基于语义图卷积网络的3D人体姿态回归
182 浏览量
更新于2025-01-16
收藏 1.96MB PDF 举报

1
3425
基于语义图卷积网络的三维人体姿态回归
龙钊
1
奚鹏
2
于天
1
穆巴西尔
1
迪米特里斯1卡帕迪亚
罗格斯大学
(
Rutgers University)
2
宾厄姆顿大学(Binghamton University)
{lz311,yt219,mk1353,dnm}@ cs.rutgers.edu,xpeng@binghamton.edu
摘要
在本文中,我们研究了学习图卷积网络(
GCN
)回
归的问题。目前
GCN
的体系结构局限于卷积滤波器的
小感受野和每个节点的共享变换矩阵。为了解决这些
局限性,我们提出了语义图卷积网络(
SemGCN
),
一种新的神经网络架构,用于处理具有图结构数据的
回归任务。
SemGCN
学习捕获语义信息,如局部和全
局节点关系,这些信息在图中没有显式表示这些语义
关系可以通过端到端的训练从地面事实中学习,而无
需额外的监督或手工制定的规则。我们进一步研究将
SemGCN
应用于
3D
人体姿势回归。我们的公式是直观
和充分的,因为
2D
和
3D
人体姿势都可以表示为编码人
体骨架中关节之间的关系的结构化图。我们进行了全
面的研究,以验证我们的方法。结果证明,
SemGCN
优于现有技术,同时使用少
90%
的参数。
1.
介绍
卷积神经网络(CNN)已经成功地解决了经典的计
算机视觉问题,如图像分类[12,29,31,52],对象
检测[19,46,
55,63,74,79]和生成[43,58,71,73,80],其中
输入图像具有网格状结构。然而,许多现实世界的任
务,分子结构、社交网络和3D网格只能以不规则结构
的形式表示,其中CNN具有有限的应用。
为 了 解 决 这 一 限 制 , 最 近 引 入 了 图 卷 积 网 络
(GCN)[17,28,49]作为CNN的推广,可以直接处
理一 般类 别的 图。 它们 在应 用于 3D 网格变形[45,
64]、图像字幕[70]、场景理解[68]和视频识别[66,67]
时达到了最先进的性能。这些作品使用GCN来建模视
觉对象的关系,
阳离子。在本文中,我们研究使用深度GCN进行回
归,这是计算机视觉的另一个核心问题,具有许多现
实世界的应用。
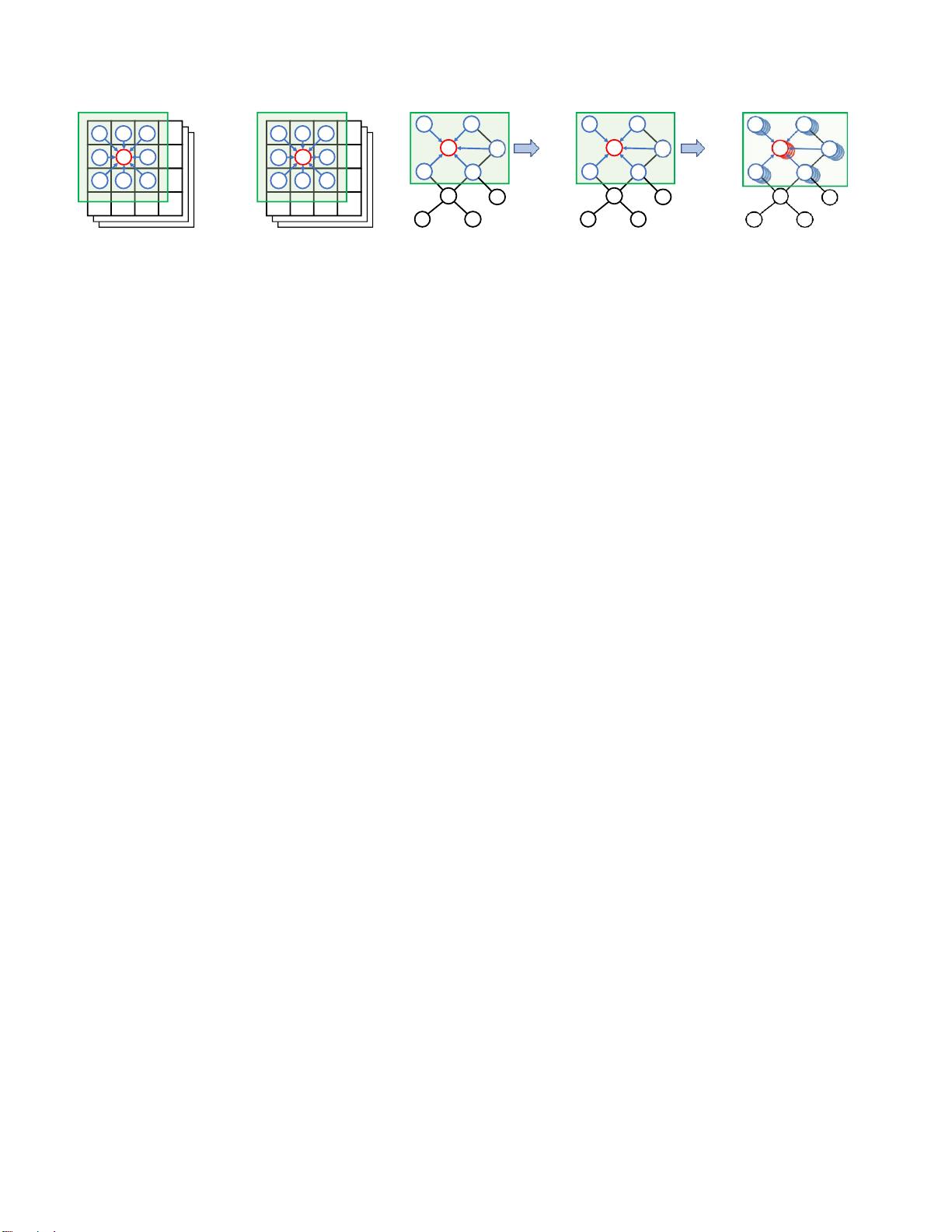
然而,由于基线方法的以下限制,GCN不能直接应
用于首先,为了处理图节点可能具有不同数量的邻域
的问题,卷积滤波器为所有节点共享相同的权重矩
阵,这与CNN不可比较。其次,根据[28]的指导,通
过限制滤波器在每个节点周围的一步邻域由于这种公
式,卷积核的感受野被限制为1,这严重损害了信息交
换的效率,特别是当网络更深时。
在这项工作中,我们提出了一种新的图神经网络架
构的回归称为
语义图卷积网络(
SemGCN
)
,以解决
上述限制。具体来说,我们研究学习语义信息编码在
一个给定的图,
即
,节点的局部和全局关系,这在以
前的工作中没有得到很好的研究。SemGCN不依赖于
手工 制作的 约束[10,13 ,51]来 分析 特定应用的模
式,因此可以很容易地推广到其他任务。
特别是,我们研究SemGCN的2D
到
3D
人体姿势回
归
。给定一个2D人体姿势(和可选的相关图像)作为
输入,我们的目标是预测其对应的3D关节在某个坐标
空间中的位置。使用SemGCN公式化这个问题是直观
的。2D和3D姿势都能够自然地表示为 一个规范的骨
架在2D或3D坐标的形式,和SemGCN可以明确地利用
它们的空间关系,这是理解人类行为的关键[67]。
我们的工作做出了以下贡献。首先,我们提出了一
种 改 进 的 图 卷 积 运 算 , 称 为 SemGConv
(
SemGConv
)
,它来自CNN。其关键思想是学习边的
通道权重作为图中隐含的先验,然后将它们与核矩阵
相结合。这显著提高了图卷积的能力。其次,我们引
入SemGCN,其中SemGConv和非局部[65]层是

剩余13页未读,继续阅读
点击了解资源详情
2024-09-06 上传
2021-09-25 上传
335 浏览量
208 浏览量
109 浏览量
107 浏览量
点击了解资源详情

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易二维码签到系统:会议活动签到解决方案
- Ceres库与SDK集成指南:C++环境配置及测试程序
- 深入理解Servlet与JSP技术应用与源码分析
- 初学者指南:掌握VC摄像头抓图源代码实现
- Java实现头像剪裁与上传的camera.swf组件
- FileTime 2013汉化版:单文件修改文件时间的利器
- 波斯语话语项目:实现discourse-persian配置指南
- MP4视频文件数据恢复工具介绍
- 微信与支付宝支付功能封装工具类介绍
- 深入浅出HOOK编程技术与应用
- Jettison 1.0.1源码与Jar包免费下载
- JavaCSV.jar: 解析CSV文档的Java必备工具
- Django音乐网站项目开发指南
- 功能全面的FTP客户端软件FlashFXP_3.6.0.1240_SC发布
- 利用卷积神经网络在Torch 7中实现声学事件检测研究
- 精选网站设计公司官网模板推荐
