音频驱动的动态对话人脸生成:隐性属性学习与FACIAL-GAN
PDF格式 | 19.19MB |
更新于2025-01-16
| 3 浏览量 | 举报
"隐性属性学习的合成动态对话人脸"
在当前的计算机视觉和图形学领域,动态对话人脸的合成是一项关键技术。随着人工智能的发展,这项技术的重要性日益凸显,它能够为虚拟现实、语音交互以及视频制作等领域带来创新。本文介绍了一种新的方法,名为“FACIAL-GAN”(面部隐性属性学习生成对抗网络),专门用于生成基于音频输入的逼真对话人脸视频。
在传统的对话人脸生成方法中,通常只关注显性属性,如嘴唇运动,以匹配音频中的语素信息。然而,一个真实的对话场景涉及到更多的细节,包括头部姿势、眼神交流(如眨眼)等隐性属性,这些同样对传达情感和信息至关重要。FACIAL-GAN的独特之处在于,它不仅仅考虑显性属性,而且也考虑了这些与音频相关性较弱但同样重要的隐性属性。
FACIAL-GAN网络架构融合了音素感知、上下文感知和身份感知信息,以创建一个统一的框架,这个框架能够从输入的音频信号中生成包括嘴唇动作、头部姿势和眨眼在内的多维度人脸属性。通过这样的设计,生成的人脸动画不仅与音频同步,还能反映出个体的独特特征,使得视频看起来更为自然和生动。
实验结果显示,FACIAL-GAN生成的对话人脸视频质量超越了现有的方法,其同步的嘴唇动作、自然的头部运动以及逼真的眨眼效果得到了验证。用户研究进一步证实了该方法的有效性,表明它在创造沉浸式和真实感的交互体验方面具有显著优势。
此外,这种方法的应用潜力广泛,可以用于虚拟主播、在线教育、电影制作等多个领域,通过创造高度逼真的人工智能角色,提升人机交互的自然度和真实性。未来的研究可能进一步探索如何增加更多的情感表达和非语言交流元素,以实现更加丰富和复杂的对话场景。
FACIAL-GAN是对话人脸生成领域的一个重要突破,它通过集成显性和隐性属性学习,成功地提升了生成视频的真实感和连贯性。随着技术的不断进步,我们可以期待在未来看到更多由人工智能驱动的、具有高度真实感的动态对话人脸。
Chenxu Zhang
1
, Yifan Zhao
2
, Yifei Huang
3
, Ming Zeng
4
, Saifeng Ni
5
Madhukar Budagavi
5
, Xiaohu Guo
1
{chenxu.zhang, xguo}@utdallas.edu, zhaoyf@buaa.edu.cn, yifeihuang17@gmail.com
zengming@xmu.edu.cn, {saifeng.ni, m.budagavi}@samsung.com
3867
0
FACIAL:使用隐性属性学习合成动态对话人脸
0
1德克萨斯大学达拉斯分校2北京航空航天大学3华东师范大学4厦门大学5三星研究美国
0
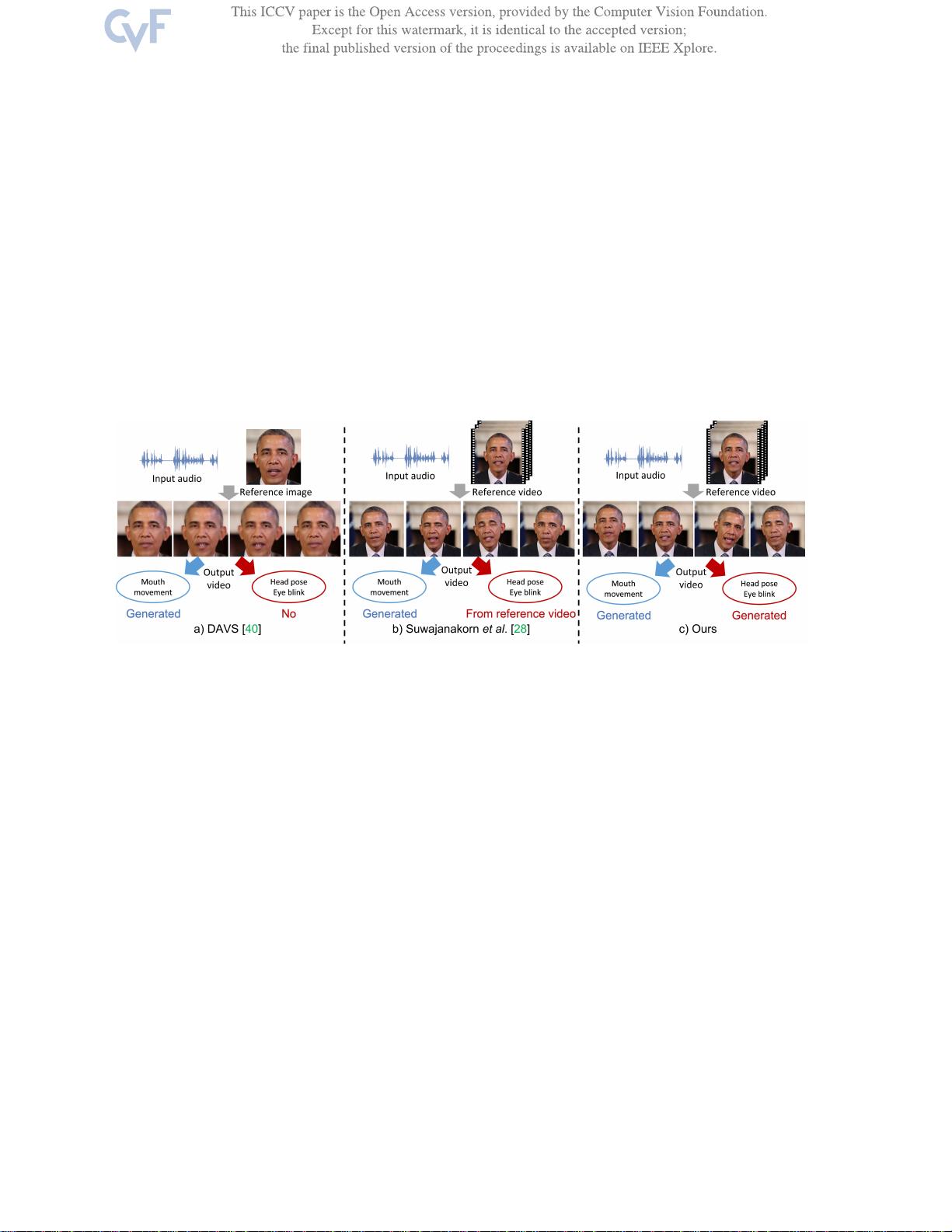
图1.
三种典型框架的示意图。a)显性属性生成:仅考虑说话头部的嘴部动作。b)显性生成与隐性变形:仅生成显性嘴部动作,并从参考视频中
获取隐性属性。c)我们的隐性属性学习框架:在一个统一的框架中从输入音频生成显性和隐性属性。
0
摘要
0
在本文中,我们提出了一种对话人脸生成方法,该方法以音
频信号作为输入,以短目标视频片段作为参考,并合成与输
入音频信号同步的目标人脸的逼真视频,包括自然的嘴唇动
作、头部姿势和眨眼。我们注意到,合成的人脸属性不仅包
括与语音高度相关的显性属性,还包括与输入音频相关性较
弱的隐性属性,如头部姿势和眨眼。为了模拟不同人脸属性
与输入音频之间的复杂关系,我们提出了一种面部隐性属性
学习生成对抗网络(FACIAL-GAN),该网络整合了音素感
知、上下文感知和身份感知信息,以合成具有逼真的嘴唇、
头部姿势和眨眼动作的3D人脸动画。然后,我们的渲染到视
频网络将渲染的人脸图像和眨眼的注意力图作为输入,生成
逼真的输出视频帧。
0
实验结果和用户研究表明,我们的方法可以生成具有同步嘴
唇动作、自然头部动作和眨眼动作的逼真对话人脸视频,质
量优于现有方法的结果。
0
1.引言
0
由输入音频驱动的动态对话人脸合成已成为计算机视觉、计
算机图形学和虚拟现实中的重要技术。已经取得了稳定的研
究进展,但是生成与真实捕捉视频难以区分的逼真对话人脸
仍然具有挑战性,这些对话人脸不仅包含同步的嘴唇动作,
还具有个性化和自然的头部动作和眨眼等。动态对话人脸中
包含的信息可以大致分为两个不同的层次:1)显性属性和
隐性属性。
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- A7Demo.appstudio:探索JavaScript应用开发
- 百度地图范围内的标注点技术实现
- Foobar2000绿色汉化版:全面提升音频播放体验
- Rhythm Core .NET库:字符串与集合扩展方法详解
- 深入了解Tomcat源码及其依赖包结构
- 物流节约里程法的文档整理与实践分享
- NUnit3.vsix:快速安装NUnit三件套到VS2017及以上版本
- JQuery核心函数使用速查手册详解
- 多种风格的Select下拉框美化插件及其js代码下载
- Mac用户必备:SmartSVN版本控制工具介绍
- ELTE IK Web编程与Web开发课程内容详解
- QuartusII环境下的Verilog锁相环实现
- 横版过关游戏完整VC源码及资源包
- MVC后台管理框架2021版:源码与代码生成器详解
- 宗成庆主讲的自然语言理解课程PPT解析
- Memcached与Tomcat会话共享与Kryo序列化配置指南
