视觉对齐驱动的无监督多语言机器翻译
83 浏览量
更新于2025-01-16
收藏 2.22MB PDF 举报
"多语言视觉对齐:一项突破性的研究探讨了如何通过图像驱动的无监督机器翻译方法来跨越语言障碍。传统机器翻译模型依赖于大规模的平行语料库,这在收集和维护多语言对时面临挑战。本研究团队,包括哥伦比亚大学的戴夫·艾泼和卡尔·冯德里克,提出了一种创新思路,他们观察到尽管语言间的差异显著,但世界的视觉呈现却具有高度一致性。
他们的方法的核心在于利用视觉观察作为桥梁,训练一个模型,该模型只有在与之相关的图像相似且图像与其文本描述完美对齐时,才会对不同语言的文本片段进行准确翻译。这种方法摆脱了对平行语料库的依赖,转而利用图像的普遍性和视觉一致性来建立多语言间的联系。实验结果证明,这种方法在无需监督的情况下,对于单词和句子的翻译效果优于之前的ING检索技术。
为了实现这一目标,研究者们创建了一个全新的文本数据集,包含了50多种语言及其对应的图像,以此为基础训练他们的模型。他们展示了即使在没有特定语言对的配对训练数据的情况下,通过视觉对齐,模型也能有效地学习语言之间的对应关系。例如,尽管英、法、日、印等不同语言对自行车的描述各异,但其视觉上的共同特征让模型能够理解它们的内在联系。
这项工作不仅革新了机器翻译的技术路线,也为跨文化交流提供了一种新的可能性。研究者们强调,通过图像进行无监督学习,能够有效地降低语言翻译的门槛,使机器翻译更加普适和实用。此外,他们的研究成果还包括可公开获取的代码、模型和数据,以便其他研究者进一步探索和应用这一领域的发展。"
16476
∈
I
I
−
I
I
I
J
I
J
I
1
I
J
I
2
我
1
我
2
Σ
I
j
其中
α
v
=
sim
(
z
v
,
z
v
)
.
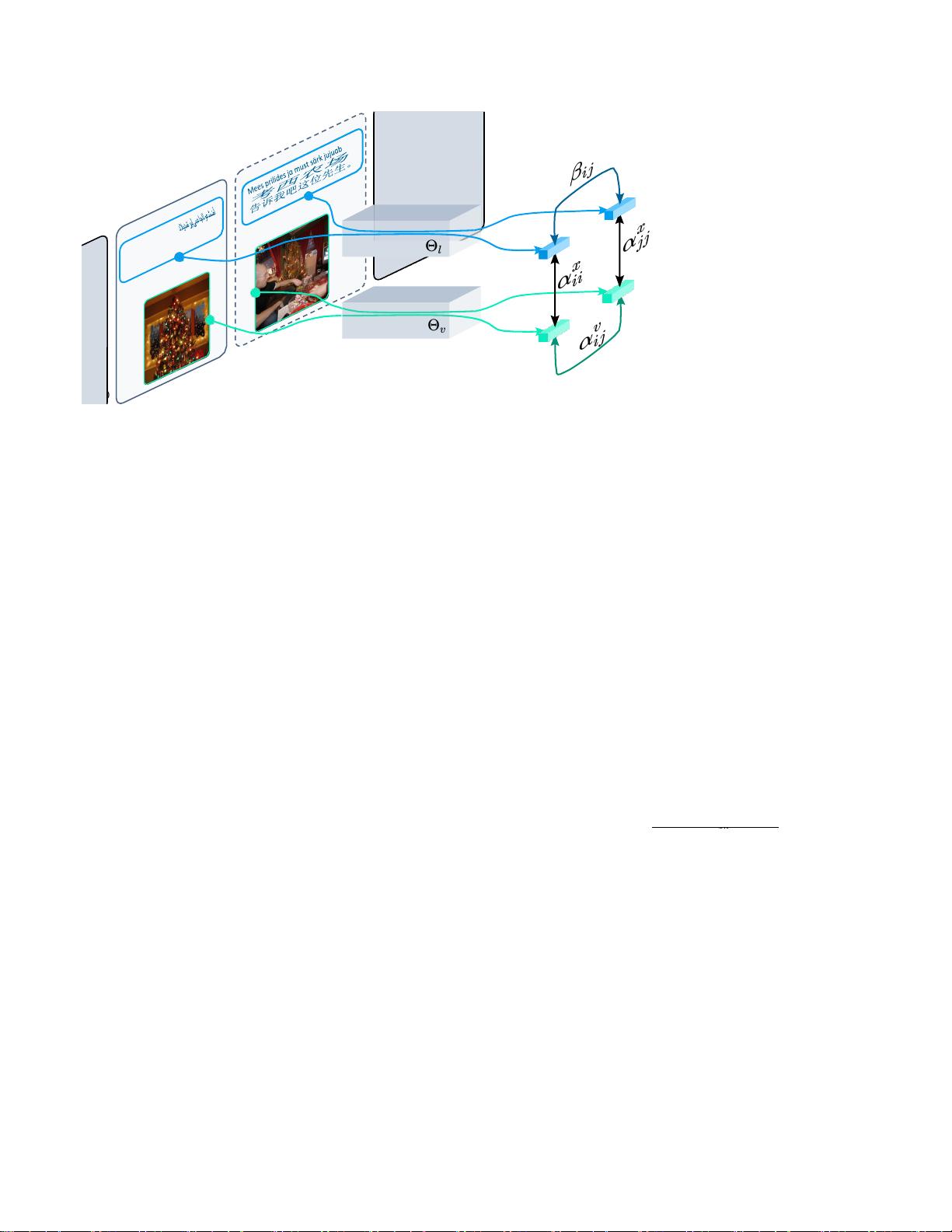
图
2.
我们的模型通过视觉利
用传递关系来学习对齐的嵌
入空间以进行语言翻译。跨
句子
相似度β
ij
由
通过图像集
合的路径估计。详情见第
3
节。
(1)积极的,不应该的(消极的)。在上面的公式
中,标量
α
ij
[0
,
1]表示该分配。然而,由于我们处于
无监督翻译设置中,因此我们没有地面真值对。我们
的主要想法,我们将在下一节介绍,是我们可以使用
视觉模态来发现这些对。
3.2.
传递关系
在没有标签的情况下,估计不同语言的句子的相似
性是具有挑战性的。无监督机器翻译方法通常依赖于
拓扑 属性 ,例 如分 布对 齐或 反向 翻译[32,34]。然
而,这些约束为学习提供了噪声梯度,这使得大规模
优化变得困难。
我们建议通过视觉模态利用传递关系来估计语言
空间
α
ij
中的相似度。给定图像的数据集和它们对应
的字幕,我们估计跨模态(图像
-
图像)相似性以及
跨图像(图像
-
图像)相似性。设
α
x
为跨模态相似
度,它表示图像
i
与其对应的字幕
i
之间的对齐。我们
还让
α
v
是跨图像相似性,指示图像
i
和另一图像
j
之间
的感知相似性。它提供了
trans-
作为相似
I
J
I
I
I
J
J
J
(
二
)
标题,并且还有另一个图像具有密切的视觉相似性,
将形成传递关系在现实场景中,在存在噪声的情况
下,可能难以建立某些图像和字幕对的对应关系,我
们的公式通过打破传递关系来处理。换句话说,我们
只考虑具有高总相似性的路径作为对比目标的肯定,
并且丢弃具有低总相似性的那些路径,因为它们的句
子可能不匹配。
3.3.
学习
为了优化等式1,我们需要估计α
x
和α
v
。我们用神
经网络对两者进行参数化,并训练它们直接估计相似
性,也使用对比学习[12]。
视觉相似性:我们共同学习视觉特征空间来估计
α
v
。对于每幅图像,我们执行两次随机增强,从而产
生同一图像的两个不同版本。运行这两个变换后的图
像
通 过 图 像 网 络 , 以 及 其 他 N
1
对 ( 在 一 批 N
个
样 本
中)。这导致
2N
个
特征图。对于每一对
(
i
1
,
i
2
)
具
有表示z
v
和z
v
的图像,我们计算对比损失,其中所有
其他2(N−1)个图像都是负数。我们使用损失函数:
exp(α
v
/τ)
L
=
− log
Σ
α
= f
。
α
x
·
α
v
·
α
x
≤
1/3
μ
m
,
v
i
1
,
i
2
j i
1
exp
(α
v
1
/τ
)
(
三
)
其中
f
(x)
=
max(0
,
x-m)/(1-
m)
,
i j i j
映象网
文本网络
剩余11页未读,继续阅读
699 浏览量
163 浏览量
880 浏览量
441 浏览量
2024-10-27 上传
210 浏览量
2025-02-21 上传
2025-01-15 上传
2025-02-21 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- A7Demo.appstudio:探索JavaScript应用开发
- 百度地图范围内的标注点技术实现
- Foobar2000绿色汉化版:全面提升音频播放体验
- Rhythm Core .NET库:字符串与集合扩展方法详解
- 深入了解Tomcat源码及其依赖包结构
- 物流节约里程法的文档整理与实践分享
- NUnit3.vsix:快速安装NUnit三件套到VS2017及以上版本
- JQuery核心函数使用速查手册详解
- 多种风格的Select下拉框美化插件及其js代码下载
- Mac用户必备:SmartSVN版本控制工具介绍
- ELTE IK Web编程与Web开发课程内容详解
- QuartusII环境下的Verilog锁相环实现
- 横版过关游戏完整VC源码及资源包
- MVC后台管理框架2021版:源码与代码生成器详解
- 宗成庆主讲的自然语言理解课程PPT解析
- Memcached与Tomcat会话共享与Kryo序列化配置指南
