ZEROQ:无样本量化新框架,实现混合精度优化
PDF格式 | 2.11MB |
更新于2025-01-16
| 190 浏览量 | 举报
"ZeroQ: 一种新的零镜头量化框架"
在神经网络模型的应用中,量化技术已经成为减小模型推理时间和内存占用的关键方法。然而,大多数量化技术依赖于原始训练数据集来进行再训练,这对于处理敏感或专有数据的场景来说是不可行的,因为这可能涉及数据隐私和安全问题。针对这一挑战,"ZeroQ" 提出了一种全新的零镜头量化框架,它不需要访问任何训练或验证数据,实现了混合精度量化。
ZeroQ 的核心在于通过优化蒸馏数据集来完成模型的量化,同时支持均匀和混合精度量化。对于混合精度量化,它引入了一个基于帕累托边界的自动化方法,能自动确定每个层的最佳位宽设置,避免了手动搜索的过程。这种创新的方法不仅保持了模型性能,还在多个模型上,如 ImageNet 上的 ResNet18/50/152 和 MobileNetV2,显示了与现有量化方法相当甚至更高的精度。例如,在 MobileNetV2 上,ZeroQ 可以达到 1.71% 的高精度,与 DFQ 方法相当。
除了性能优势,ZeroQ 还以极低的计算开销著称。它能在短短 30 秒内完成整个量化过程,这仅占 ResNet50 在 ImageNet 上一个训练 epoch 时间的 0.5%,大大提升了效率。此外,ZeroQ 已经开源,可供研究者和开发者使用。
深度学习模型的广泛应用,尤其是在边缘设备上,受到了高内存占用、推理时间和能源消耗的限制。量化是缓解这些问题的有效途径,因为它能将模型的权重和激活值从浮点数转换为整数,从而减少模型大小,加快计算速度,并节省能源。量化还可以减少内存流量,进一步降低能耗。
然而,传统的量化方法往往依赖于重新训练,这对敏感数据应用来说是一个障碍。ZeroQ 的出现打破了这一限制,提供了一种安全且高效的量化策略。通过在不牺牲性能的前提下实现无数据量化,ZeroQ 为隐私保护和高效计算开辟了新的可能性,对推动神经网络模型在各种环境中的部署具有重要意义。
1
13171
10
1
10
0
10
0
10
−
1
10
−
1
10
−
2
10
−
2
10
−
3
10
−
4
10
−
3
1
6
11
16
21
26 31
36
Blocki
→
41 46
51
10
−
5
10
−
6
1
6
11
16
21
26 31
36
Blocki
→
41 46
51
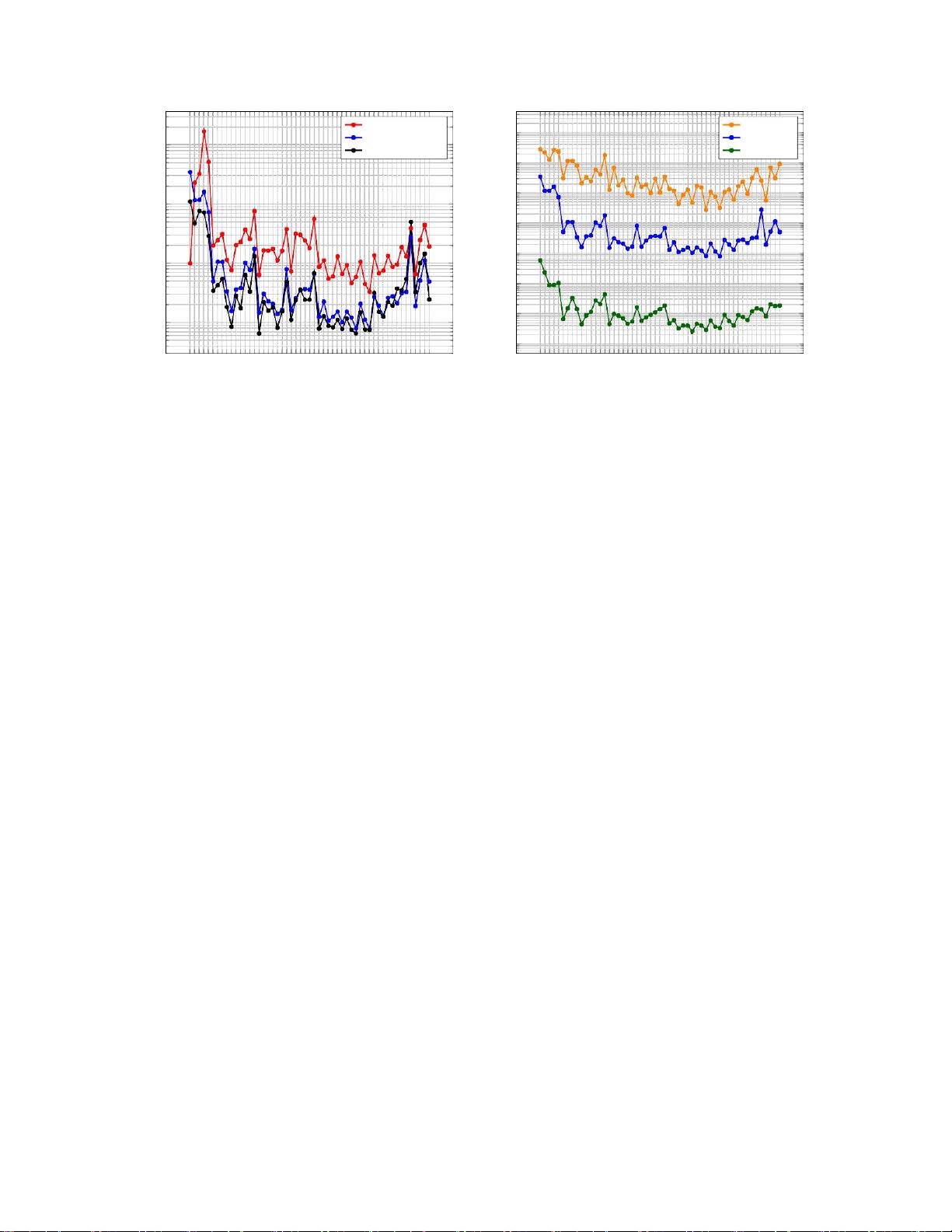
图2:(左)量化为4位权重时ResNet50中每层的灵敏度,使用不同类型的数据测量(右)量化为2/4/8位权重精度
时ResNet 50的灵敏度(使用蒸馏数据测量)。
以解决现代NN架构的过高的存储器占用和推理延迟/
功率。这些方法通常与量化正交,并且它们包括有效
的神经架构设计[17,9,16,36,43],
知识蒸馏[14,35],模型修剪[11,29,24],以及硬件
和NN协同设计[9,21]。这里我们关注量化[2,6 ,
34,41,23,48,45,46,5,8,42],它通过降低用
于表示参数和/或激活的位精度来压缩模型。量化的一
个重要挑战是,它可能导致显著的性能下降,特别是
在超低位精度设置中。为了解决这个问题,现有方法
提出量化感知微调以恢复丢失的性能[20,18,4]。重
要的是,这需要访问用于训练原始模型的完整数据
集。这不仅非常耗时,而且通常无法访问训练数据。
为了解决这个问题,几篇论文专注于开发训练后量
化方法(也称为后量化),而没有任何微调/训练。特
别地,[19]提出了OMSE方法来优化量化张量和原始张
量之间的
L2
此外,[3]提出了所谓的ACIQ方法来解析地
计算限幅范围,以及每个通道的比特分配的神经网
络,它取得了相对较好的测试性能。然而,它们使用
每通道量化用于激活,这在实践中对于有效的硬件实
现是困难的。此外,本发明还提供了一种方法,
[44]提出了一种离群信道分裂(OCS)方法来解决离群
信道问题。然而,这些方法需要访问有限的数据以减
少性能下降[19,3,44,30,22]。
最近[32]的工作提出了无数据量化(DFQ)。它进
一步将后量化推到零-
镜头场景,其中在量化期间训练数据和测试数据都不
可访问。 [32]使用方法 权重均衡方案[30],以去除
权重和激活两者中的离群值,并且与先前的信道量化
的后量化工作[20]相比,它们利用逐层量化实现了类
似的结果。然而,[32]当NN被量化到6位或更低时,它
们的性能显着
我们最近的一篇独立论文提出使用批量归一化统计
来重建输入数据[12]。他们提出了一种基于知识蒸馏
的方法,通过使用所谓的Inceptionism [31]生成与原始
训练数据集相似的输入数据来进一步提高准确性。然
而,尚不清楚后一种方法如何用于诸如 如目标检测
或图像分割。此外,这种知识蒸馏过程增加了零激发
量化所需的计算时间。正如我们将在我们的工作中展
示的那样,可以使用与混合精度量化相结合的批范数
统计量来实现最先进的精度,重要的是这种方法不仅
限 于 图 像 分 类 任 务 。 特 别 是 , 我 们 将 展 示 使 用
RetinaNet-ResNet 50进行对象检测的结果,除了在各种
图 像 分 类 模 型 上 测 试 Z ERO Q ( 使 用 ResNet
18/50/152, Mo-bileNetV 2 , ShuffleNet , SqueezeNext
和InceptionV 3)之外,我们还将展示所有这些情况下
ZERO Q都超过了最先进的量化性能。重要的是,我们
的ap-proach有一个非常小的计算开销。例如,我们可
以在8 V-100系统上在30秒内完成ResNet 50量化(相当
于ImageNet上ResNet 50一个epoch训练时间的0.5%)。
直接量化所有NN层到低精度可能会导致显著的精度
下降。一个有前途的ap-
G
AUS SIAN
D
ISTILLED
D
ATA
T
RAINING
D
ATA
W-BIT=2
W-BIT=4
W-BIT=8
量化为
4
位的灵敏度:
乌布
(
4
)
→
量化为
2/4/8
位的灵敏度:
Ω
i
(2/4/8)
→
剩余10页未读,继续阅读
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- VB通过Modbus协议控制三菱PLC通讯实操指南
- simfinapi:R语言中简化SimFin数据获取与分析的包
- LabVIEW温度控制上位机程序开发指南
- 西门子工业网络通信实例解析与CP243-1应用
- 清华紫光全能王V9.1软件深度体验与功能解析
- VB实现Access数据库数据同步操作指南
- VB实现MSChart绘制实时监控曲线
- VC6.0通过实例深入访问Excel文件技巧
- 自动机可视化工具:编程语言与正则表达式的图形化解释
- 赛义德·莫比尼:揭秘其开创性技术成果
- 微信小程序开发教程:如何实现模仿ofo共享单车应用
- TrueTable在Windows10 64位及CAD2007中的完美适配
- 图解Win7搭建IIS7+PHP+MySQL+phpMyAdmin教程
- C#与LabVIEW联合采集NI设备的电压电流信号并创建Excel文件
- LP1800-3最小系统官方资料压缩包
- Linksys WUSB54GG无线网卡驱动程序下载指南
