视觉语言注意学习驱动的文本反馈图像搜索
63 浏览量
更新于2025-01-16
收藏 2.84MB PDF 举报
"带有视觉语言注意学习的图像搜索"
在计算机视觉和自然语言处理领域,"带有视觉语言注意学习的图像搜索"是一个新兴的研究方向,它旨在结合图像和文本信息,以实现更精确、更具针对性的图像检索。这个任务在电子商务、搜索引擎优化等领域具有巨大的潜力,因为它允许用户通过提供额外的文本反馈来细化搜索结果,更好地满足他们的需求。
视觉语言注意学习(Visual Language Attention Learning, VAL)框架是解决这一问题的关键。在这个框架中,研究者提出了一种复合Transformer结构,该结构能够被无缝地集成到卷积神经网络(CNN)中。Transformer因其在序列建模中的优异性能而被广泛采用,尤其是对于理解和生成文本。在VAL中,Transformer被用来处理语言输入,同时与CNN的视觉特征相结合,形成一个能够理解图像和文本之间协同关系的模型。
复合Transformer的设计目的是有条件地保留和转换视觉特征,这些特征与用户提供的文本反馈相匹配。通过在CNN的不同层次插入多个这样的Transformer,模型能够捕获不同粒度的语义信息,从而生成用于有效图像搜索的丰富表达。这种方法的优点在于,它能够处理不同类型的文本反馈,包括具体的属性描述和更抽象的概念。
例如,当用户希望将搜索结果中的黑色物品改为粉红色或者要求浅色的花卉图案时,这种视觉语言注意学习的模型可以理解这些文本指令,并据此调整搜索结果。通过在Fashion200k、鞋类和FashionIQ等数据集上的广泛评估,研究人员证明了该模型在处理各种文本反馈时超越了现有方法,无论是属性修改还是自然语言描述。
这一工作不仅提升了图像搜索的精度,还为未来的交互式图像检索系统设计提供了新思路。它强调了用户反馈的重要性,并展示了如何通过有效的视觉语言模型来利用这些反馈来改进搜索体验。随着深度学习和多模态技术的进步,我们可以期待未来图像搜索和相关应用将变得更加智能和用户友好。
3003
R
R
sa
我
S
P
ch
V
L
有一个肩带和
灰色
LSTM FC
(b)文本编码器
转置
A
i
K
语义学
1×1×
`
不
softmax
Q
h
i
w
i
×
h
i
w
i
o
我
低
层
中层
高层
F
C
x
i
F
V
i
A
我
h
i
×
w
i
×
1
sa
科沃
岛
我
参考图像
(d)分层配对
vl
sp
x
i
h
i
×w
i
×c
i
F
O
ja
Ⓢ
A
i
Ⓢ
低
层
中层
R
高层
ja
ch
A
我
1
×
1
×
c
i
目标图像
(a)图像编码器
(c)复合Transformer
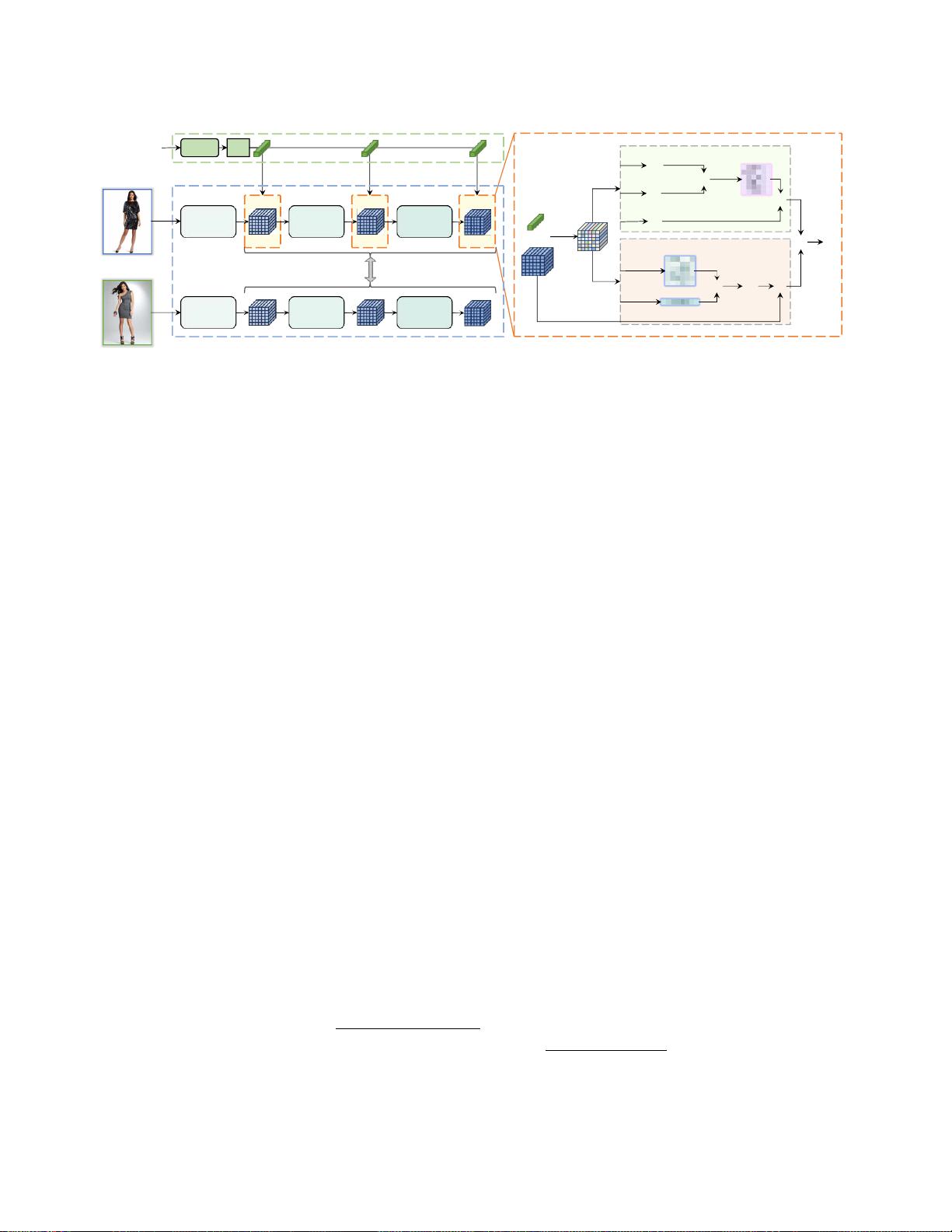
图
2.
本文概述了我们的视觉语言学注意力学习(
VAL
)框架。给定一对
参考图像
和
文本
作为输入,我们的目标是学习它们的复
合表示,该复合表示专门与
目标图像
表示对齐。VAL包含三个主要组件:(a)图像编码器和(b)文本编码器(Sec. (3)变
压器(第3.1节); 3.2)插入不同的卷积层,组成视觉和语言内容。所有组件都通过(d)分层匹配(第二节)进行协同优化
3.3
)。符号、、分别代表阿达玛积、矩阵乘法和元素加法。
3.
视觉语言注意学习
图2呈现了我们的V语言注意力学习(VAL)框架的
概述。给定一个
参考图像
和
用户文本
作为输入查询,
VAL的最终目标是学习一个专门与
目标图像
表示对齐
的复合表示 VAL包含三个组件:(a)图像编码器,
(b)用于视觉和语言表示学习的文本编码 器;以及
(c)多个复合变换器,其以不同的深度将语言语义吸
收到视觉特征图中。所有组件都通过分层匹配目标以
端到端的方式进行联合优化我们首先概述第二节中的
两个3.1,然后在第二节中详细阐述我们的关键成分和
模型优化。第3.2节三点三
3.1.
表示图像和文本
图像表示。为了将视觉内容封装成有区别的表示,我
们采用图像编码器,即。一个标准的CNN,用于图像
表示学习。由于CNN固有地学习以组成的层次顺序增
加抽象的视觉概念[5,31,78],我们推测来自单个卷
积层的图像特征不会捕获不同粒度的视觉信息。因
此,我们从多个卷积层中提取特征图,以构建一个内
置的 特 征金 字塔[33],以 实 现更 具表现力 的 表示 学
习。具体地,特征金字塔F由下式获得:
包含从
低
、
中
、
高级
卷积层
1
提取的多级特征图x
L
、
x
M
、
x
H
。
文本表示。为了表示文本的语义,我们利用文本编码
器将
用户文本
T映 射到 矢量化的文本表 示中 。形 式
上,文本编码器被实现为LSTM,然后是最大池化和
线性投影层。简而言之,我们首先对文本应用基本的
tokenising,然后将token序列输入文本编码器以获得最
终的文本表示:t ∈R。
3.2.
复合Transformer
为了联合表示图像和文本,我们建议
转换
和
保存
的
视觉特征的语言语义的条件。受transformer [64]在多模
态学习[23,35]中的优越性的启发,我们设计了一个
复合Transformer,插入CNN内部的多个级别我们的核
心思想是通过
注意力转换
和基于
语言学特征的
学习来
学习图像和文本的复合表示(图2(
c
)),最终目标
是为视觉搜索封装基本的视觉和语言内容,我们将在
下面描述。
视觉语言表征为了消化来自视觉和语言领域的信息
流,首先融合参考图像特征
Fr
和文本特征
t
,得到语
义语言表示。形式上,对于特征图
x
i
(其中
i
=
L
,
M
,
H
是特征金字塔中的级别),多
CNNθ中的三个不同层次
CNN
:
模态融合是通过与文本的连接来实现的
特征
t
,然后是复合函数
F
c
,以学习
F
r
=
{x
L
,
x
M
,
x
H
}
=θ
CNN
(I
r
)
融合的多语言特征
x
i
:
r r r vl
F
t
={x
L
,
x
M
,
x
H
}
=
θ
CNN
(I
t
)
t t t
X
i
=
F
c
(
[
x
i
,
t
]
)
(
1
)
这里,I
r
、
I
t
是指
参考图像
和
目标图像
;
F
r
、
F
t
是其对应的特征金字塔,每个
1
参考
补充材料
了解更多架构细节。
我
剩余11页未读,继续阅读
2021-02-16 上传
2021-04-01 上传
2023-07-02 上传
点击了解资源详情
190 浏览量
305 浏览量
292 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易酷免费影视系统:开源网站代码与简易后台管理
- Coursera美国人口普查数据集及使用指南解析
- 德加拉6800卡监控:性能评测与使用指南
- 深度解析OFDM关键技术及其在通信中的应用
- 适用于Windows7 64位和CAD2008的truetable工具
- WM9714声卡与DW9000网卡数据手册解析
- Sqoop 1.99.3版本Hadoop 2.0.0环境配置指南
- 《Super Spicy Gun Game》游戏开发资料库:Unity 2019.4.18f1
- 精易会员浏览器:小尺寸多功能抓包工具
- MySQL安装与故障排除及代码编写全攻略
- C#与SQL2000实现的银行储蓄管理系统开发教程
- 解决Windows下Pthread.dll缺失问题的方法
- I386文件深度解析与oki5530驱动应用
- PCB涂覆OSP工艺应用技术资源下载
- 三菱PLC自动调试台程序实例解析
- 解决OpenCV 3.1编译难题:配置必要的库文件
