"ACL 2022:将预训练语言模型与手工特征结合的无监督词性标注"
PDF格式 | 18.83MB |
更新于2025-01-16
| 174 浏览量 | 举报

327
0
计算语言学协会发现:ACL
2022,第3276-3290页,2022年5月22日至27日,计算语言学协会c2022
0
将预训练语言模型和手工特征结合起来进行无监督词性标注
0
周厚权,李阳,李正华,张敏,苏州大学计算机科学与技术学院人工智能研究所,中国{hq
zhou,ylinlp}@stu.suda.edu.cn;{zhli13,minzhang}@suda.edu.cn
0
摘要
0
近年来,大规模预训练语言模型(PLMs)在大
多数自然语言处理任务中取得了非凡的进展。
但是,在无监督词性标注任务中,利用PLMs的
研究工作很少,并且未能达到最先进的性能(S
OTA)。最近的SOTA性能是由He等(2018)
提出的一种高斯HMM变体实现的。然而,作为
一种生成模型,HMM做出了非常强的独立性假
设,这使得很难将PLMs的上下文化词表示纳入
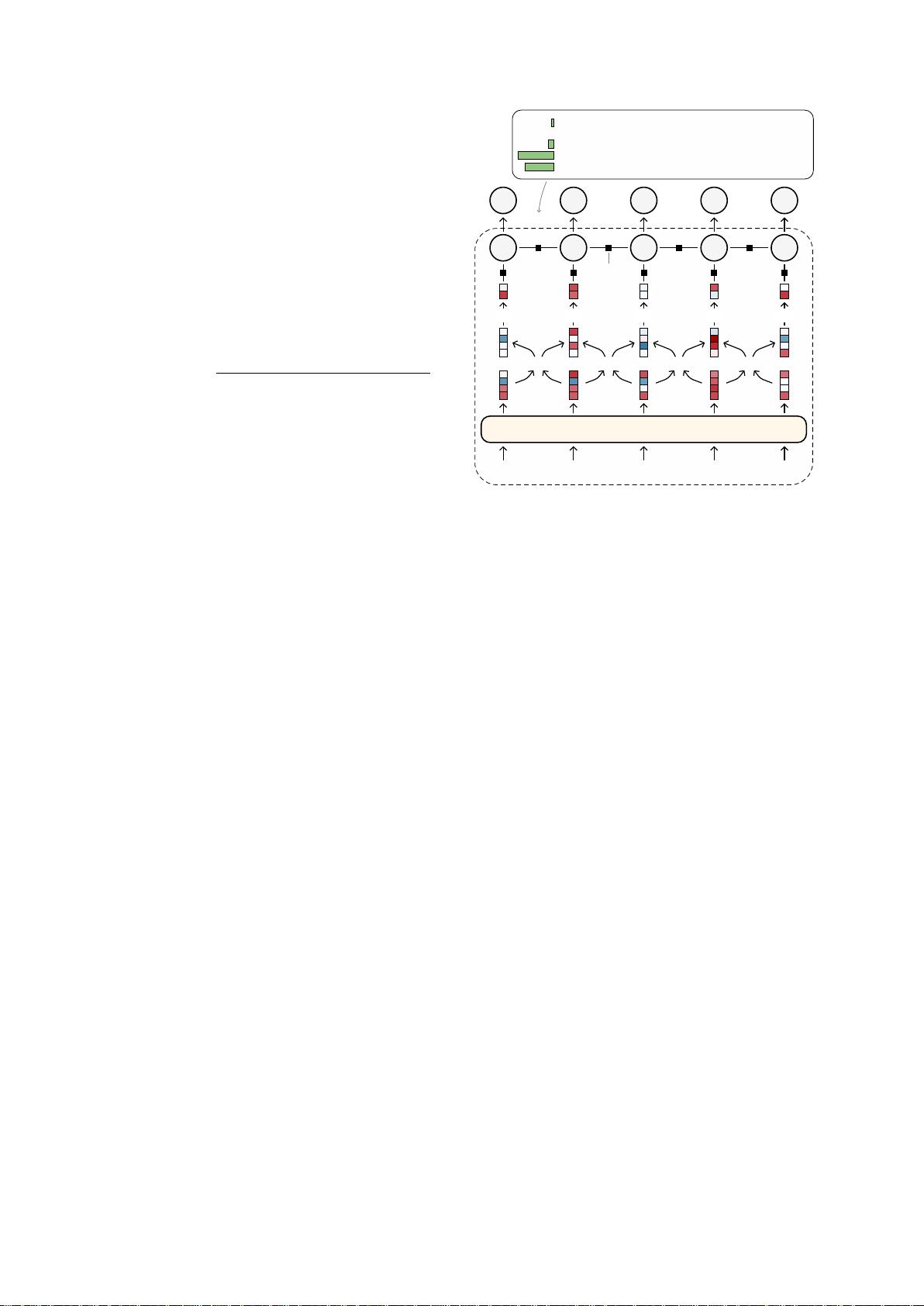
其中。在这项工作中,我们首次提出了一种用
于无监督词性标注的神经条件随机场自编码器
(CRF-AE)模型。CRF-AE的判别式编码器可
以直接纳入PLM词表示。此外,受到特征丰富
的HMM的启发,我们将手工特征重新引入CRF
-AE的解码器中。最后,实验证明我们的模型在
Penn
Treebank和多语言通用依存树库v2.0上的性能
明显优于先前的最先进模型。
0
1引言
0
无监督学习一直是自然语言处理中一个重要且具有
挑战性的研究方向(Klein和Manning,2004;Lia
ng等,2006;Seginer,2007)。直接从无标注
数据中训练模型可以减轻痛苦的数据标注工作,因
此对于资源匮乏的语言尤其具有吸引力(He等,2
018)。作为句法分析的三个典型任务,无监督词
性(POS)标注(或诱导)、依存句法分析和短语
结构句法分析在过去三十年中吸引了广泛的研究兴
趣(Pereira和Schabes,1992;Christodoulopo
ulos等,2010)。与树结构依存和短语结构分析相
比,词性标注对应于更简单的顺序结构。
0
周厚权和杨阳对本文贡献相等。李正华为通讯作者。
0
我看了看我的手表。
0
代词过去式动词介词代词所有格名词。
0
图1:词性标注示例。
0
简单来说,无监督词性标注任务旨在将一个词分配
一个词性标签,如图1所示。除了减轻标注数据的
负担外,无监督词性标注对于儿童语言习得研究尤
为有价值,因为每个孩子都能在没有标注数据的情
况下诱导出句法类别(Yuret等,2014)。
0
现如今,基于大规模标注数据训练的监督式词性标
注模型已经能够达到极高的准确率,例如在英文Pe
nn
Treebank(PTB)文本上可以达到97.5%以上的准
确率(Huang等,2015;Bohnet等,2018;Zho
u等,2020)。然而,无监督词性标注虽然吸引了
很多研究兴趣(Lin等,2015;Tran等,2016;H
e等,2018;Stratos,2019;Gupta等,2020)
,但在多对一(M-1)准确率上最多只能达到80.8
%,其中M-1表示在测试数据上评估模型时,多个
诱导标签可以映射到一个单一的真实标签。
0
生成式隐马尔可夫模型(HMMs)是无监督词性
标注最具代表性和成功的方法(Merialdo,1994
;Graça等,2009)。通过将词性标签视为潜变
量,一阶HMM将句子和标签序列的联合概率p(x
,y)分解为独立的发射概率p(xi∣yi)和转移概
率p(yi−1∣yi)。训练目标是最大化边缘概率p(
x),可以通过EM算法或直接梯度下降求解(Sala
khutdinov等,2003)。Berg-Kirkpatrick等(2
010)提出了一种特征丰富的HMM(FHMM),
它进一步使用许多手工特征参数化p(xi∣yi)。
0
+v:mala2277获取更多论文

剩余14页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机组成原理期末试题及答案(2011参考)
- 均值漂移算法深入解析及实践应用
- 掌握npm与yarn在React和pg库中的使用
- C++开发学生信息管理系统实现多功能查询
- 深入解析SIMATIC NET OPC服务器与PLC的S7连接技术
- 离心式水泵原理与Matlab仿真教程
- 实现JS星级评论打分与滑动提示效果
- VB.NET图书馆管理系统源码及程序发布
- C#实现程序A监控与自动启动机制
- 构建简易Android拨号功能的应用开发教程
- HTML技术在在线杂志中的应用
- 网页开发中的实用树形菜单插件应用
- 高压水清洗技术在储罐维修中的关键应用
- 流量计校正方法及操作指南
- WinCE系统下SD卡磁盘性能测试工具及代码解析
- ASP.NET学生管理系统的源码与数据库教程
