在线动作检测:范例查询与类别级建模提升效率
PDF格式 | 991KB |
更新于2025-01-16
| 148 浏览量 | 举报
在线动作检测是视频理解领域的重要研究课题,它涉及到在未剪辑的流视频中实时识别和追踪动作实例,这对于智能监控和异常检测等应用场景具有实际价值。传统的在线动作检测方法往往依赖于历史帧的信息,以预测未来动作,但这类方法存在历史依赖性过强、忽视类别特性以及对效率不够重视的问题。
文章标题"在线动作检测中基于范例的有效查询机制及类别级建模"旨在解决这些问题,提出了一种新颖的Colar(咨询示例的在线动作检测)方法。Colar的核心创新在于它结合了历史依赖性和类别级建模,以实现更高效和准确的检测。具体来说,Colar采用了以下策略:
1. 范例查询机制:Colar首先对每个输入帧与预先定义的范例框架进行相似性测量,通过计算它们之间的特征聚合,赋予每个范例框架相应的权重。这种机制强调了相似性度量和特征融合的重要性,能够在有限的计算资源下完成。
2. 历史框架与类别级建模:Colar利用历史帧构建长期依赖关系,这通过样本协商机制实现,即不仅考虑单个历史帧,还结合了整个历史序列中的信息。同时,为了捕捉不同动作类别的独特特性,Colar引入了类别中的代表性框架,进行类别级建模,增强了模型对动作分类的准确性。
3. 效率与平衡:Colar采用轻量级架构,旨在优化计算效率,同时保持高检测性能。这使得它在处理流视频时能够有效地在时间和精度间找到平衡,避免过度依赖未来帧而牺牲实时性。
4. 时空网络的应用:Colar利用时空网络来处理视频帧,这有助于更好地捕捉空间和时间上的动态变化,进一步提升了动作检测的性能。
Colar在传统在线动作检测的基础上,引入了范例查询和类别级建模的概念,显著提高了在线动作检测的准确性和效率,为实际应用提供了更为可靠和高效的解决方案。论文的代码可以在指定网站<www.example.com>和GitHub仓库<https://github.com/VividLe/Online-Action-Detection>获取,供其他研究人员和开发者参考和使用。
3162
评分
历史特色
网络
0
1
…
类别特征e
0.0
1
0.0
2
中
国
,
1
20
12
年2
月
键值
重量
评分
铅球
铅球
高尔夫挥杆
铅球
静态
分支
动态分支
4
3
2
1
联系
我
们
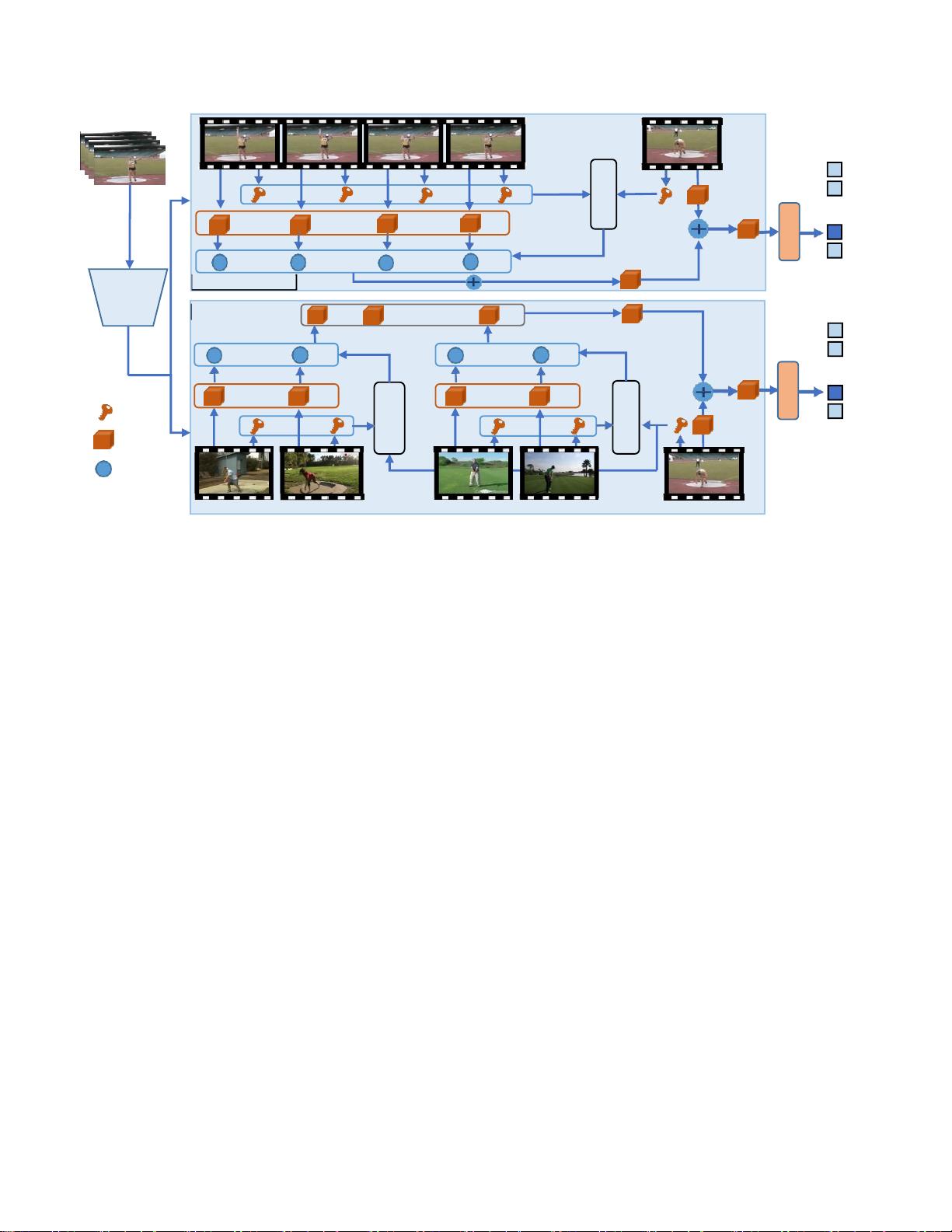
图2. 提出的在线动作检测的Colar方法的框架给定视频,动态分支将帧与其历史样本进行比较并对时间依赖性进行建模,而静
态分支将帧与类别样本进行比较并捕获类别特殊性。
在弱监督环境下[46,51,52,58]也得到了很好的探
索。
在线动作检测算法与离线动作检测算法的主要区别
在于是否能够访问未来帧。在离线算法中,Xuet al.
[44]通过以相反的顺序播放视频来执行数据增强,而
朱[62]则对视频中多个提议之间的关系进行建模。然
而,这些程序是不适合的研究在线行动检测任务。
Space-time memory network. Oh等人[33]提出了空时
存储器网络,以通过空时存储器读取有效地连接帧及
其先前的帧。该模型在时态信息建模方面具有良好的
性能,并已被扩展到多个任务中,
如
:视频对象检测
[6],视频对象分割[18,31],跟踪[25]。与时空记忆网
络不同,静态分支采用范例协商机制来模拟类内关
系。具体来说,它首先聚合每个类别的特定特征,然
后组合多个特征以获得类别特征。
3.
方法
给定视频流,一旦动作开始,在线动作检测算法就
应该报告动作的发生
并持续报警直到行动结束学习过程由帧级分类标签
y
=
[
y
0
,
y
1
,
...
,
y
C
]
,其中
y
c
0
,
1
指示
帧
f
0
是否
属
于第c类。如图2所示,我们首先采用骨干网络来提取
视频特征。然后,我们提出了动态分支来模拟一个段
内的长期依赖关系,并提出了静态分支来捕获每个类
别的整体特殊性最后,将两个检测结果进行融合,以
执行在线动作检测任务。
3.1.
动态分支
由于相邻帧可以提供丰富的上下文线索来确定当前
帧的类别标签,动态分支的核心思想是通过将帧与其
先前的历史帧进行比较并动态地聚合局部特征来建模
局部图2的上半部分展示了动态分支中的详细操作。与
OadTR [42]的标准多头自注意机制相比,我们提出的
动态分支进行了两个合理的设计,这充分有利于在线
动作检测任务。首先,我们使用核大小为3的时间卷积
来对历史帧之间的局部线索进行建模,这与自我注意
的全局建模是互补的。其次,我们对OadTR做了两个
简化,
即
:把班级移到-
…
…
…
相似性
相似性
相似性
分类器
分类器
剩余12页未读,继续阅读
相关推荐






cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Saber仿真下的简化Buck环路分析与TDsa扫频
- Spring框架下使用FreeMarker发邮件实例解析
- Cocos2d捕鱼达人路线编辑器开发指南
- 深入解析CSS Flex布局与特性的应用
- 小学生加减法题库自动生成软件介绍
- JS颜色选择器示例:跨浏览器兼容性
- ios-fingerprinter:自动化匹配iOS配置文件与.p12证书
- 掌握移动Web前端高效开发技术要点
- 解决VS中OpenGL程序缺失GL/glut.h文件问题
- 快速掌握POI技术,轻松编辑Excel文件
- 实用ASCII码转换工具:轻松实现数制转换与查询
- Oracle ODBC补丁解决数据源配置问题
- C#集成连接器的开发与应用
- 电子书制作教程:你的文档整理助手
- OpenStack计费监控:使用collectd插件收集统计信息
- 深入理解SQL Server 2008 Reporting Services
