自动增强器AIM:图像与网格的智能变形提升深度学习性能
PDF格式 | 16.71MB |
更新于2025-01-16
| 191 浏览量 | 举报
本文主要探讨的是一个名为"AIM: 适用于图像和网格的自动增强器"的新颖技术,该技术旨在提高深度神经网络在计算机视觉任务中的鲁棒性和性能。传统的数据增强方法,如仿射变换、随机翻转和裁剪,通常是非学习性的,与特定任务无关,且不易于在不同数据维度间通用。然而,AIM的创新之处在于它将增强过程与网络学习过程相结合,通过与神经网络共同优化,实现对输入数据的约束非刚性变形。
在介绍部分,文章指出深度学习虽然在计算机视觉领域表现出色,但其鲁棒性仍有待提升,因为深度网络需要理解对象的视觉特征和其在空间中的位置。为了提高这种理解,传统的增强方法往往是预先设定好的,缺乏针对任务的定制性。AIM的出现正是为了解决这个问题,它可以根据特定任务预测出最适合的数据增强,比如在图像中增加狗的可见区域或在3D网格中扩大恐龙头部、背部和尾部的覆盖范围。
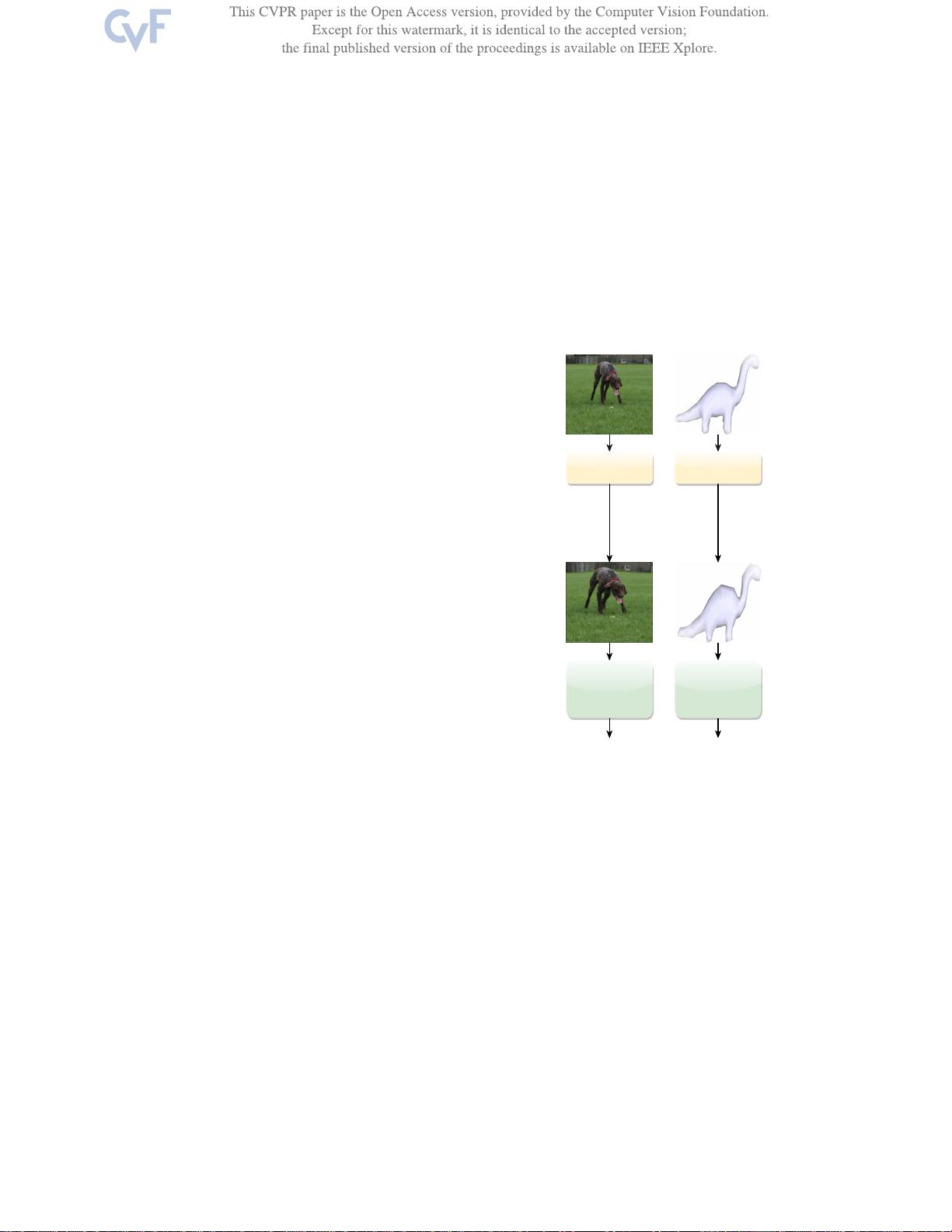
AIM的工作原理是,在训练和推理阶段,对输入数据进行动态的、任务感知的非刚性变形,以增强网络对变化的适应性。这种方法不仅增强了数据的多样性,还能够帮助网络学习到更丰富的特征表示。图1展示了AIM在图像和网格上的应用实例,它能够有效扩展到不同类型的视觉数据,并证明了其在多种网络架构中的有效性。
与传统的增强方法不同,AIM不是简单的预处理步骤,而是作为一个可学习组件嵌入到网络中,能够随着网络的训练而不断优化。这使得增强过程更具针对性,提高了任务的有效性。AIM的提出标志着数据增强方法的一个重要进步,它有望在未来的研究中推动深度学习在计算机视觉领域的进一步发展。
722
0
AIM:一种适用于图像和网格的自动增强器
0
VinitVeerendraveerSingh和Chandra
Kambhamettu视频/图像建模与合成(VIMS)实验室,特拉华大学计算机与信息科学系,美国特拉华
州纽瓦克,邮编19716
0
{vinitvs,chandrak}@udel.edu
0
摘要
0
数据增强常用于增强深度神经网络的鲁棒性。在大多数当代
研究中,网络不决定增强方法;它们是与任务无关的,网格
搜索确定它们的幅度。此外,适用于低维数据的增强方法不
容易扩展到高维数据,反之亦然。本文提出了一种适用于图
像和网格的自动增强器(AIM),它可以轻松地在训练和推
理时与神经网络结合使用。它与网络共同优化,产生数据中
的约束非刚性变形。AIM预测适合任务的样本感知变形,我
们的实验证实了它在各种网络中的有效性。
0
1.引言
0
深度神经网络在各种计算机视觉任务中占主导地位。它们在
数字图像[15,16,38]和3D图形[8,
14]的分析中很常见。这些网络试图在计算机化环境中模拟
人类认知。然而,尽管深度学习在近年来取得了成功,但它
仍然不如人类视觉稳健。基于视觉任务的学习方法需要在对
象的外观和其在空间中的位置之间进行区分。为此,常常使
用增强方法对神经网络的输入数据进行预处理。一些增强方
法使神经网络对数据中的几何变化更加容忍。例如,仿射变
换、随机水平翻转和随机裁剪等增强技术在图像处理中是标
准的。对于网格分析,还会进行网格元素的抖动和仿射变换
。这些增强方法也是其他高级数据增强策略[5,11,21,32,
42,55]和框架[2,
54]的基础。上述增强方法不直接参与学习过程,也不依赖
于任务的目标。因此,它们是不可学习的和与任务无关的。
0
图像
0
分类
0
网络
0
AIM增加了像素在
0
狗所在的图像
0
目前
0
AIM
0
德国
0
短毛!
0
AIM增加了空间
0
在3D网格中,AIM增加了头
部、背部和尾部的空间覆盖
0
恐龙
0
AIM
0
网格
0
分类
0
网络
0
恐龙!
0
图1.
AIM在训练和测试期间对输入数据进行非刚性变形。AIM学习检测
样本中的关键区域以解决任务并增加其空间覆盖范围。如图所示,
它适用于图像和网格。
0
相反,任务感知的增强方法[5,12,
0
20,26,
37]与神经网络共同优化。这组方法的共同主题是顺序学习
哪些变换适合任务,何时使用它们以及应用程度如何。然而
,目前许多可学习的增强方法受限于其底层表示的维度。适
用于2D图像的方法要么不适用,要么没有明确的扩展到3D
数据的方法,反之亦然。在这项工作中,我们基于这些见解
和不足,提出了一种适用于图像和网格的自动增强器(AIM
)。
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 自动生成CAD模型文件的测试流程
- 掌握JavaScript中的while循环语句
- 宜科高分辨率编码器产品手册解析
- 探索3CDaemon:FTP与TFTP的高效传输解决方案
- 高效文件对比系统:快速定位文件差异
- JavaScript密码生成器的设计与实现
- 比特彗星1.45稳定版发布:低资源占用的BT下载工具
- OpenGL光源与材质实现教程
- Tablesorter 2.0:增强表格用户体验的分页与内容筛选插件
- 设计开发者的色值图谱指南
- UYA-Grupo_8研讨会:在DCU上的培训
- 新唐NUC100芯片下载程序源代码发布
- 厂家惠新版QQ空间访客提取器v1.5发布:轻松获取访客数据
- 《Windows核心编程(第五版)》配套源码解析
- RAIDReconstructor:阵列重组与数据恢复专家
- Amargos项目网站构建与开发指南
