身份,每个图像具有
身份标签
{
c
n
}
N
∈
{1
,
.
,
C
},我们优化以下内容
使用视图不变特征表示进行鲁棒的图库匹配。在下文
中,我们将分别描述这两个
多类交叉熵损失:
Σ
N
exp(
y
)
模块更详细,导致整体设计,
的CASN。
L
ide
=
−
n
=1
对数
Σ
C
n
j
exp
(y
j
)
(一)
其中
y
c
n
是来自输入图像
I
n
的IDE分类器的类
c
n
的预测。
Resnet50
(预训练)
特征提
取
鉴别基线
FC
FC
IDE
分类器
图2:一致的注意暹罗网络。
3.1.
识别模块
首先介绍了CASN的身份识别模块的体系结构。我
们首先描述训练识别(IDE)模型的基线架构[45],然
后是将注意力引导集成到IDE架构中的整体识别模块
图3:基线。
f
是Resnet50conv5之后的特征向量,y是
维度等于训练标识总数的ID预测向量,并且y
c
是输入
图像的ID标签c注意,这里的IDE或PCB [34]。
3.1.2
识别注意事项
感兴趣的人的空间定位是re-id算法的关键第一步,这
应该反映在端到端的学习过程中。虽然最近的许多工
作
⋯
特征映射
特征映射
conv1
conv5
剩余11页未读,继续阅读
相关推荐

79 浏览量




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebDrive v16.00.4368: 简易易用的Windows风格FTP工具
- FirexKit:Python的FireX库组件
- Labview登录界面设计与主界面跳转实现指南
- ASP.NET JS引用管理器:解决重复问题
- HTML5 canvas绘图技术源代码下载
- 昆仑通态嵌入版ASD操舵仪软件应用解析
- JavaScript实现最小公倍数和最大公约数算法
- C++中实现XML操作类的方法与应用
- 设计编程工具集:材料重量快速计算指南
- Fancybox:Jquery图片轮播幻灯弹窗插件推荐
- Splunk Fitbit:全方位分析您的活动与睡眠数据
- Emoji表情编码资源及数据库查询实现
- JavaScript实现图片编辑:截取、旋转、缩放功能详解
- QNMS系统架构与应用实践
- 微软高薪面试题解析:通向世界500强的挑战
- 绿色全屏大气园林设计企业整站源码与多技术项目资源
