DYLE:用于长输入摘要的动态潜在提取方法
PDF格式 | 24.39MB |
更新于2025-01-16
| 33 浏览量 | 举报
"DYLE是一种用于抽象长输入摘要的动态潜在提取方法,旨在解决基于Transformer的模型在处理长文本摘要时的效率和质量挑战。该方法同时训练提取器和生成器,提取的文本片段作为潜在变量,解码过程中实现动态的片段级注意力权重。DYLE引入了启发式方法进行oracle提取,以及一致性损失项来优化提取器和生成器的协同工作。在GovReport、QMSum和arXiv数据集上的实验结果显示,DYLE在长文档和长对话摘要任务上表现出色,ROUGE分数提升显著,并且其动态权重提供了生成过程的可解释性。"
DYLE(Dynamic Latent Extraction)是针对长输入摘要问题提出的一种创新解决方案。传统的基于Transformer的预训练语言模型(如BART和T5)在处理短文本摘要时表现出色,但它们在处理长篇幅输入时面临效率和准确性的双重挑战。这是因为完全自注意力机制导致的高内存复杂性,使得模型难以高效地处理大量信息。
DYLE通过结合提取器和生成器,试图克服这一难题。提取器负责从长输入文档中选择关键信息片段,这些片段作为潜在变量参与到生成器的解码过程中。在解码过程中,DYLE采用动态的片段级注意力权重,这允许模型根据需要灵活关注不同文本片段,从而提高摘要的精度和覆盖度。
为了训练这个系统,DYLE采用了两种损失函数:Oracle损失和一致性损失。Oracle损失基于简单的启发式方法,为提取过程提供监督,帮助模型学习理想的文本片段选择。一致性损失则鼓励提取器的输出接近生成器预测的动态权重,以确保两者之间的协调一致。
在多个长文档和长对话摘要任务的评估中,DYLE展现了优越的性能,尤其是在GovReport和QMSum数据集上,相比于现有方法,其ROUGE评分有显著提升。此外,DYLE的动态权重机制不仅提升了摘要的质量,还为生成过程提供了可解释性,有助于理解模型的决策过程。
DYLE是解决长输入摘要问题的一个重要进展,它通过动态潜在提取和优化的训练策略,实现了对长文本的高效、高质量摘要,同时提供了生成过程的可解释性,这对于未来的研究和应用具有重要的启示意义。
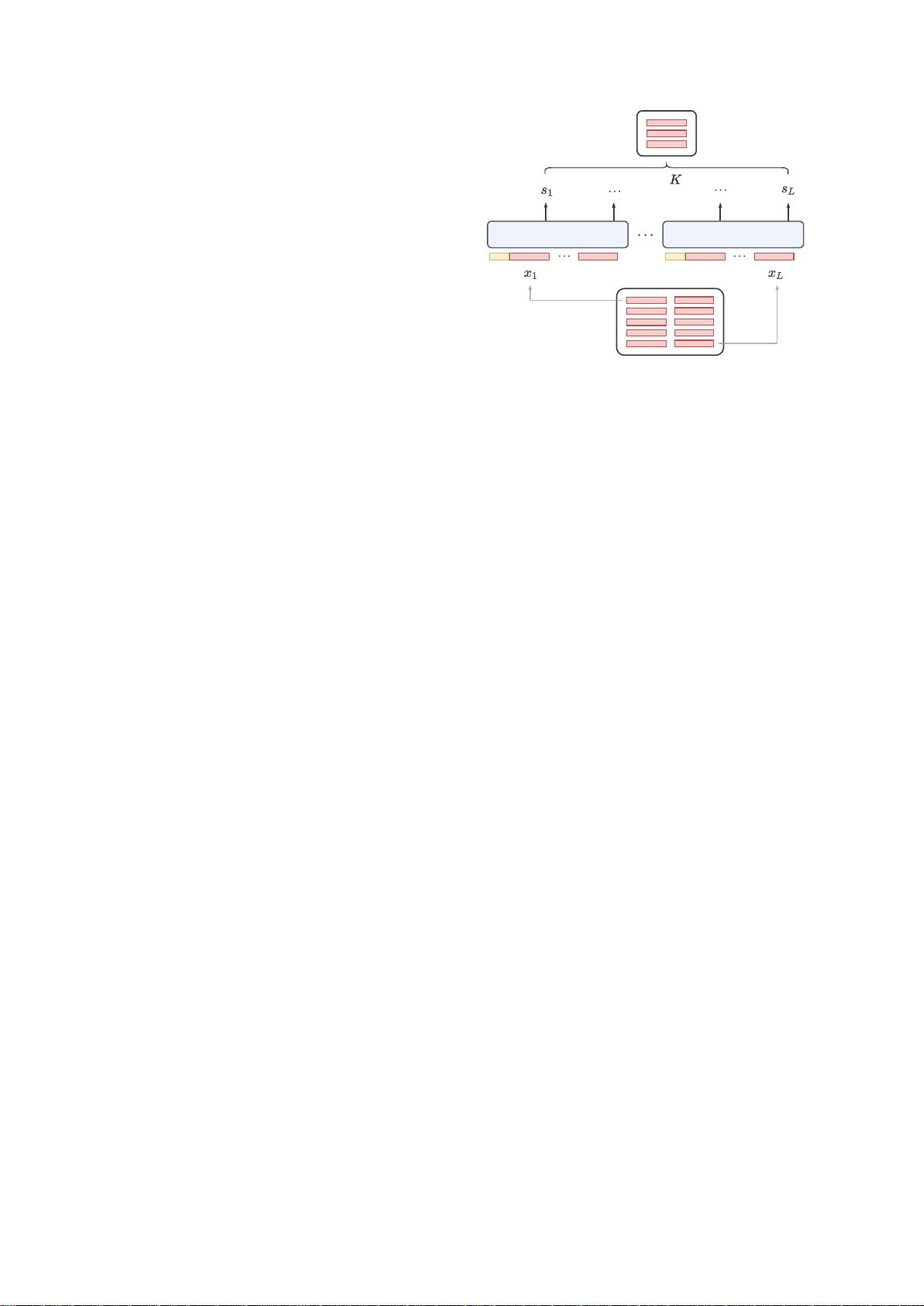
3.1 Extractor-Generator Framework
=
An interesting research question is how to design
the extractor for long inputs. Limited by GPU mem-
ory, it is impractical to concatenate all snippets
and encode them with a large pre-trained language
model. As shown in Figure 2, we group consecu-
tive snippets into chunks. We concatenate the query
q
with each chunk and compute the encoded vector
for each snippet independently within the chunk
it belongs to. We project the encoded vectors to
scalar scores s
i
= E
η
(q, x
i
) using an MLP.
0
3我们的方法
0
分层模型已经提出了各种分层模型来处理更长的输
入。Cohan等人(2018年)使用分层编码器和意
识到话语的解码器对文档话语结构进行建模。HAT
-Bart(Rohde等人,2021年)提出了一种新的基
于分层注意力变换器的架构,试图捕捉句子和段落
级别的信息。HMNet(Zhu等人,2020年)构建
了一个包括话语级信息和发言者角色的分层结构。
然而,这些模型主要关注模型性能,而不是减少内
存和计算成本。
0
3.1提取器-生成器框架
0
我们方法的概述如图1所示。在第3.1节中,我们制
定了我们的任务和提取器-生成器框架。在第3.2节
中,我们介绍了针对长输入的提取器参数化。在第
3.3节中,我们介绍了生成器的公式化和新颖的一
致性损失。提取器模块既通过一致性损失又通过or
acle损失进行优化,我们将在第3.4节中详细介绍
。总体的训练目标在第3.5节中总结。
0
在长输入摘要任务中,输入由L个文本片段X=(x1,
...,
xL)和一个可选的查询q(如果查询与摘要配对)组
成。在长输入摘要中,文本片段的数量L可能非常
大。输出是长度为T的摘要y。对于对话摘要任务,
每个发言者的对话话语被用作片段。对于文档,我
们将输入分词为句子,并将每个句子用作片段。目
标是学习一个模型,给定输入片段X和先前生成的
标记y<t,生成一系列摘要标记y。
0
Pθ(y|q,X)=
00
t=1Pθ(yt|q,X,
y<t)
0
RoBERTaRoBERTa
0
查询查询
0
前-
0
提取的片段
0
文档
0
图2:长输入提取器。我们将文档分成多个包含连续片段
的块。一个共享的RoBERTa独立地对每个块进行编码。
0
提取器将查询和源文本作为输入,并输出每个文本
片段xi的得分si=Eη(q,
xi)。其中η是提取器的参数。我们根据它们的得分
从文档X中提取K个片段XK:
0
XK=top-K(Eη(q,xi),xi∈X)(1)
0
从X中检索XK后,提取器-生成器框架通过将X替换
为XK来建模输出概率,即
0
Pθ(y|q,X)=Pθ(y|q,XK)
00
t=1Pθ(yt|q,XK,y<t)(2)
0
请注意,公式(1)中的top-K操作是不可微的,
我们不通过top-K传播梯度;相反,我们提出了在
第3.3节和第3.4节中优化提取器的方法。
0
3.2长输入的提取器
0
3.3具有动态权重的生成器
0
长输入摘要中的提取-生成模型面临两个挑战。
0
+v:mala2277获取更多论文
剩余11页未读,继续阅读
相关推荐


12 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 普天身份证阅读器新版二次开发包发布
- C# 实现文件的数据库保存与导出操作
- CkEditor增强功能:轻松实现图片上传
- 掌握DLL注入技术:测试工具使用与探索
- 实现带节假日农历功能的jQuery日历选择器
- Spring循环依赖示例:深入理解与Git代码仓库实践
- ABB PLC液压阀门控制程序开发指南
- 揭秘4核旋风密版626象棋引擎的超牛实力
- HTML5实现的经典游戏:小霸王坦克大战源码分享
- 让Visual Studio兼容APM硬件信息的方法
- Kotlin入门:创建我的第一个应用
- Android语音识别技术研究报告与应用分析
- 掌握JavaScript基础:第8版教程源代码解析
- jQuery制作动态侧面浮动图片广告特效教程
- Android PinView仿支付宝密码输入框源码分析
- HTML5 Canvas制作的围住神经猫游戏源码分享
