并行最优传输GAN算法:提升GAN训练效果与模式多样性
PDF格式 | 1.05MB |
更新于2025-01-16
| 141 浏览量 | 举报
"并行最优传输GAN算法是针对生成对抗网络(GAN)训练质量和模式覆盖问题的一种新方法,由吉尔·亚伯拉罕、严佐汤和姆·德拉蒙德提出。该算法在低维表示空间内并行执行最优传输,以改善GAN训练的稳定性和生成样本的质量,增加数据分布的模式覆盖。研究表明,这种方法在CIFAR-10、OxfordFlowers和CUBBirds数据集上实现了显著的定性和定量提升。"
生成对抗网络(GANs)是一种强大的生成模型,由两个相互竞争的网络组成:生成器(Generator)和鉴别器(Discriminator)。生成器尝试从随机噪声中生成逼真的样本,而鉴别器试图区分真实数据与生成的样本。然而,GANs在训练过程中存在一些固有问题,如低模态多样性和样本失真,这些问题主要源于距离度量的不准确估计。
最优传输(Optimal Transport)理论在统计学和机器学习中有广泛应用,其在解决大规模问题时表现出良好的直观性和数值稳定性。在GANs中,最优传输被用来估计Wasserstein距离,有助于缓解训练不稳定性,如消失梯度和模式崩溃。
论文中提出的并行最优传输GAN算法引入了一个新的正则化项,这个项在数据分布的低维表示空间中并行执行,以加速Wasserstein距离的估计收敛速度。通过这种方式,算法能够提供更稳定的训练过程,生成更高质量的样本,并增加对原始数据分布的模式覆盖。
实验结果表明,这种方法在多个数据集上的表现优于传统GAN训练,包括在CIFAR-10(一个常用的彩色图像数据集)、OxfordFlowers(花卉识别数据集)和CUBBirds(鸟类识别数据集)上,不仅提高了生成样本的视觉质量,还量化地提升了模式多样性。
这一并行最优传输GAN算法为解决GAN训练中的挑战提供了新的视角,通过优化距离度量的估计,提高了生成模型的性能,有望在图像生成和其他应用领域带来更优秀的成果。
4413
B
R
R
rz
R
高维象空间
这是从Wasserstein 距离的 收 敛 立 场 出 发 的 , 讨 论 如
下。
我们用P表示概率分布,
用
P
n
表示经 验分 布
。在
large
n
的极限
中
,
k阶的Wasser-stein距离几乎必然接近于零
W
k
( P
,
P
n
)
→
0
a
.
S
.
(
5
)
在实践中,获得有限数量的样品
从
P
得出
的
n
提出了如何量化的问题。
P
_(?)
n
与
P
_
(?
)不幸的是,如
[8]所
示
,收敛速度
受到
维数的诅咒
[10]:
E
[
W
(P
,
P)
]
4
.
Σ
1
1
个
d
1
n
n
(六)
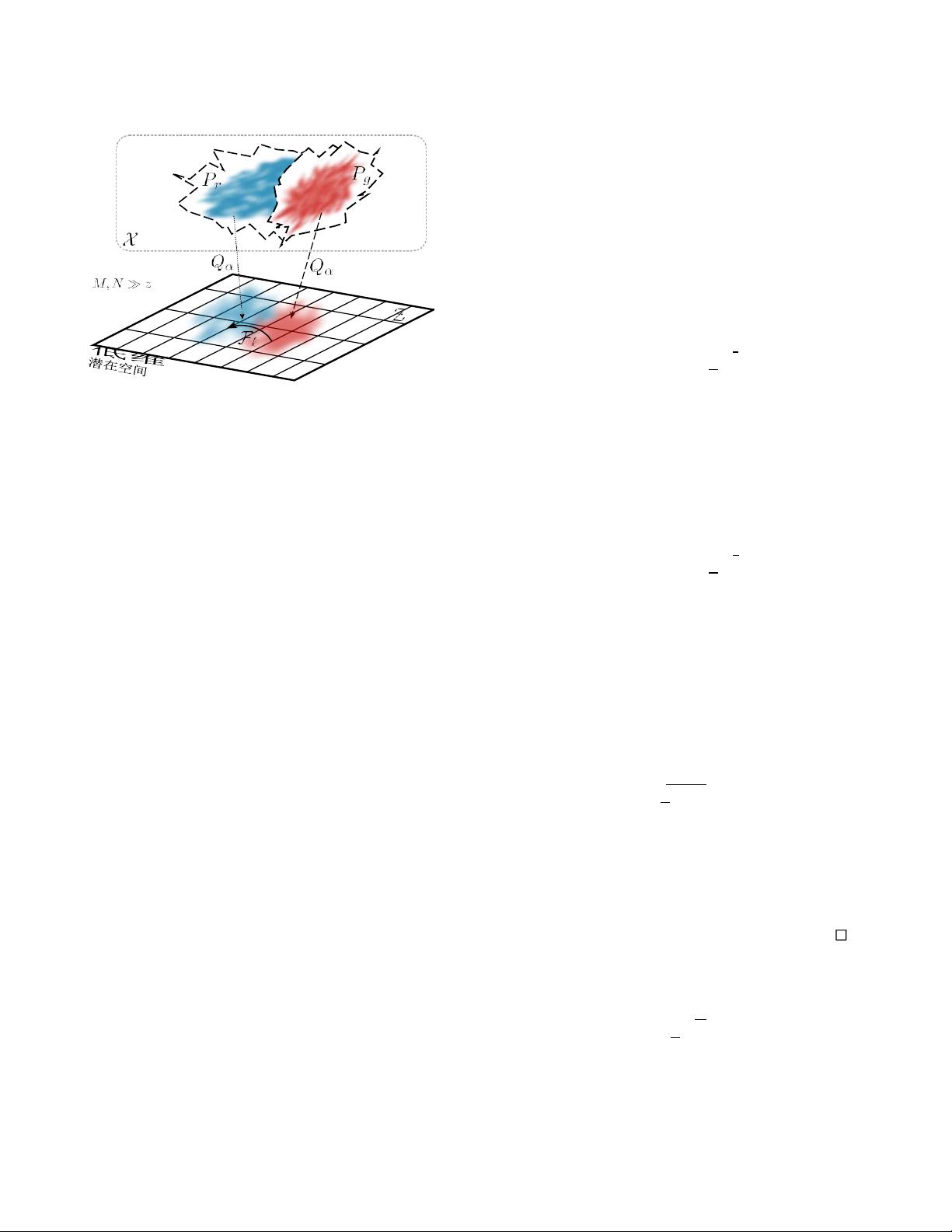
图1:数据分布P
r
和模型分布P
g
在空间X中都是高维和
紧凑的。在实际设置中,利用有限样本大小来保持这
些分布之间的最佳耦合会受到弱收敛速度的影响。将
两个分布(映射Q
α
)投影到潜在空间Z上,可以提高
收敛速度,并更好地估计Wasserstein距离。在这个空
间中估计Wasserstein距离包括学习潜在分布之间的概
率变换
F
匹配操作
实际上,对于R
d
上的概率测度,当空间d的维数变大
时
,
到
P
收缩,需要更多的样本
来产生适用的收敛速
率。最近[37]推广了[8]的原始渐近界。在这里,我们
展示了[37]的简化版本。
定理1.
设
k∈[1
,
∞).
经验分布向
k
阶
Wasserstein
距离
的收敛速度由下式给出:
潜在分布用作匹配分布P、P的总体目标的指导。
E
[
W
(
P
,
P
)
]
4
.
Σ
1
1
个
d
r g
k n
n
在
[37]
中给出了完整的证明。
(七)
其中G、D是由θ
、
ω和
Pr
、
Pz
是数据分布和噪声分布,
d
b
.
我们将收敛速度积定义为:
分 别 为 。 在 [2] 中 , 使 用 权 重 裁 剪 来 保 持
D
上 的 1-
Lipschitz约束;最近[13]对此进行了扩展,其中使用梯
度惩罚来强制Lipschitz约束。在这项工作中,我们将
展示如何在方程的原始形式。2计算明确的潜在的代表
的数据被用作正则化,以指导发电机组件在方程。4.
第一章
1. 提 案
让 我 们 定 义 分 布
Pr
,
其 中 随 机 变 量
X
∈ X
<$R
dr
,
Pz
作为其潜在编码的分布,其中潜在随机变
量
Z
∈ Z <$R
dz
,
{
<$
dr
,
dz
∈
Z
+
:
dz
≤
dr
}
。 给定相应
的经验分布
P
′
,
P
′
以及
其相关的收敛速率则:
3.
关于Wasserstein分布
Zeroz
4
.
D
R
+
D
Z
1
d
r
d
z
n
(
八
)
tance
[12]的工作表明,给定数据分布
Pr
和足够的建模能
力,GAN设置中的生成器恢复与数据分布
Pr
匹配的模
型分布P
g
。为了补充这一发现,[24]提供了
其中,
Rz
是
n
个样本的收敛速率乘积。
证据
获得经验分布
P
′
,
P
′
通过应用定理
1
。
强有力的证据表明
,
位于低维流形
r z
上
[1]进一步严格证明了
Pr
和Pg
都
位于低维流形上.我们的
GAN框架构建了一个潜在代表的最佳传输正则化器,
通过检查Eq. 8,可以立即观察到,对于
drd
z
,收敛
积由
项
dz
,
即
:
sentation,旨在帮助稳定训练,从而更好地估计真实分
布(参见图1)。①的人。
Zeroz
4
.
Σ
1
1
d
z
n
(
九
)
n维
歧管
m维
歧管
z维
歧管
剩余11页未读,继续阅读
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 自动生成CAD模型文件的测试流程
- 掌握JavaScript中的while循环语句
- 宜科高分辨率编码器产品手册解析
- 探索3CDaemon:FTP与TFTP的高效传输解决方案
- 高效文件对比系统:快速定位文件差异
- JavaScript密码生成器的设计与实现
- 比特彗星1.45稳定版发布:低资源占用的BT下载工具
- OpenGL光源与材质实现教程
- Tablesorter 2.0:增强表格用户体验的分页与内容筛选插件
- 设计开发者的色值图谱指南
- UYA-Grupo_8研讨会:在DCU上的培训
- 新唐NUC100芯片下载程序源代码发布
- 厂家惠新版QQ空间访客提取器v1.5发布:轻松获取访客数据
- 《Windows核心编程(第五版)》配套源码解析
- RAIDReconstructor:阵列重组与数据恢复专家
- Amargos项目网站构建与开发指南
