混淆技术与知识蒸馏:一项实证研究
PDF格式 | 3.22MB |
更新于2025-01-16
| 35 浏览量 | 举报
"该研究主要探讨了混淆在知识蒸馏中的作用,通过对不同混淆技术和知识蒸馏方法的实证分析,揭示了它们之间的相互影响和潜在关联。研究中提到了混淆技术,如Mixup,作为一种数据增强手段,能提升模型的泛化能力和对抗性。知识蒸馏则用于模型压缩和迁移学习,通过大模型的指导优化小模型的性能。研究者进行了深入的实验,包括分析、可视化和图像分类任务,以理解混淆如何影响知识蒸馏过程,并提出了改进策略以提升学生网络的效果。此研究对于使用知识蒸馏的实践者具有指导意义,并提供了相关代码供进一步研究参考。"
混淆在知识蒸馏中的作用是一个重要的研究主题,因为两者都是深度学习中常用的优化技术。Mixup通过线性插值创建新样本,促进模型学习更平滑的决策边界,增强了模型的泛化能力。而知识蒸馏则通过大模型(教师网络)的指导,使小模型(学生网络)能够捕获更丰富的知识,从而在减少计算资源的同时保持高性能。
研究中提到,混淆和知识蒸馏看似不同,但实际上可以相互结合。例如,混合增强结合了混淆和知识蒸馏的概念,旨在同时提升模型的泛化能力和压缩效率。边缘蒸馏则是另一种融合混淆和知识蒸馏的方法,它在知识传递过程中考虑了混淆的影响。
通过广泛的实验,研究人员分析了混淆如何改变模型在知识蒸馏过程中的行为,特别是在图像分类任务中。他们观察了混淆如何影响模型的决策边界,以及如何影响学生网络对教师网络知识的吸收。此外,他们还提出了一些策略,以优化混淆和知识蒸馏的结合,提高学生网络的性能。
这项工作强调了混淆在知识蒸馏中的潜在价值,不仅加深了我们对这两种技术相互作用的理解,也为实际应用提供了有价值的见解和实用建议。对于未来的研究,这可能意味着我们可以期待更高效、更强大的模型压缩和迁移学习方法的出现,同时保持模型的泛化能力和抗干扰能力。
2321
L
∼
∈
- -
∈
X <$
∈
Y
{}
Σ
Σ
E
不
L
不
不
输入
x
R
d
以标记
y
=
1
,
2
,
...
,
K.
令
(
f
(
x
)
,
y
)为损失函数,用于度量分类器
f
(
x
)
对标签
y
的预测有多差
。
混合增强[38]在混合增强中,两个
通过线性插值将样本混合在一起
:
x
∈
ij
(
λ
)
=
λ
xi
+
(1
λ
)
xj
,
y
∈
ij
(
λ
)
=
λ
yi
+
(1
λ
)
yj
,其中
λ
[
0
,
1
]
遵循分布
P
λ
,
λ
β
(
α
,
α
)。
然后,混淆损失函数可以
描述为:
n n
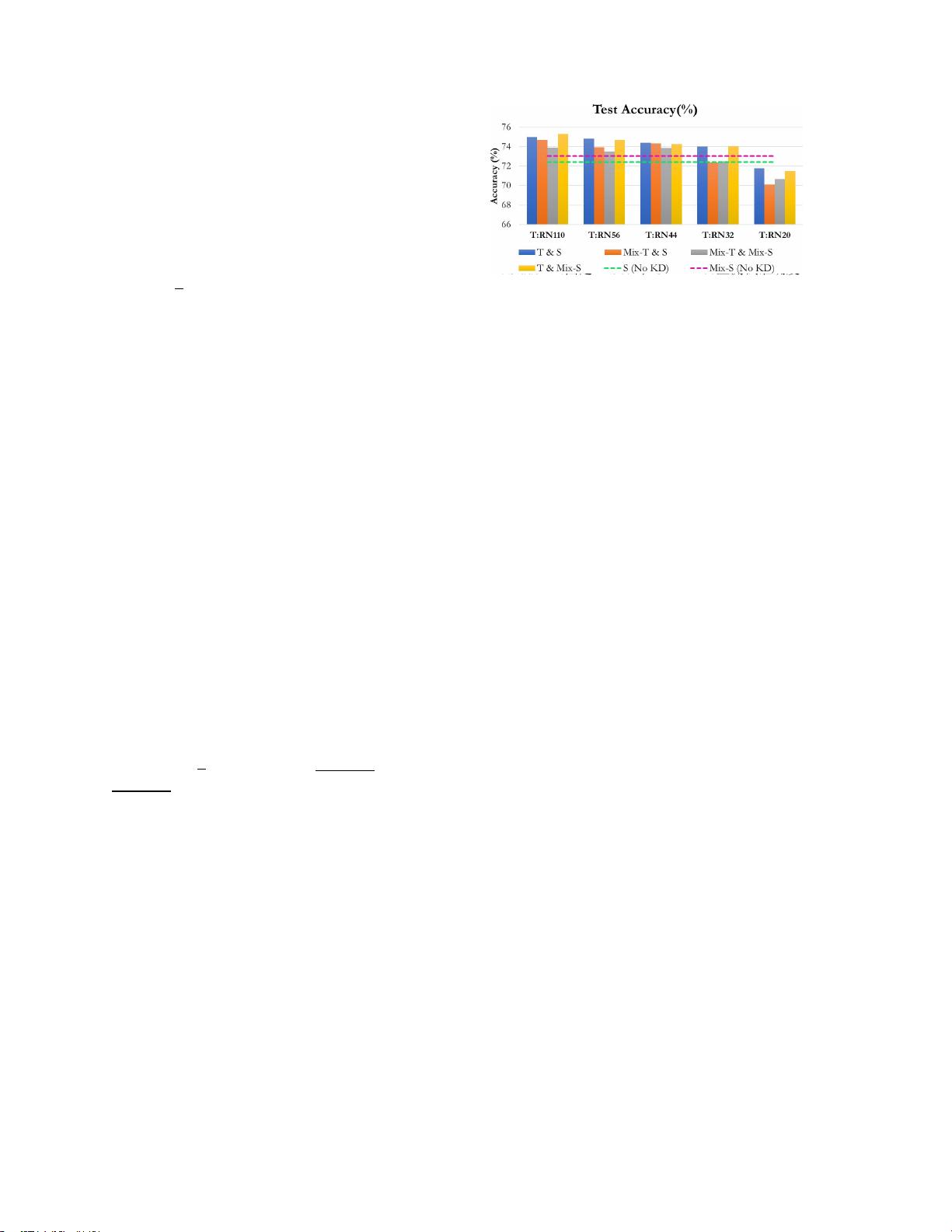
图2. Student(固定RN56)在CIFAR100上测试准确度
L
混
合
(f)=
1
n
2
i
=1
j
=1
λ
P
λ
[
L
(
f
(
x
)
i
j
(
λ
)
)
,
y
ij
(
λ
))]
、
(
1
)
在不同的教师网络下,
=
4。 在这里,T和 S代表标准
教师和标准学生。
Mix-T
和
Mix-S
是混合训练的教师和混合训
练的学生,
其中表示本研究中的交叉熵损失函数。具体地,等式1
中的超参数λ用于指定混合的程度。换句话说,beta分
布中的控制参数α
命令特征
-目标对之间的插值强度,
即,高α生成强插值样本。
已经提出了相当数量的混淆变体[31,35,11]。这
些基于混合的方法的一般策略本质上是相似的,因为
它们通过混合图像并按比例混合它们的标签来扩展训
练分布因此,在本研究中,我们只关注常规混淆,以
研究混淆与知识蒸馏之间的相互作用[38]。
知识蒸馏[8]在知识蒸馏中,预先给定数据集上的预先
训练的教师模型
f
T
,
通过利用由
f
T
生成的简明知识在相
同的数据集上训练学生模型
f
S
。具体地,一旦教师网
络被训练,其参数在KD中的训练期间被冻结,然后,
通过最小化其输出与教师网络生成的软标签之间的相
似性为此,我们最小化学生和教师的logits之间的差异
如下:
分别与标准教师模型相比,混合培训的教师指导的是表现较
差的学生,而能力较低的教师模型通常会提炼出表现较差的
学生。
KD过程。本研究跨越两个层面,试图通过综合的实证
分析,提出兼容与不兼容的观点。此外,根据观察,
我们建议一个更好的学习策略,以提高网络
3.
Mixup和KD相互作用的主要发现
在本节中,我们将讨论我们的主要发现。我们首先
参考图2。在这里,我们描述了四种可能的情况,其中
混合增强可能涉及KD如下;标准教师和标准学生(T&
S)、混合训练的教师和标准学生(Mix-T& S)、混
合训练的教师和混合训练的学生(Mix-T& Mix-S)、
以及标准教师和混合训练的学生(T& Mix-S)在相同
温度下
,
4. 我们将学生模型固定为ResNet 56(RN 56),并评估-
通过改变ResNet20(RN20)的教师模型来使用它
ResNet110(RN110)
如图2所示,我们可以观察到两点:
n
T S
L(
f
T
,
f
S
)=
1
<$
KL
(S(
f
(
x
i
)
)
,
S
(
f(x
i
)
(
2
)
首先,学生的表现与一个混乱的帮助
kd
n
i=1
T T
受过训练的教师(混合T S,混合T混合S)总是显示出
比标准教师的帮助更低的有效性
其中,S表示softmax函数,KL测量Kullback-Leiber散
度,并且输出由温度平滑的模型的logits。
最近,一些工作已经利用数据增强并取得了有希望的
结果,因为增强的样本使网络能够从蒸馏框架中的不
同视图学习放松的知识[33,32,12]。在广泛可用的
方法中,它们通常不能提供对模型内部工作的洞察。
同时,最近的作品[15,23]研究了KD相反,我们感兴
趣的是光增强的基本机制,
(T S,T Mix-S),即使混合训练的教师本身比没有
混合训练的教师表现出更好的测试准确性。第二,一
般来说,较高能力的教师模型提取出较好的学生,但
对于较低能力的教师(T:RN44 S:RN56),与普通
学生模型相比,学生表现仍显示基于这些观察,本文
旨在研究以下问题:1)
为什么混合训练的教师模型会
损害学生在
K D
中 的 有 效 性 ?
我们将 在 章 节 中 回
答这个问题
3.
那么,2)
在混合增强的情况下,如何提高知识提
取的有效性?
我们将在第4节讨论这个问题。
剩余10页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 支付宝订单监控免签工具:实时监控与信息通知
- 一键永久删除QQ空间说说的绿色软件
- Appleseeds训练营第4周JavaScript练习
- 免费HTML转CHM工具:将网页文档化简成章
- 奇热剧集站SEO优化模板下载
- Python xlrd库:实用指南与Excel文件读取
- Genegraph:通过GraphQL API使用Apache Jena展示RDF基因数据
- CRRedist2008与CRRedist2005压缩包文件对比分析
- SDB交流伺服驱动系统选型指南与性能解析
- Android平台简易PDF阅读器的实现与应用
- Mybatis实现数据库物理分页的插件源码解析
- Docker Swarm实例解析与操作指南
- iOS平台GTMBase64文件的使用及解密
- 实现jQuery自定义右键菜单的代码示例
- PDF处理必备:掌握pdfbox与fontbox jar包
- Java推箱子游戏完整源代码分享
