LISA:全方位手部神经模型,精准捕捉手部形状与外观
111 浏览量
更新于2025-01-16
收藏 2.32MB PDF 举报
"LISA:内隐手形和手形的"
LISA,即无所不能的人手神经模型,是由Enric Corona等人提出的,旨在精准捕捉手部的形状和外观,并能推广到任意的手部子模型。这个模型利用多视图RGB视频数据集进行训练,其中包含了大致标注的3D手部姿势。LISA的独特之处在于它能够实现形状、颜色和姿态的分离表示,允许对特定手部参数进行精细控制。
LISA模型基于铰接式的隐式表示,它可以预测每个骨骼相对于局部手部坐标的3D颜色和有符号距离。这些预测通过预估的蒙皮权重进行组合,以生成完整的3D手部模型。蒙皮权重是显式预测的,这对于将不同骨骼的影响合并到最终的形状和外观重建中至关重要。通过这种方式,LISA能够从单目或多视图图像序列中重建动态手部,其形状和外观的重建质量显著优于现有的基线方法。
手部建模和跟踪在计算机视觉领域一直是一个重要的研究方向,因为手部是人类与环境交互的主要工具。传统的研究如MANO手部模型已经为这个领域打下了坚实的基础,但LISA模型的出现进一步提升了精度和鲁棒性,这对于人机交互、假肢设计以及虚拟和增强现实应用具有重大意义。
实验结果证明了LISA模型的有效性,它不仅能够准确地从单目或多个摄像头视角重建动态手部,而且在手的形状重建质量上表现出显著优势。这意味着LISA有可能成为未来手部追踪和建模技术的标准,为各种现实世界的应用提供更加精确和灵活的解决方案。项目页面提供了更多关于LISA模型的信息,包括源代码和进一步的研究成果。
20535
我
我
从多视图序列
预测每个骨骼的颜色和符号距离
局部骨坐
标
三维查
询点
组合每骨预测
边距
颜色
用户
ID
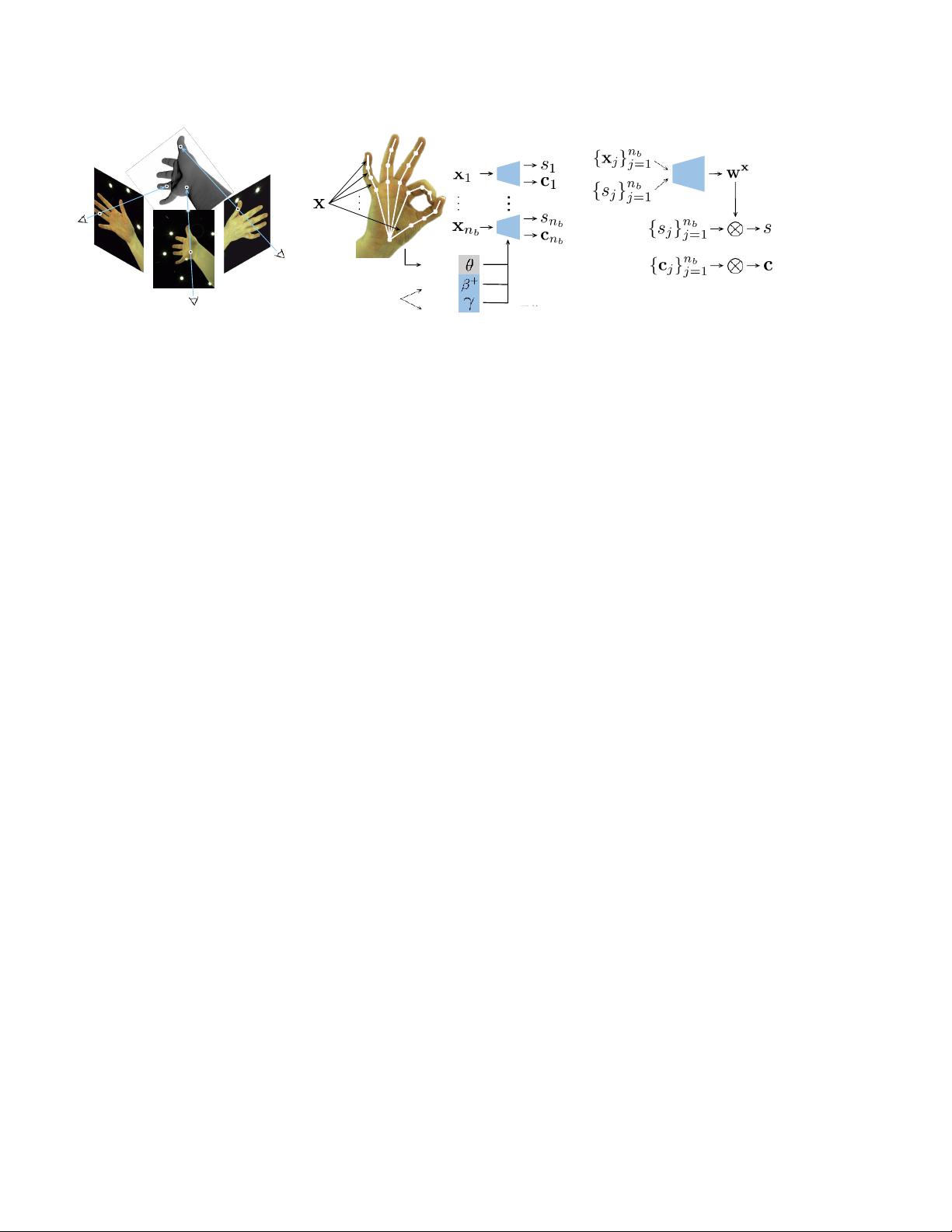
图2. LISA手部模型的训练和架构。
左:
LISA通过最小化多视图RGB图像序列数据集的形状和外观损失进行训练。假设序列用
在训练期间细化的手骨架的粗略
3D
姿势注释。训练序列显示多个人的手,并用于学习姿势,形状和颜色的分解表示。
中:
LISA通过手部骨骼定义的刚性部件集合来近似手部。将3D查询点变换到与独立神经网络相关联的骨骼的局部坐标系,该独立
神经网络预测与骨骼的有符号距离。
手的表面和颜色。注意,G
j
由两个独立的MLP实现,一个预测有符号距离,另一个预测
颜色(见
4.1
节)。
右图:
使用由其他
网络预测的蒙皮权重组合每个骨骼的预测。
基于交叉一致性损失。DiForm [62]在学习基于SDF的
形状嵌入时采用解码器网络来解开身份和变形。A-
SDF [39]因子化了形状嵌入和关节角度,以建模关节
化对象。NPM [45]提出在正则摆位扫描上训练形状嵌
入,然后用另一个网络学习具有密集监督的变形场。
i3DMM [67]采用了与变形场类似的想法来学习人类头
部模型。该方法解开身份,发型和表达,并与密集的
彩色SDF监督训练。在这项工作中,我们提出了一个
生成的手表示解开形状,姿态和外观参数。
3.
背景
MANO[53]将人手表示为姿态参数θ和形状参数β的函
数:
M
:(
θ
,
β
)
›→V
,
(
1
)
其中,手由具有
n
j
= 16
个关节的骨架
rig
定义,并且
姿态参数
θ
∈
R
n
j
×
3
表示
骨 架 的 骨 骼 之 间 的 相 对旋 转
的
轴角
表示。
β
是一个
10
维向量,
V∈
Rn
v
×
3
是三角
形网格的顶点。
通过线性混合蒙皮(
LBS
)变换对
标准手
Vr
进行变形来估计映射
M
,
权重
W ∈
Rn
b
×
nv
,其
中
nb
是骨骼的数量。
具体地,给定规范形状上的顶
点
v
r
,
LBS
如下变换顶点
Σ
n
b
v
i
=
w
i
,
j
T
j
v
<$
r
,
(
2
)
j
=1
其中,
T
j
∈R
3
×
4
是应用于
骨骼
j
的静止姿态
的刚性变
换
,
w
i
,
j
是
W
的
(
i
,
j
)
项,
v
<$
表示v的齐次坐标。LISA通过使用相同的姿势参数θ和
骨骼变换建立在MANO
NeRF/VolSDF。NeRF [35]是用于新颖视图合成的最先
进的渲染算法。该算法通过学习以下函数来对静态场
景的连续辐射场进行建模
F
:(
x
,
d
)
<$→
(
c
,
σ
)
,
(
3
)
其将3D位置x∈
R3
和通过x的观看方向d∈
R2
映射到颜色
值c∈
R3
及其密度σ∈R。函数F由多层感知器(MLP)网
络建模,该网络从单个静态场景的一组密集的多视图
构成的RGB图像训练。虽然NeRF已经展示了令人印象
深刻的新颖视图合成结果,但是估计的体积密度对于
推断准确的几何形状是无效的。一些最近的作品研究
了这个问题[42,60,65],并建议通过纳入SDF [46]来
扩展NeRF。在本文中,我们调整了VolSDF [65]的公
式,该公式将体积密度定义为应用于SDF表示的拉普
拉斯累积分布函数(CDF)。VolSDF还解开了几何和
外观学习使用两个MLP SDF和颜色估计,分别。
4.
LISA:提议的手部模型
本节提供了对所提出的手模型的详细描述,我们称
之为LISA用于学习隐式形状和外观模型。
问题设置。考虑具有已知相机校准的多视图RGB视频
序列的数据集。每一个序列捕捉一个随机的人从一个
单一的手构成随机运动。目标是学习一个手模型,
G
B
构成
形彩
色
蓝色是可以学
习的
的
g0
MLP
剥皮
权重
签
署
剩余11页未读,继续阅读
276 浏览量
2021-06-06 上传
112 浏览量
131 浏览量
103 浏览量
2021-05-01 上传
2021-06-28 上传
2021-05-26 上传
158 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全面详实的大学生电工实习报告汇总
- 利用极光推送实现App间的消息传递
- 基于JavaScript的节点天气网站开发教程
- 三星贴片机1+1SMT制程方案详细介绍
- PCA与SVM结合的机器学习分类方法
- 钱能版C++课后习题完整答案解析
- 拼音检索ListView:实现快速拼音排序功能
- 手机mp3音量提升神器:mp3Trim使用指南
- 《自动控制原理第二版》习题答案解析
- 广西移动数据库脚本文件详解
- 谭浩强C语言与C++教材PDF版下载
- 汽车电器及电子技术实验操作手册下载
- 2008通信定额概预算教程:快速入门指南
- 流行的表情打分评论特效:实现QQ风格互动
- 使用Winform实现GDI+图像处理与鼠标交互
- Python环境配置教程:安装Tkinter和TTk
