部分输入场景级FG-SBIR:优化与性能提升
182 浏览量
更新于2025-01-16
收藏 15.5MB PDF 举报
本文主要探讨了部分输入在场景级Fine-Grained Sketch-Based Image Retrieval (FG-SBIR)方法中的挑战及其性能改进。作者注意到在场景级草图研究中,一个关键的现象是大部分草图并非完整地捕捉照片中的所有内容,而是存在主观的全局解释和对象级别的抽象,导致空白区域广泛存在。这使得现有的FG-SBIR方法在处理越来越部分化的场景草图时表现不佳。
传统上,研究集中在对象级别草图的抽象性、创造性、图像检索和三维合成等方面。然而,随着技术的发展,场景级分析逐渐成为研究热点。场景草图不仅抽象于单个对象,还涉及整个场景布局,如图1(a)所示,随机叠加的草图与照片对比明显。
为解决这一“部分”问题,论文提出了一种基于最优传输(Optimal Transport,OT)的方法,旨在以部分感知的方式建立跨模态区域关联性。传统的OT方法被改进,引入了整体部分性的考虑,通过比较内模态的邻接矩阵来增强模型的鲁棒性。这种方法不仅能够有效处理部分场景草图,还在现有数据集上实现了最先进的性能,证明了其在实际应用中的有效性。
图1(b)展示了现有FG-SBIR方法在面对部分化场景草图时的困境,而图1(c)则强调了大量空白区域的存在,例如对于场景中的绵羊草图,可能会造成匹配困难。因此,这篇论文的贡献在于提出了一种创新的方法,有望推动场景级FG-SBIR领域的研究,提高在实际场景中处理不完整草图的准确性和效率。
2397
0
卷积网络在很大程度上通过过滤现有数据集[24]中具有太少
前景实例(即部分草图)的方式避免了部分草图的挑战性设
置。与[44]不同,我们提出了一个场景级FG-SBIR设置,该
设置对于缺乏实例级草图-照片对之间对齐、位置对应的“
部分”草图的更现实的设置具有鲁棒性。处理部分数据研究
不完整或部分数据的一个繁荣领域是图像修复[71,85,
89],其目标是通过在整体区域上进行条件建模来生成(或
填充)缺失(或遮蔽)区域。在草图的背景下,有两个广泛
的工作方向:(a)两阶段流水线首先尝试通过基于图像到
图像转换的条件分布建模来完成部分草图[30,
65],然后执行特定任务的目标,如识别[43]或草图到图像[2
8]生成;(b)单步骤框架[9]直接处理不完整的草图以执行
特定任务的目标。与Bhu-
nia等人[9]类似,我们的方法是一个能够处理不完整或部分
草图的单步骤框架。虽然现有的文献[9,
43]研究了对象级部分草图,但我们专注于场景级检索的新
颖设置。应用最优传输学习结构相似性而无需显式对齐信息
,使得线性优化中的最优传输[70]成为几个下游任务[35,38,
45,61,
84]的重要工具。Rubner等人[56]使用地球移动距离作为基
于颜色和纹理的图像检索的度量,其具有运输问题的公式。
后来的工作将最优传输扩展到深度学习领域,用于文档分类[
33]、少样本学习[80]、领域自适应[17]、自监督学习[45]、
神经机器翻译[75]和从单目数据中理解场景使用3D点云[35]
。在这项工作中,我们首次研究了将最优传输应用于设计区
域级关联性的可微距离度量函数,而无需任何显式的对齐标
签,并通过三元组排序目标端到端训练一个跨模态检索系统
。学习无监督的区域级对应关系从两个或多个输入数据中匹
配相同或相似的结构/内容是各种下游应用[47,
81]中的一项基本任务,例如图像拼接[10]、图像融合[48]、
共分割[23,
76]、图像检索[88]、对象识别[73]和跟踪[74]。区域级对应
关系可以通过监督[69,77,83]、自监督[18,39,
82]或无监督方式[3,27,34,51,
60]进行学习。自监督和无监督方法在训练时不使用任何人
工注释,只使用几何[31]或语义[46]约束。与这些工作相比
,据我们所知,我们首次尝试将无监督的区域级关联性的能
力应用于跨模态检索。
0
空区域
0
在草图中
0
全局特征(草图,
照片)
0
邻接矩阵比较
0
(草图,照片)
0
基线
0
提出的
0
编码器
0
局部特征
0
全局平均池化
0
区域级最优传输
0
带权重的邻接矩阵比较
0
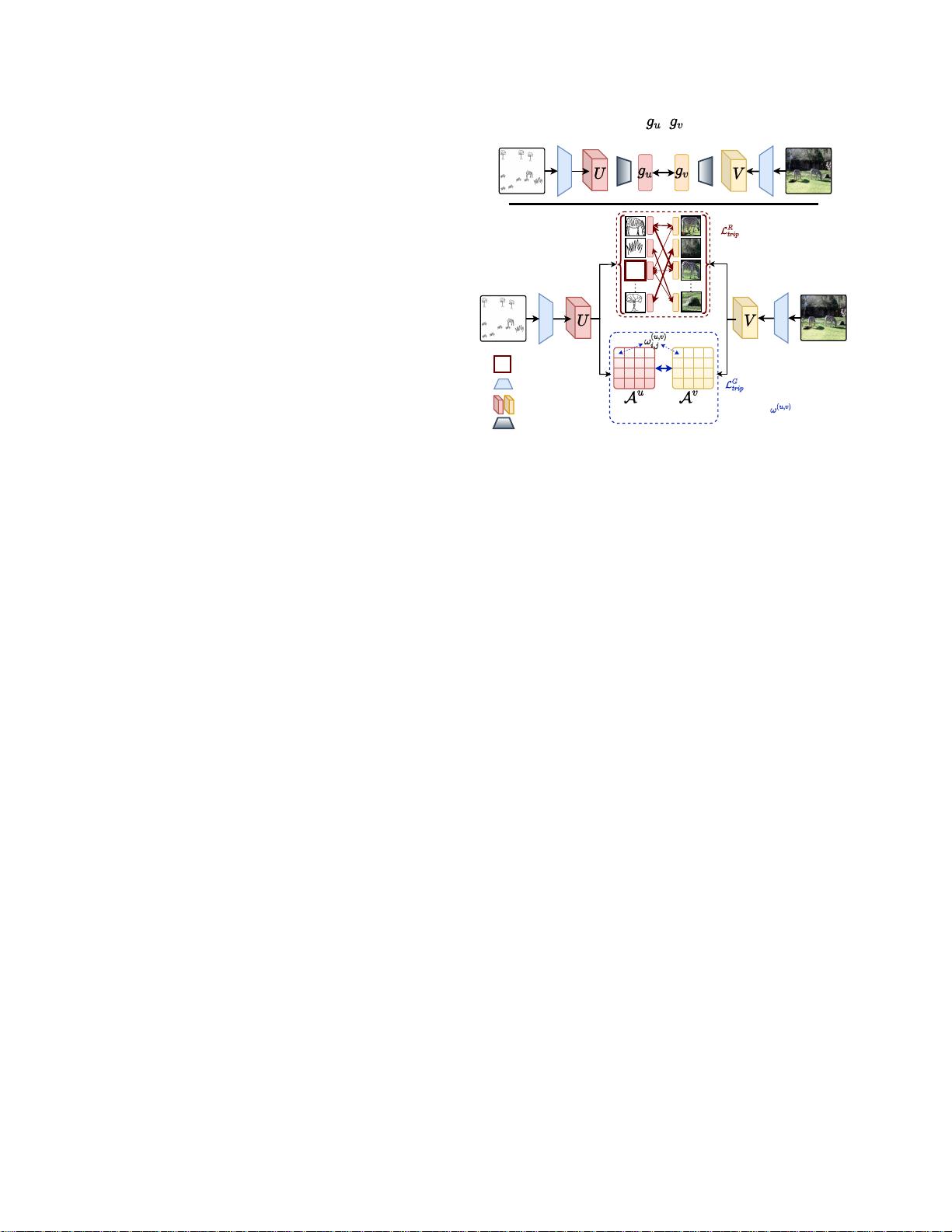
图2.
我们提出的场景级FG-SBIR方法的示意图。现有的基线通常在卷积
特征图上使用全局平均池化(GAP)。这会丢失对于“部分”场景
草图所必需的局部区域特定特征表示。我们提出的方法通过以下方
式解决这个“部分”问题,即:(i)使用最优传输的局部特征图的
集合距离(LR
trip);(ii)加权的跨模态比较区域邻接矩阵以捕捉整体场景配置
(LGtrip)。
0
在端到端可训练的框架中的模态设置。
0
3.提出的方法
0
我们的目标是检索满足部分草图查询约束的场景图像
。现有的基于全局特征向量的表示通常通过全局平均
池化[42]获得,忽略了这种部分关联性约束,因此无
法忠实地从部分草图中检索场景图像。本文旨在通过
比较每个草图-照片对之间的相应区域特定特征来建模
部分关联性,通过一种新颖的端到端可训练的度量学
习损失,使模型能够从部分草图中检索。3.1.
基线检索框架
0
首先,我们简要总结了一个基准检索框架,该框架在SBIR文献中仍然是最先进的。给定一
个表示为(S,I)的草图-照片对,使用由θ参数化的特征提取器Fθ(∙)来获取特征图U=
Fθ(S)∈RhS×wS×c和V=Fθ(I)∈RhI×wI×c,分别用于草图和照片。
Fθ可以由CNN[78],LSTM[36],Transformer[41],Graphs
[44,55,65]或它们的组合[5]建模。我们将骨干输出特征图U∈RhS×wS×c和V∈RhI×wI
×c展平为:u={u1,...,um}和v={v1,...,vn},其中m=hsws,n=hIwI,ui,v
i∈Rc。Rc的每个大小的向量
剩余10页未读,继续阅读
261 浏览量
点击了解资源详情
点击了解资源详情
2021-03-19 上传
333 浏览量
126 浏览量
197 浏览量
2022-12-16 上传
2021-04-01 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 普天身份证阅读器新版二次开发包发布
- C# 实现文件的数据库保存与导出操作
- CkEditor增强功能:轻松实现图片上传
- 掌握DLL注入技术:测试工具使用与探索
- 实现带节假日农历功能的jQuery日历选择器
- Spring循环依赖示例:深入理解与Git代码仓库实践
- ABB PLC液压阀门控制程序开发指南
- 揭秘4核旋风密版626象棋引擎的超牛实力
- HTML5实现的经典游戏:小霸王坦克大战源码分享
- 让Visual Studio兼容APM硬件信息的方法
- Kotlin入门:创建我的第一个应用
- Android语音识别技术研究报告与应用分析
- 掌握JavaScript基础:第8版教程源代码解析
- jQuery制作动态侧面浮动图片广告特效教程
- Android PinView仿支付宝密码输入框源码分析
- HTML5 Canvas制作的围住神经猫游戏源码分享
