语义引导的图注意网络在指称理解中的创新应用
8 浏览量
更新于2025-01-16
收藏 1.49MB PDF 举报
"基于语义引导的图注意网络在指称表达理解中的应用"
本文探讨了在指称表达理解任务中,如何利用语义引导的图注意网络来提升模型的性能和解释性。指称表达理解涉及到识别自然语言描述在图像中的对应对象,这需要对文本和视觉信息进行深入的理解。在传统方法中,区域通常通过CNN特征、空间特征和上下文特征等组合表示,然后用LSTM处理语言表达。然而,这种方法往往受限于单一向量表示,忽视了复杂的语言结构和图像中的结构信息。
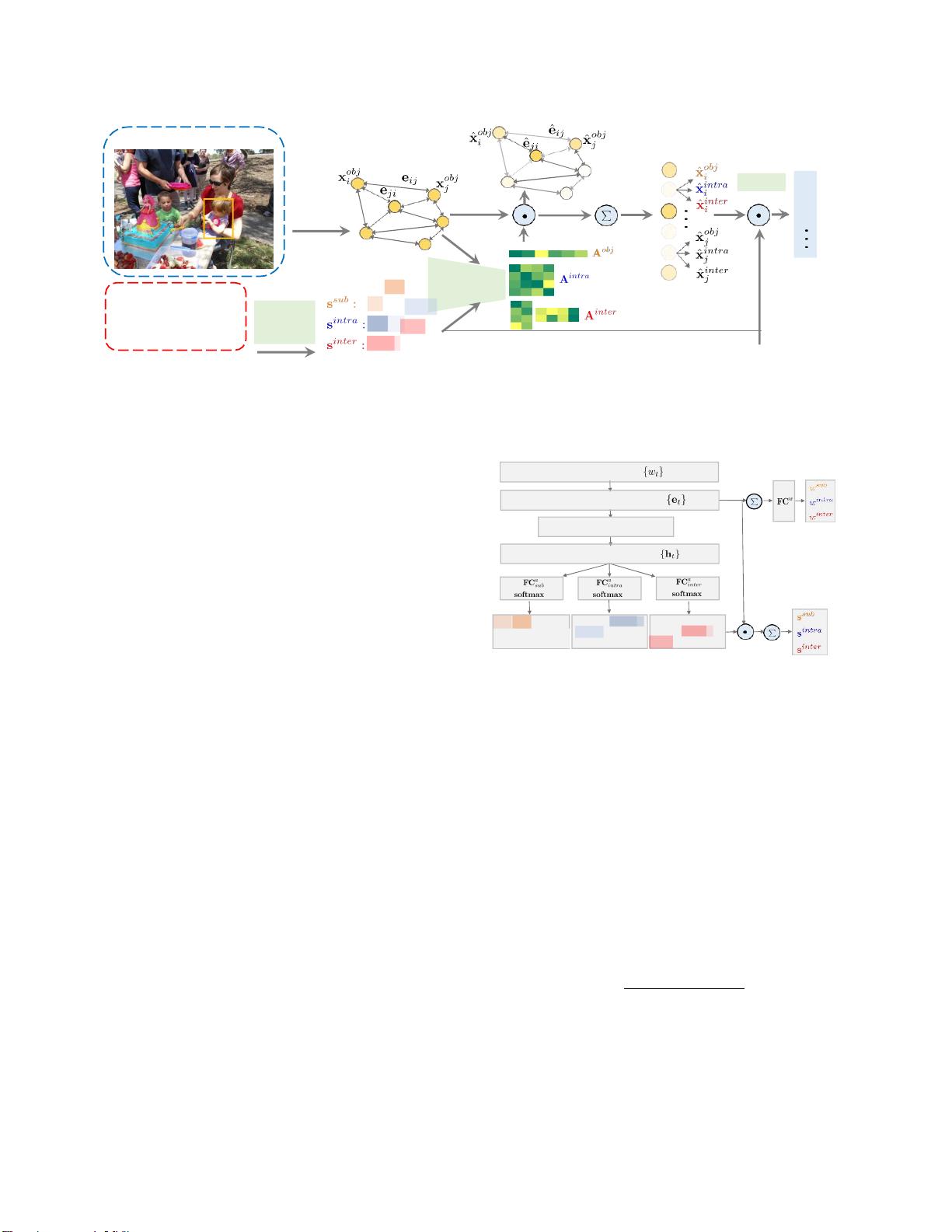
文章提出了一种基于图的、语言引导的注意力机制,通过构建对象实例的有向图来捕获对象间的关系和属性。图中的节点代表对象区域,边则表示类内和类间的关系。图注意力机制包含节点注意力和边注意力,能够灵活、有效地表示对象间的关系,这是传统的竞争方法所不具备的。此外,这种图形注意机制使得决策过程变得可视化和可解释,有助于理解模型的工作原理。
实验结果在三个不同的参考表达式理解数据集上验证了该方法的有效性,证明了所提出的图注意机制在理解和匹配语言表达与图像区域方面的优越性。与以往方法相比,它解决了语言和区域特征独立学习的问题,促进了两种模态特征的相互适应,尤其在处理复杂表达时更具优势。
该研究引入了语义引导的图注意网络,以解决指称表达理解中的关键挑战,即适应复杂的语言表达和理解图像中的结构信息。通过这种创新的注意力机制,模型能够更好地捕捉到对象间的语义关系,从而提高识别精度和可解释性。这一研究对于自然语言处理和计算机视觉的交叉领域具有重要的理论价值和实际应用前景。
1
1962
输入图像
输入引用表达式
被一个女人抱在桌子旁
边的孩子
语言自
我注意
女人
Dbya
i
=1
t
=1
{
t
}
子
一
初始图表示
图表示
匹配评分
图构建
的
在旁
边
引导图
关注
0.2
0.1
0.6
图2.概述了建议的语言引导的图形注意力网络的参考表达理解。该网络由三个模块组成:语言自注意模块、语言引导图形注意模块和
匹配模块。
集合O
={
o
i
}
N
内燃给出了候选对象集
被一个女人抱在桌子旁边的孩子
组件
作为地面实况或通过对象提案一般获得-
方法,如区域建议网络[17],取决于实验设置。我们
在SEC中评估了这两种情况。4.第一章
如示于图
2
、
LGRANs
由三个模块组成:(
1
)语
言自注意模块,它采用自注意方案将表达式
r
分解
为
描述
主题
、
类内关系
和
类间关系的三部分
,并学习
相应的
表达式
s
sub
、
s
intra
和
s
inter
;
(
2
)
语言引导图注
意模块,它在候选对象
O
上构建有向图,突出显示
节点(对象)、类内边(
相同类别的对象)和类间边缘(
来自不同类别的对
象之间的关系),它们
在
S
子
,
S
帧内
和
S
帧间
的指导下与R
相关
,
权重
组件
表示
持有
被一个
桌旁的女人
表
旁边的女人
表
一个女人抱着一
个孩子,
孩子
的
隐向量序列
Bi-LSTM
词嵌入序列
单词序列
图3.语言自我注意模块的图解。
在本文中,我们采用自注意力计划,由于其更好的性
能。图3显示了我们的语言注意力机制的高级概念。给
定表达式
r
,
最后得出三种表达相关的表征类型,
T
字
r
={
w
t
}
T
我们先把单词
不
每个对象的语句;(3)匹配模块,其计算表情到对象
的匹配分数。我们现在详细描述这些模块。
热表示到连续空间{
e
t
}
t
=1
使用非线性映射函数
f
e
.
然
后
{
e
t
}
被馈送到
Bi-LSTM [20]
中以获得一组隐藏状态
表示
h
T
t
=1
. 接下来,三个独立的全连接层如下:
3.1.
语言自我注意模块
将
softmax
层应用于
{
h
t
}
以获得三个
注意力值的类型,是主体注意力
{
a
sub
}
T
,
t t
=1
类内关系注意{
a
intra
}
T
和类间
语言是复合的和单一的向量表示-
不
关系注意
力
T
t
=1
表示(例如LSTM在最终状态的输出)忽略了语言中
的丰富结构。 受将复合语言分解为各种视觉到语言任
务中的子结构的想法的启发[2,5,6,27],我们也将
表达式分解为子组件
t t=1
。由于所有三个分量的注意
力值都是以相同的方式获得的,
为了简单起见,我们仅示出了用于计算主题分量
Rsub
的
细节。让
为了实现指称的目的,指称表达往往会-
a
sub
=
w
a
附
属
公
司
h
t
)
、
(1)
不仅要记录所指对象的属性,还要记录其
与附近物体的关系。因此,我们将表达式r分解为三个
部分:主题r
子
,类内关系-
t
T
i
=1
w
a
附
属
公
司
h
i
)
内部
关系和类间关系。
主要有两种语言解析方法:现成的 语言解析器[2]或
自我注意[5,6,27]。
其中,在图
3
中
w
sub
a
表示FC。 然后,将注意力值
应用于嵌入向量
{
e
t
}
以导出三个表示:
s
sub
、
s
intra
和
s
inter
。
这里
匹配
一张桌
子
孩子
(
(
剩余11页未读,继续阅读

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 普天身份证阅读器新版二次开发包发布
- C# 实现文件的数据库保存与导出操作
- CkEditor增强功能:轻松实现图片上传
- 掌握DLL注入技术:测试工具使用与探索
- 实现带节假日农历功能的jQuery日历选择器
- Spring循环依赖示例:深入理解与Git代码仓库实践
- ABB PLC液压阀门控制程序开发指南
- 揭秘4核旋风密版626象棋引擎的超牛实力
- HTML5实现的经典游戏:小霸王坦克大战源码分享
- 让Visual Studio兼容APM硬件信息的方法
- Kotlin入门:创建我的第一个应用
- Android语音识别技术研究报告与应用分析
- 掌握JavaScript基础:第8版教程源代码解析
- jQuery制作动态侧面浮动图片广告特效教程
- Android PinView仿支付宝密码输入框源码分析
- HTML5 Canvas制作的围住神经猫游戏源码分享
