元学习驱动的情感识别:应对遮挡、姿势和光照变化
PDF格式 | 1.3MB |
更新于2025-01-16
| 150 浏览量 | 举报
"这篇学术论文探讨了基于元学习的情感识别方法在面部表情识别中的应用,特别是在处理部分遮挡、不同头部姿势和光照条件等现实世界挑战时的效果。研究使用了原型网络的元学习策略,这种方法适合处理少量样本的少数类问题,能有效防止过拟合。论文介绍了名为ERMOPI(情感识别使用Meta-learning across Occlusion,Pose and Illumination)的新方法,该方法在CMUMulti-PIE数据集上进行训练和评估,并在AffectNet数据库上测试其对类内和数据集间变化的适应性。ERMOPI的优势在于需要较少的训练样本,同时在部分遮挡、不同头部姿势和光照条件下仍能保持鲁棒性,其在CMUMulti-PIE上的准确率为90%,在AffectNet上的准确率为68%。"
本文详细介绍了面部情绪识别的重要性和应用领域,如人机交互、医疗保健、虚拟助手等。自动情感识别(ER)是一个关键的技术挑战,尤其是在现实环境的复杂性下,例如面部可能被部分遮挡,个体可能呈现各种头部姿势,或者在不同的光照条件下。传统的机器学习和深度学习模型在这些情况下往往表现不佳,主要是因为训练数据中缺乏这些条件的样本。
为了解决这个问题,研究者引入了元学习的概念。元学习是一种机器学习策略,它允许模型从有限的样本中快速学习并适应新任务。具体来说,他们采用了基于度量的元学习方法,即原型网络。原型网络能够在少数样本中建立有效的表示,避免了过拟合,尤其适用于处理小样本问题。通过这种方法,ERMOPI能够针对部分遮挡、头部姿势变化和光照条件变化进行情感识别。
实验部分,研究人员使用了CMUMulti-PIE数据集进行模型训练和评估。这个数据集包含了各种遮挡、头部姿势和光照条件,非常适合验证模型在复杂情况下的性能。此外,他们还使用了AffectNet人脸数据库来进一步测试模型的泛化能力和适应性。实验结果表明,ERMOPI方法在两个数据集上都达到了较高的识别准确率,验证了其有效性和实用性。
这项工作展示了元学习在解决面部表情识别难题中的潜力,尤其是当面临现实世界中的变异性时。ERMOPI方法的成功表明,采用元学习策略可以显著提高模型在资源有限情况下的表现,这对于开发更适应实际场景的情感识别系统具有重要意义。
S. Kuruvayil
和
S.
帕拉尼斯瓦米
沙特国王大学学报
7273
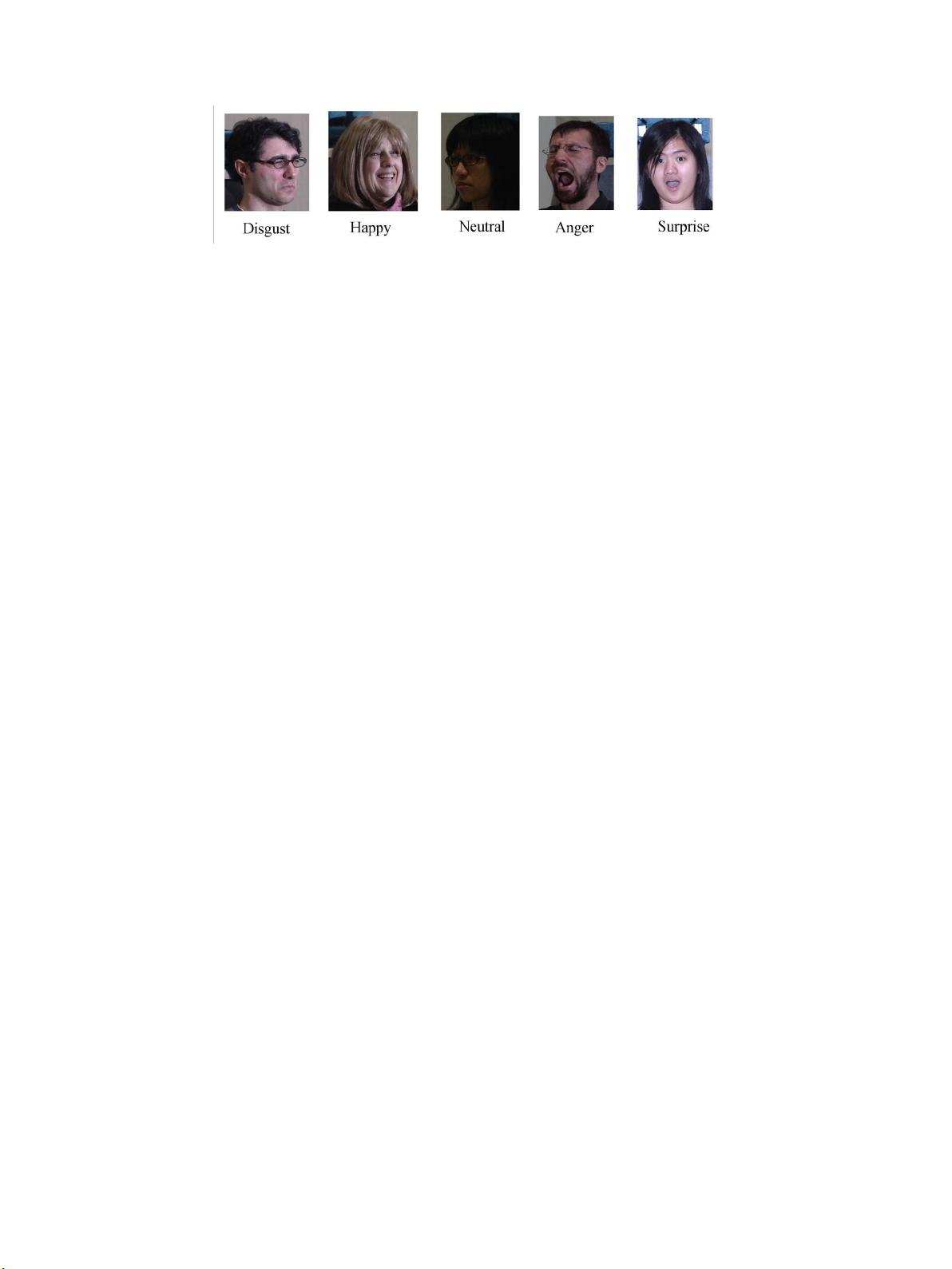
图1.一、来自CMU Multi-PIE的具有遮挡、姿态和照明变化的样本图像
即使使用具有固定头部姿势和照明水平的图像的实验室数据集进行
训练,该模型也表现出对具有任意头部姿势、照明、颜色和对比度
的图像的适应能力。也就是说,ERMOPI表现出比传统机器学习或
深度学习模型更好的泛化能力。
该模型能够适应未经训练的野生数据集中的图像,这些图像在表达
情感时具有类内变化,尽管它是用具有可忽略的类内变化的图像训
练的。为此,该模型仅需要来自新数据集的大量图像来形成支持集
图像。也就是说,ERMOPI支持少量情绪学习。
该模型能够从图像中的多个人脸中检测和执行情感识别,并用相
应的情感标记其中的每一个。
本文的其余部分组织如下:第2节解释了在各种真实世界场景下情感
识别领域的相关工作。它还探讨了一些使用元学习进行少量分类的方
法 。用于工 作 的 数 据 库在第 3 节 中 介绍 。在第4节 中 , 我 们 的 方法
ERMOPI详细介绍了模型架构和实施步骤。结果和分析见第5。结论和
未来的工作在第6中讨论。
2.
相关工作
本节简要介绍了以前在真实场景下的情感识别方面的一些工作,
它们的局限性以及用于少数镜头分类的各种元学习方法最后指出了选
择基于元学习的方法的优点。
2.1.
真实世界场景
在本节中讨论了在各种真实世界条件下从静止图像中识别情感的早
期方法,例如部分遮挡,变化的头部姿势和照明水平。
RPCA对缺失数据和离群值具有鲁棒性,用于部分遮挡的面部图像的
情感识别(Cornejo和Pedrini,2017)。利用RPCA重构特征后,提取
Gabor小波和几何特征。作者在三个面部表情数据集上评估了他们的方
法,即CK+,JAFEE和MUG。由于数据集中缺少部分对于CK +数据
库,该方法使用PCA + LDA + KNN和特征组合(即,LBP、HOG和
Gabor描述子。自然遮挡的实验在这项工作中没有报道,而在ERMOPI
中考虑了面部的自然遮挡。此外,提到了RPCA对丢失数据是鲁棒的,
但是在图1中没有探索照明和姿态变化。
这与ERMOPI不同。通过线性组合属于每个测试图像的类的训练图像来
形成稀疏表示(Cotter,2010)。实验通过使用放置在面部图像上的黑
色和白色盒子人工创建遮挡来进行。关键的发现是,识别率取决于用于
遮挡面部部分的盒子的颜色。该方法未对自然遮挡进行评估,也未考虑
姿态和照明变化。在指定角度的Radon变换用于将被遮挡的面部图像投
影到一维函数信号上(Ali等人,2018年)。在这项工作中,被遮挡的
纹理特征恢复使用高阶光谱(HOS)或二阶统计称为双谱。双谱能够捕
捉到人脸的纹理和轮廓信息. CK数据库用于训练和测试。对于上面部的
遮挡,该方法的准确率达到91.3%。在(Mao等人,2017),开发了贝
叶斯模型来执行多姿态FER。该方法在CMU Multi-PIE数据集上取得
了90.24%的准确率。
所有上述机器学习方法都可以在上述数据集上获得超过90%的准确
率,但它们处理遮挡或姿态,但不能同时处理遮挡、姿态和光照变化。
此外,研究咬合的工作使用了合成咬合来证明结果。
深度学习模型在现实生活场景中为
FER
提供了有希望的结果 具有
2
个卷积层和
4
个初始层的深度学习模型在
CMU Multi-PIE
数据集上实
现了
94.70%
的最新准确度(
Mollahosseini et al.
,
2016
年)。初始
层提供了稀疏网络的近似,从而减少了过度拟合和增加计算需求的问
题基 于
GAN
的方 法用 于多视 图 图 像的面 部正 面化(
Lai
和
Lai
,
2018
) 以 及 联 合 姿态 和 表 情 建 模 。 在使用堆叠卷 积 自 动 编 码 器
(
SCAE
)和渐进贪婪逐层算法(
Webb
等人,
2020
年)。
SCAE
模
型首先在
CMU Multi-PIE
上进行预训练,以提高图像亮度并减少面
部姿势。预训练的模型在来自许多基线面部数据集的大型数据库上进
行了微调该模型在现实生活环境中看不见的图像上产生了
79.5%
的准
确率。在(
Palaniswamy
和
Tripathi
,
2018
)和(
Suja
等人,
2016
年)。具有注意力机制的
CNN
(
ACNN
)用于构建遮挡感知面部情
绪识别系统(
Li
等人,
2019
年)。这项技术部署了门单元,将注意
力从被遮挡的面部转移到未被遮挡的面部区域。作者在
RAF-DB
和
AffectNet
等各种野外数据集
以及CK+、MMI、Oulu-CASIA和SFEW
等实验室数据集
上评估了他们的模型。
ACNN
的性能取决于模型中人
脸标志点定位模块的准确性对于合成遮挡图像,
RAF-DB
的准确率为
80.54%
,
AffectNet
的准确率为
54.84%
。进行了一项工作,以解决
与各种类别的数据不平衡有关的问题(
Ngo
和
Yoon
,
●
●
●
剩余11页未读,继续阅读
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
