"珠穆朗玛峰和英国地理学家:亚洲大陆所在国,KGC知识图补全方法的性能分析"
PDF格式 | 744KB |
更新于2025-01-16
| 130 浏览量 | 举报
+v:mala2277获取更多论
文
山
实例
珠穆朗玛峰
得名于
乔治
·
埃佛勒斯
大陆
亚洲
国籍国
联合王国
英国
…
是欧洲西北部的一个
主权国家
亚洲是地球上面积最大、人口
最多的大陆。
...
是一位英国测量师和地
理学家
珠穆朗玛峰是地球上海拔最高的
山峰。
山是地壳的一个隆起部分
SimKGC
:使用预训练语言模型的
王亮
1
赵
伟
2
魏卓宇
2
刘景明
2
1
微软亚洲研究院
2
Yuanfudao AI Lab,北京,中国
wangliang@microsoft.com
{zhaowei01,weizhuoyu,liujm}@yuanfudao.com
摘要
知识图补全(KGC)的目的是对已知事实
进行推理,并推断出缺失的链接。基于文
本 的 方 法 , 如 KG-BERT ( Yao et al. ,
2019)从自然语言描述中学习实体表示,
并具有归纳KGC的潜力。然而,基于文本
的方法的性能仍然在很大程度上落后于基
于图 嵌 入 的 方 法 , 如 TransE ( Bordes et
al. , 2013 ) 和 RotatE ( Sun et al. , 2019
b)。在这篇文章中,我们发现关键问题是
有效的对比学习。为了提高学习效率,我
们引入了三种类型的否定:批内否定,批
前否定和自我否定,它们作为硬否定的简
单形式。结合InfoNCE损失,我们提出的
模型SimKGC可以在几个基准数据集上大
大优于 基 于嵌入 的方法。 在平均 倒 数 秩
(MRR)方面,我们在WN18 RR上将最新
技术水平提高了+19%,
+6.8%在Wikidata5M的传导设置上,+22%
在Wikidata5M的归纳设置上。进行彻底的
分析,以深入了解每个组成部分。我们的
代 码 可 以 在
https://github.com/intfloat/Sim
KGC上找到。
1
介绍
大规模知识图(KG)是知识密集型应用程序
的 重 要 组 成 部 分 ,例 如 问 答 (
Sun et al.
,
2019a
),推荐系统(
Huang et al.
,
2018
)和
智能会话代理(Dinan et al. KG通常由一组三
元组(h,r,t)组成,其中h是头实体,r是
关系,t是尾实体。受欢迎的公立幼儿园包括
Freebase
(
Bollacker et al.
,
2008
),
Wikidata
(
Vran-
de c i candKrötzsch
,
2014
) ,
YAGO
(
Suchaneket al.
,
2007
)、
ConceptNet
(
Speer
et al. ,2017)和Word- Net(Miller,1992)
等。尽管它们很有用
在元福道
AI
实验室完成的工作
在实 践 中, 它们往 往不完 整。知 识图补 全
(KGC)技术是知识图自动构造和验证的必
要手段。
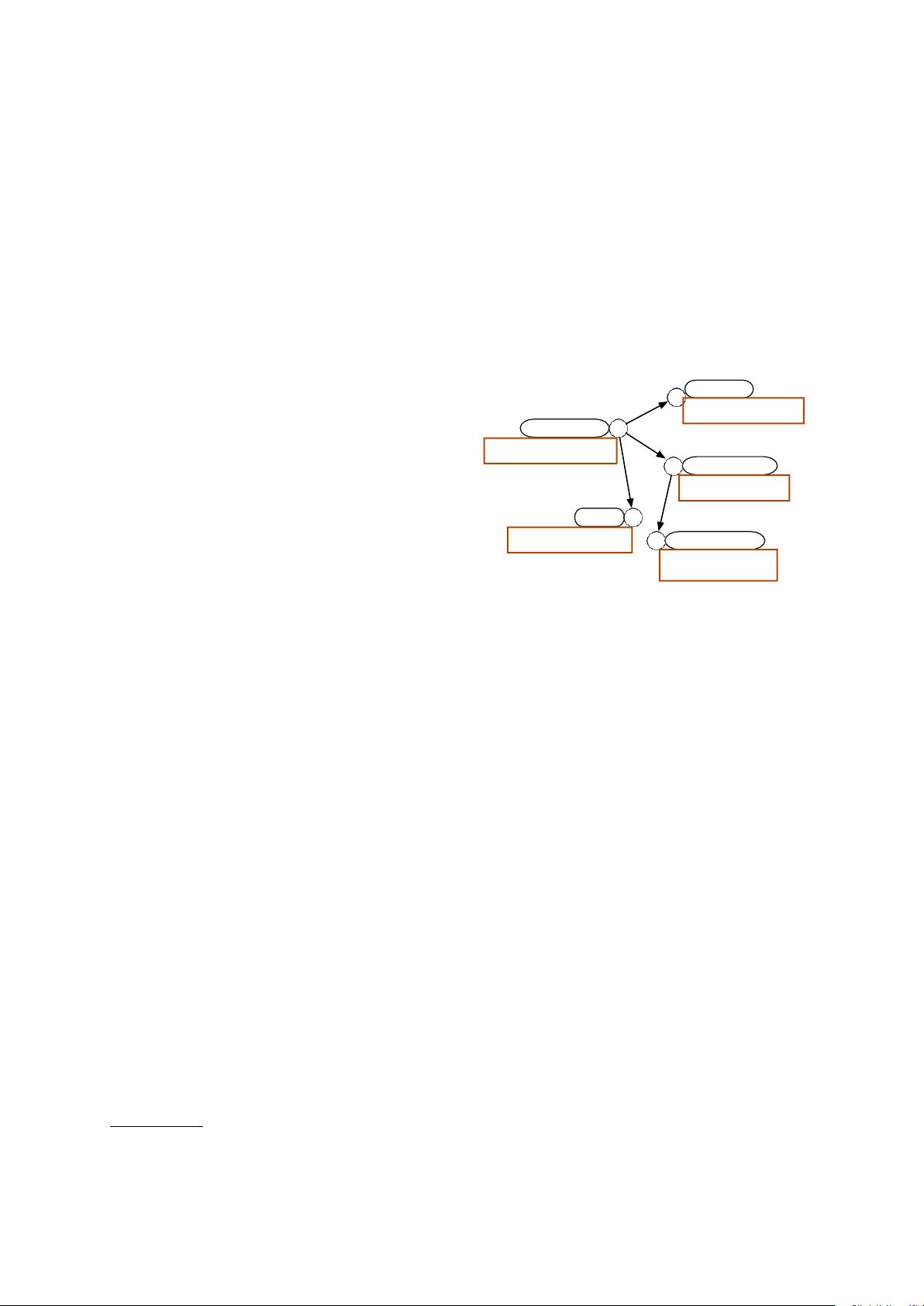
图1:知识图谱的一个例子每个实体都有其名称和
文本描述。
现有的KGC方法可以分为两大类:基于嵌
入的方法和基于文本的方法。基于嵌入的方法
将每个实体和关系映射到一个低维向量中,而
不使用任何辅助信息,如实体描述。该家族包
括 transE ( Bordeset al. , 2013 ) 、 TransH
( Wang et al. , 2014 ) 、 Ro- tatE ( Sun et
al.
,
2019b
) 和
TuckER
(
Balaze-vicet al.
,
2019
)等。通过比较,基于文本的方法(姚
等 。 ,
2019; Xie et al.
,
2016; Wang
等 人 ,
2021 c)合并了用于实体表示学习的可用文
本,如图1所示。显然,基于文本的方法应该
优于基于嵌入的方法,因为它们可以访问额外
的输入信号。然而,流行的基准测试结果(例
如 ,
WN 18 RR
,
FB 15 k- 237
,
Wikidata 5
M)讲述了一个不同的故事:即使使用预先训
练的语言模型,基于文本的方法仍然落后
我们假设,这种认知能力下降的关键问题是
对比学习的效率低下。基于嵌入的方法不涉及
昂贵的计算文本
en
,
arXiv
:
2203.02167v1 [cs.CL] 2022
年
3



剩余15页未读,继续阅读
相关推荐



116 浏览量


cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 久度免费文件代存系统 v1.0:全技术领域源码分享
- 深入解析caseyjpaul.github.io的HTML结构
- HTML5视频播放器的实现与应用
- SSD7练习9完整答案解析
- 迅捷PDF完美转PPT技术:深度识别PDF内容
- 批量截取子网页工具:Python源码分享与使用指南
- Kotlin4You: 探索设计模式与架构概念
- 古典风格茶园茶叶酿制企业网站模板
- 多功能轻量级jquery tab选项卡插件使用教程
- 实现快速增量更新的jar包解决方案
- RabbitMQ消息队列安装及应用实战教程
- 简化操作:一键脚本调用截图工具使用指南
- XSJ流量积算仪控制与数显功能介绍
- Android平台下的AES加密与解密技术应用研究
- Место-响应式单页网站的项目实践
- Android完整聊天客户端演示与实践
