动态表示学习提升视频模型的迁移与泛化能力
109 浏览量
更新于2025-01-16
收藏 16.93MB PDF 举报
本文主要探讨了在视频理解领域中的一个关键问题——如何通过动态表示学习来改进视频模型的迁移性能。传统的深度卷积神经网络虽然在大规模视频识别任务中表现突出,但它们在捕捉视频的长期时间结构方面存在局限性,从而影响了模型在新数据集上的泛化能力。作者针对这一问题,引入了动态分数这一概念,它衡量了视频网络所学习到的表示中除空间信息外的额外动态信息,这部分信息对于理解视频动态至关重要。
动态分数被看作是视频和空间模型之间对抗学习的工具,通过将时空分类器的性能提升作为目标,鼓励模型学习到更丰富的动态特征。作者设计了一种动态表示学习框架,旨在最大化这种动态分数,以增强模型对时间序列关系的建模能力。实验结果显示,经过动态表示学习(DRL)训练的模型在处理多样化的迁移学习任务,如动作分类,特别是面对少样本和新领域时,显示出显著的优势,证明了其在动态建模方面的优越性和更好的泛化能力。
文章首先回顾了深度学习在视频分类领域的进展,尤其是卷积神经网络相对于循环网络的优势,但同时也指出这些模型在处理复杂视频数据集时遇到的挑战,如空间偏见问题。空间偏见源于动作标签可能与视频帧中的视觉信息相关,而非动作本身,这使得模型容易依赖于静态画面而忽视视频的时间动态特性。
为了克服这些问题,作者强调了动态表示学习在解决视频时间建模中的重要性,并提出了一种创新的方法,通过对抗学习来增强模型的动态适应能力。这种方法不仅有助于提高模型在现有数据集上的性能,而且在面临未知环境和任务时展现出更强的迁移和泛化能力,这对于视频理解和相关应用具有实际价值。
总结来说,本文的研究为视频模型的改进提供了新的视角,特别是在处理时间依赖性问题上,动态表示学习作为一种有效手段,能够提升模型的鲁棒性和泛化能力,有望推动视频分析技术在实际场景中的应用。
f
ϕ
S
f
ϕ
3
2
1
x
f
ϕ
x
f
ϕ
(
˜
x)
f
ϕ
1
1
1
˜
x
2
1
3
˜
x
f
ϕ
s
=
1
T
g
ϕ
s
(x
i
) (1)
γ(f
ϕ
; p
D
) = min
f
ϕ
s
∈F
S
E
x∼p
D
L(f
ϕ
s
(x), f
ϕ
(x)). (2)
19282
0
循环模块,如长短期记忆(LSTM)[41],用于建模视频动
态[20,
89]。注意力机制也被研究用于克服卷积神经网络对短程相
关性优于长期依赖性的倾向。这包括使用自注意力对卷积特
征进行池化[16,85],或者在更近期的工作中[1,5,
23],用Transformer块替换所有卷积层[21,
83]。数据集偏差。众所周知,计算机视觉数据集存在偏差
,即它们的图像组成不准确地反映了真实世界的数据分布[4
7,76,77,
82]。在视频动作识别的背景下,Sigurdsson等人[69]确定
了从互联网中检索到的人类活动视频与我们日常活动之间的
领域差距。Li等人[53]表明,许多从互联网检索到的数据集
存在表征偏差,偏好捕捉动作标签和上下文线索(如对象或
场景)之间的虚假相关性[46,49,
73]。已经收集了新的数据集来克服这个限制:Charades
[69]和VLOG[28]使用了日常活动的视频,而Diving48
[53]和FineGym
[68]则考虑了丰富的细粒度动作类别的体育领域。模型偏差
。在各种机器学习任务中发现了各种形式的算法偏差。例如
,研究发现,数据集中的性别和种族偏差可以被机器学习模
型利用并有时被放大[7,9,39,
91]。在图像识别和目标检测中,背景对象或场景的上下文
偏差已被证明会鼓励学习在新的测试环境中具有较差泛化性
能的模型[4,18,
65]。卷积神经网络的局部连接也可能导致对短程特征(如
颜色、纹理)与长程依赖性(如物体形状)的偏好[31,
85]。以前探索的减轻模型偏差的策略包括对训练样本进行
重新采样[14,54],对抗训练[22,56,
90],构建对抗输入数据[17,
31],或在学习过程中使用正则化损失[2,
11]。知识蒸馏。知识蒸馏最初由Hinton等人[40]引入,是
一种将信息从教师模型传递给(通常较弱的)学生模型的方
法。最初被引入作为模型压缩的解决方案,这种技术后来被
应用于其他问题,包括对抗防御[62]和跨模态转移[36]。
0
3.动态得分
0
在本节中,我们介绍动态得分,这是衡量表示捕捉视频动态
性能的一种方法。
0
3.1.定义
0
视频表示是一个从视频空间X到特征空间Z的映射ϕ:X→
Z。一个K路
0
fϕ
0
x
0
fϕ(x)
0
fϕS(x
)
0
(a)
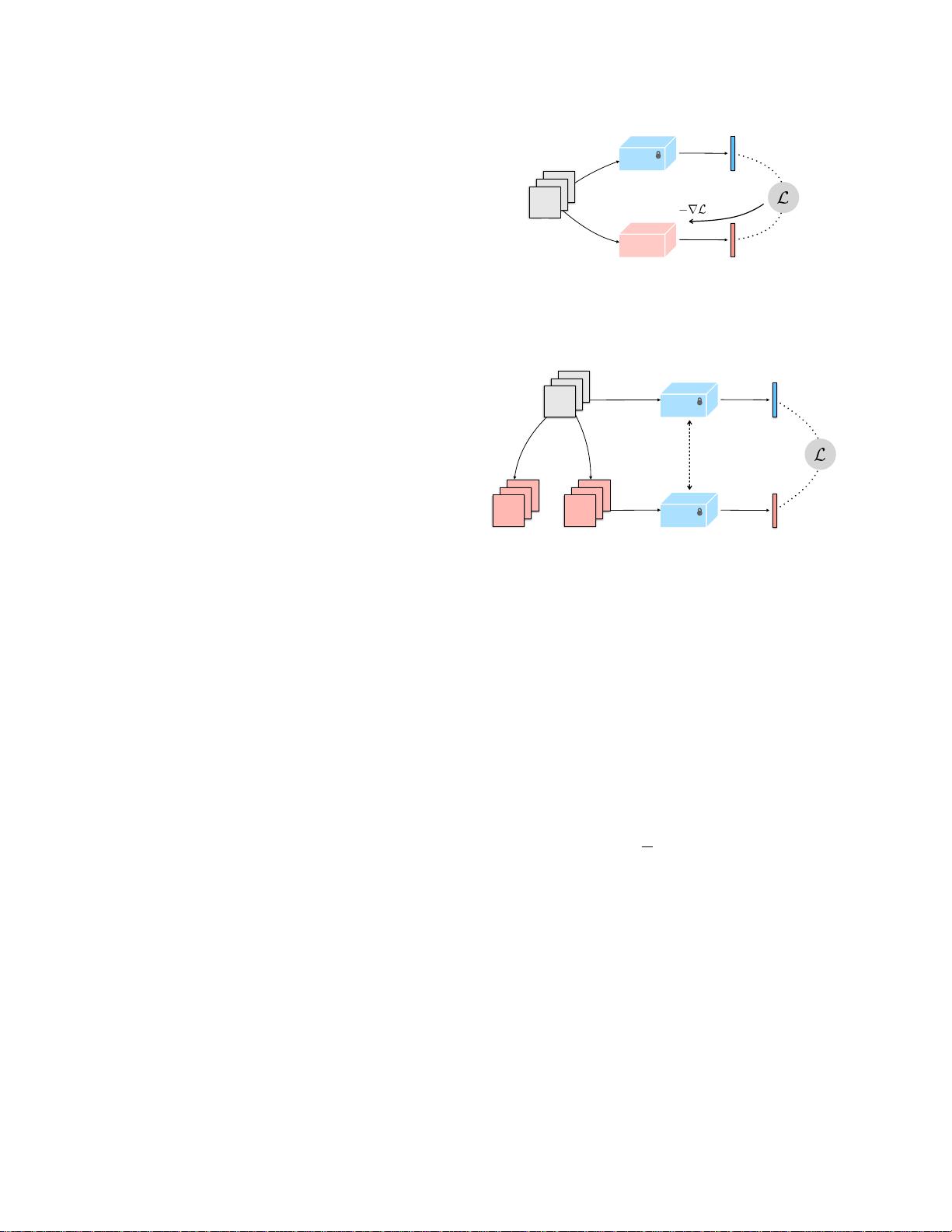
通过知识蒸馏进行测量。训练一个空间分类模型fϕs来预测fϕ的输出
。动态得分定义为标准模型输出fϕ(x)和空间模型输出fϕs(x)之间的
不一致性。
0
冻结
0
洗牌
00
共享权重
0
(b)通过输入调制进行测量。将标准模型输出fϕ(x)
与去除时间信息的调制输入˜x进行比较,可以通过冻结视频片段x
的一个帧或对其帧进行洗牌来去除时间信息。
0
图2.测量视频分类器fϕ的动态分数γ(fϕ,pD)。详见第3.2
节。
0
视频分类器是由特征表示ϕ和线性分类器h:Z→SK
组成的映射fϕ=h◦ϕ,其中SK是K
维概率单纯形。对于一个处理维度为D的T
帧视频片段的通用视频分类器,X=RT×D
。如果视频分类器独立地将空间表示ϕs
应用于视频帧,则称其为纯空间分类器,即
0
T
0
对于某个图像分类器gϕs,令FS
为所有这样的分类器的集合,L:SK×SK→[0,∞)
是模型预测的相似度得分。模型fϕ相对于视频片段分布p
D的动态分数定义如下
0
当fϕ是纯空间的时候(fϕ∈FS
),该值为零,并且随着表示捕捉视频动态的能力增强而增
加,即视频的时间特征。虽然上述定义支持概率分布之间的
任何相似度得分,但我们使用库尔巴克-莱布勒(KL)
剩余11页未读,继续阅读
290 浏览量
137 浏览量
134 浏览量
点击了解资源详情
点击了解资源详情
273 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- ITween插件实用教程:路径运动与应用案例
- React三纤维动态渐变背景应用程序开发指南
- 使用Office组件实现WinForm下Word文档合并功能
- RS232串口驱动:Z-TEK转接头兼容性验证
- 昆仑通态MCGS西门子CP443-1以太网驱动详解
- 同步流密码实验研究报告与实现分析
- Android高级应用开发教程与实践案例解析
- 深入解读ISO-26262汽车电子功能安全国标版
- Udemy Rails课程实践:开发财务跟踪器应用
- BIG-IP LTM配置详解及虚拟服务器管理手册
- BB FlashBack Pro 2.7.6软件深度体验分享
- Java版Google Map Api调用样例程序演示
- 探索设计工具与材料弹性特性:模量与泊松比
- JAGS-PHP:一款PHP实现的Gemini协议服务器
- 自定义线性布局WidgetDemo简易教程
- 奥迪A5双门轿跑SolidWorks模型下载
