VSGN:跨尺度视频自拼接解决时间动作定位难题
PDF格式 | 1.02MB |
更新于2025-01-16
| 198 浏览量 | 举报
视频自拼接图网络(Video Stitching Graph Network,VSGN)是一种创新的方法,旨在解决视频时间动作定位(Temporal Action Localization,TAL)这一具有挑战性的任务。TAL在当前互联网视频内容爆炸的时代中变得越来越重要,因为它不仅有助于在体育赛事中捕捉精彩瞬间,还为视频检索、字幕生成等高级任务提供了基础。
VSGN的设计重点在于应对视频动作时间尺度的广泛变化,尤其是针对短动作的处理。传统的TAL数据集中,短动作数量众多,但往往伴随着较低的定位精度。为了克服这个难题,VSGN采用了多层次的跨尺度策略,包括视频自缝合(Video Self-Stitching,VSS)和跨尺度图金字塔网络(Cross-Scale Graph Pyramid Network,xGPN)两个关键组件。
在VSS模块中,研究人员通过对视频进行局部放大和时间维度上的拼接,使得模型能够利用不同尺度间的互补特性,捕捉到动作的不同阶段。这种处理方式有效地增强了特征表示,特别对于那些难以被传统方法有效处理的短动作。
xGPN则进一步通过构建跨尺度图金字塔结构,利用多尺度的上下文信息来增强特征融合。它包含混合模块,可以同时聚合来自不同尺度的特征以及同一尺度内的信息,这有助于提高对动作位置和类别的准确判断。
VSGN的贡献在于它显著提升了TAL的性能,特别是在THUMOS-14和ActivityNet-v1.3等基准测试上,实现了与现有最先进的方法相当甚至超越的定位精度。特别值得注意的是,VSGN对于短动作的处理效果显著优于传统方法,证明了其在实际应用中的优势。
VSGN的出现标志着在视频理解领域,特别是在处理时间动作定位问题上,跨尺度和自适应策略的重要性得到了深入研究和应用。它代表了一种新的解决方案,对于推动该领域的技术发展和实际应用具有重要意义。VSGN的源代码可以在[https://github.com/coolbay/VSGN](https://github.com/coolbay/VSGN)获取,可供其他研究者参考和进一步优化。
13660
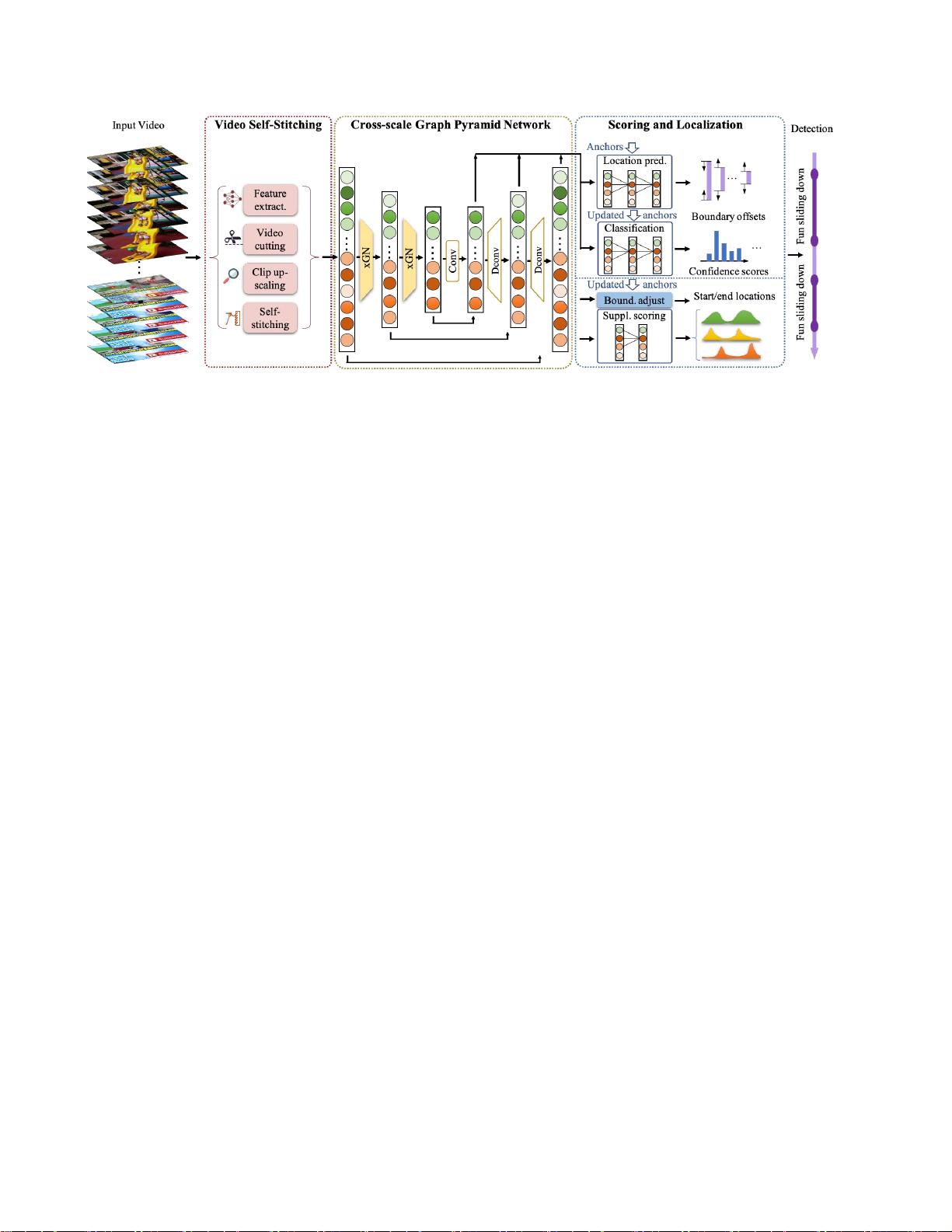
图
2.
所提出的视频自缝合图网络(
VSGN
)的架构。它需要一个视频序列,并生成检测到的动作的开始
/
结束时间以及它们的
类别。它有三个组成部分:视频自拼接(VSS)、跨尺度图金字塔网络(xGPN)以及评分和定位(SoL)。VSS(红色虚线
框,见图3)包含四个步骤来准备视频序列作为xGPN输入。xGPN由多级编码器和解码器金字塔组成。编码器通过交叉尺度图
网络(xGN)的堆栈(黄色梯形区域,见图10)聚合不同级别的特征。4详情);解码器恢复时间分辨率并生成用于检测的多级
特征。
SoL
(蓝色虚线框)包含四个模块,前两个预测动作得分和边界,后两个产生补充得分和调整边界。
由于小的输入规模,这是有效的,但会损害短动作,
特别是长视频中的短动作,因为这些短动作基本上被
缩小了规模,并且它们的信息容易丢失或失真。然
而,对于受其架构限制的这些方法而言,将视频
放大
作为输入是不平凡的。例如,BSN依赖于开始/结束曲
线来识别提议候选,但是当使用更多帧时,曲线将具
有太多的峰和谷而不能生成有意义的提议。在G-TAD
中,如果内插太多片段并且相邻片段变得相似,则其
倾向于仅在时间附近找到图邻居(称为
缩放诅咒
)。
第二类是使用滑动窗口将原始视频裁剪成多个输入
序列。这可以保留每个帧的原始信息。属于这一类的
作品R-C3 D [40],TAL-NET [8],PBRNet [23]执行池
化/跨步卷积以获得多尺度特征。这两个类别相比,我
们提 出的 VSGN 使用 的原 始 视频 剪 辑 和其 放大的 对
应,并利用其互补的属性,以提高其表示。
2.3.
图神经网络在
TAL
图神经网络(GNN)是一种用于开发不规则结构中
相关性的有用模型[16]。随着它们在不同的计算机视
觉领域变得流行[12,36,38],研究人员也发现它们
在时间动作定位中的应用[2,42,44]。G-TAD [42]打
破了对视频片段的时间位置的限制,并使用图来聚合
来自不位于视频片段中的片段的特征
时间邻域它将每个片段建模为节点,将片段之间的相
关性建模为边缘,并应用边缘卷积[36]来聚合特征。
BC-GNN [2]通过将时间建议的边界和内容建模为图神
经网络的节点和边来改进本地化。P-GCN [44]将每个
建议视为一个图节点,可以将其与建议方法相结合以
生成更好的检测结果。
与这些方法相比,我们的VSGN在视频片段上构建
图作为G-TAD,但不同的是,除了从相同尺度建模片
段之外,VSGN还利用
跨尺度
片段之间的相关性并定
义跨尺度边缘以打破
缩放诅咒
。此外,我们的VSGN
包含金字塔架构中的
多级
图神经网络,而G-TAD仅使
用一级。
3.
视频自拼接图网络
图 2 展 示 了 我 们 提 出 的 视 频 自 拼 接 G 图 网 络
(VSGN)的总体架构。它由三个组件组成:视频自
拼接(VSS)、跨尺度图金字塔网络(xGPN)、评分
和本地化(SoL),这些组件将在第2节中详细说明。
分别为3.2、3.3和3.4。在深入研究细节之前,在SEC。
3.1我们首先介绍我们的想法背后的这些组件来处理短
动作的问题。
3.1.
短动作
更大尺寸的剪辑。为了解决短动作尺度的问题,让
我们首先考虑当人们发现自己对一个短视频片段感兴
趣时,他们会如何反应。
剩余10页未读,继续阅读
相关推荐

131 浏览量




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Web远程教学系统需求分析指南
- 禅道6.2版本发布,优化测试流程,提高安全性
- Netty传输层API中文文档及资源包免费下载
- 超凡搜索:引领搜索领域的创新神器
- JavaWeb租房系统实现与代码参考指南
- 老冀文章编辑工具v1.8:文章编辑的自动化解决方案
- MovieLens 1m数据集深度解析:数据库设计与电影属性
- TypeScript实现tca-flip-coins模拟硬币翻转算法
- Directshow实现多路视频采集与传输技术
- 百度editor实现无限制附件上传功能
- C语言二级上机模拟题与VC6.0完整版
- A*算法解决八数码问题:AI领域的经典案例
- Android版SeetaFace JNI程序实现人脸检测与对齐
- 热交换器效率提升技术手册
- WinCE平台CPU占用率精确测试工具介绍
- JavaScript实现的压缩包子算法解读
