融合相机雷达的水面小目标检测提升精准度
PDF格式 | 2.73MB |
更新于2025-01-16
| 61 浏览量 | 举报
本文主要探讨了在内陆水域USV任务中,针对水面小目标检测面临的挑战,尤其是在基于视觉的方法存在的局限性背景下,如何通过融合相机和毫米波雷达的技术来提升检测性能。作者程宇伟、徐胡和刘益民来自清华大学、ORCA-Uboat和西北工业大学,他们提出了一种新颖的雷达-视觉融合策略,旨在解决小目标检测中的光照反射、周围景物反射干扰等问题。
首先,无人水面车辆(USV)的应用领域正在不断扩展,从海洋研究到环境监测和废物清理等,对精确和可靠的环境感知提出了更高要求。在内陆水域中,水面小目标检测对于USV的安全导航和特定任务(如清理漂浮垃圾)至关重要。然而,传统基于视觉的方法在应对这些挑战时表现出局限性,比如高光照导致的过曝光和小目标被遮蔽,以及周围景物反射带来的识别难度。
为解决这些问题,研究者设计了一种深度多尺度融合框架,将RGB图像和毫米波雷达数据相结合。毫米波雷达点云以新的表示形式被引入,其特性如距离、角度和速度信息能够弥补视觉传感器的不足。通过这种融合,算法能够更有效地利用雷达数据,增强对水面小目标的检测能力。
实验证明,相较于单纯的视觉方法,该雷达-视觉融合方案显著提高了平均检测精度,达到当前最先进的水平。此外,这种方法展现出良好的鲁棒性,即使在单传感器失效的情况下也能保持有效的环境感知。研究团队通过他们收集并发布的实际漂流瓶数据集进行测试,验证了这一方法的有效性和实用性。
这篇论文不仅介绍了融合技术在解决水面小目标检测问题上的创新应用,还展示了其在实际场景中的优越性能,对于推动无人水面车辆在内陆水域中的智能化操作具有重要意义。未来,这种融合方法可能成为USV在多样化环境下的标准感知策略。
15265
最近,内陆水域的USV由于其潜在的应用价值而受
到更多的关注,例如,Roboat项目[41,42],其旨在使
用USV在城市水道中进行自主运输。狭窄的陆地水域
环境对水下机器人的目标检测提出了更高的要求和表
面反射、高照明和波浪干扰使得更难以检测通常可能
出现在内陆水域中的小物体,如小石头、为了USV在
内陆水域的安全航行,Hammedi等人
。
[11]在其内陆对
象检测数据集上评估了常见的基于视觉的算法,所述
内陆对象检测数据集包含河边、船只等类别。然而,
在其数据集中没有得出特定的小对象。据我们所知,
USV的小物体检测仍然是相对未开发的领域。
2.2.
基于雷达-视觉融合的目标检测
在高水平的自动驾驶中,为了提高检测的准确性、
鲁棒性和实时性,基于传感器融合的方法已经被广泛
用于物体检测。毫米波雷达能够在恶劣天气条件下稳
健地提供目标的位置和速度信息,而视觉系统提供了
丰富的语义信息,但容易受到恶劣条件的影响。因
此,视觉和雷达的融合被广泛用于自动驾驶中的目标
检测。早期的雷达-视觉融合主要是基于目标级的融
合。 采 用 最近邻算 法 ( NN )和 联 合 概 率 数据 关 联
(JPDA)等数据关联方法对独立的雷达和图像检测流
水线的目标级输出进行融合Wang
等人。
[43]通过识别
雷达检测提供的单眼图像的感兴趣区域(ROI)内的
车辆来实现道路车辆检测和跟踪。对象级融合松散耦
合的视觉和雷达信息。在这种情况下,可以确保检测
系统的鲁棒性,因为当一个传感器发生故障时,另一
个传感器仍然可以工作。然而,目标级融合会带来信
息损失,不能充分利用两个传感器的信息。
随着深度学习的发展,雷达-视觉的深层融合(数据
级和特征级)越来越受到关注。雷达点云是典型毫米
波雷达信号处理流水线的最终输出,也是一种易于获
取的数据。因此,对于深层次的雷达-视觉融合,大多
数工作是基于雷达点云。最近,一些作品[23、16、
13、45、5、22、20、6]探索使用图像和雷达的特征级
融合用于自主车辆中的对象检测。在特征级融合中,
必须从不规则、稀疏的毫米波雷达点云中提取特征。
[20]将雷达点云转换为BEV图像,并使用CNN进行特
征提取。
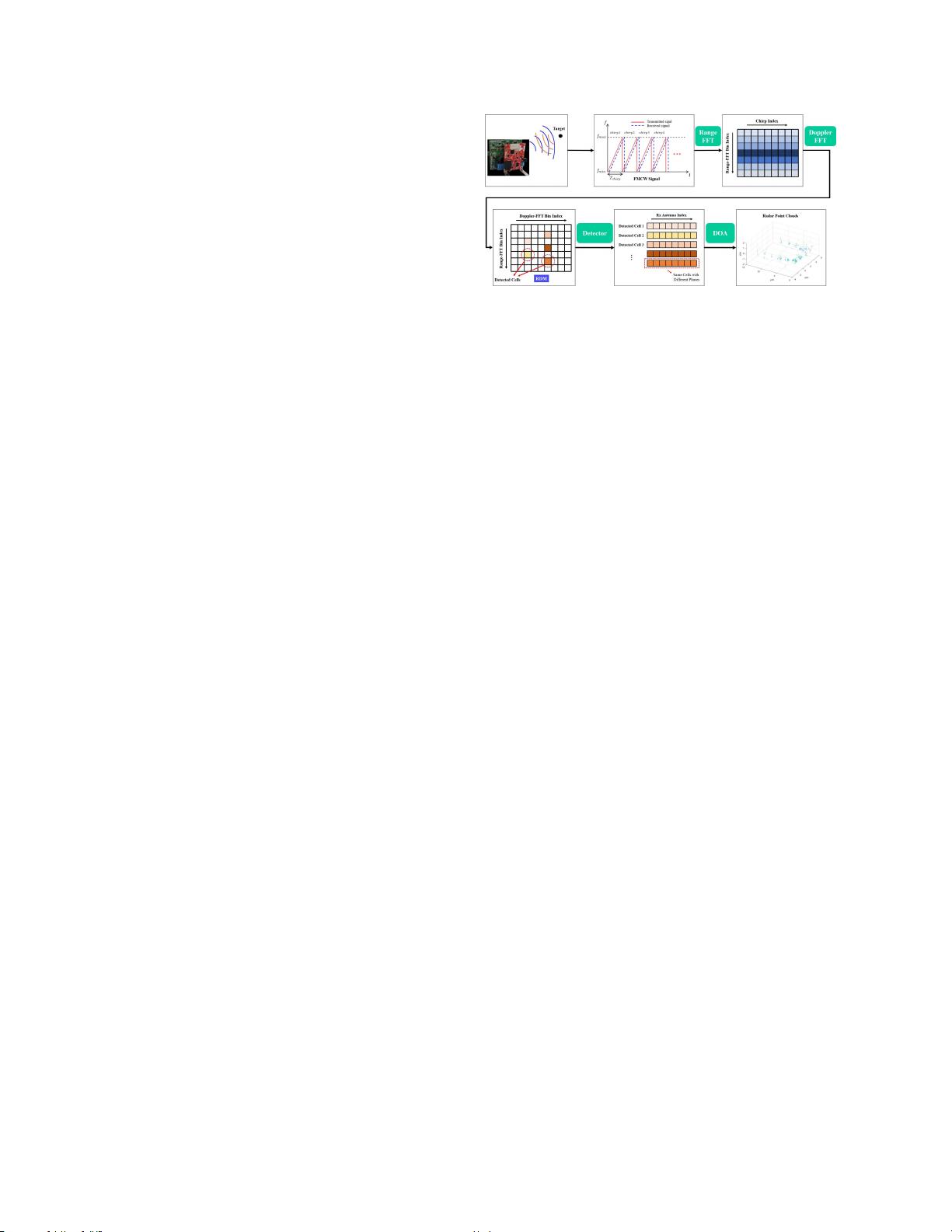
图
4. FMCW
雷达信号处理链。
第[23,16,13,45,5,6]将雷达点云投影到RGB图
像平面作为雷达稀疏图像,然后提取特征。对于RGB
图像和雷达数据的融合,[23,13,5,20]直接融合了
从图像中提取的特征
两种模式。[16,45,6,22]通过引入注意机制改进了
融合的性能由于雷达数据缺乏语义信息,在基于深层
次雷达-视觉融合的目标然而,对于水面上的小目标检
测,视觉信息的鲁棒性降低了很多。因此,充分利用
毫米波雷达数据的鲁棒性,更好地利用雷达数据提供
的信息,提高基于传感器融合的目标检测性能,是一
个值得深入研究的课题。
3.
我们的方法
3.1.
毫米波雷达管线
雷达点云生成。毫米波雷达系统发射调频连续波
(FMCW)并捕获反射波。如图4所示,采样的差拍信
号首先经由距离FFT和多普勒FFT被传递到距离-多普
勒矩阵(RDM)。然后,在检测器处理块中,检测
RDM中具有较强能量的单元。常规FMCW信号处理链
中最常见的检测器是恒虚警率(CFAR)检测器,其根
据周围噪声水平和称为阈值因子的缩放因子来确定检
测阈值。最后,对于每个检测到的小区,通过利用多
个Rx天线的回波信号来执行到达方向(DOA)估计。
因此,我们获得由具有不同位置的多个检测到的对象
组成的所谓的点云雷达点云可以表示为一组点,并且
每个点可以表示为(x
,
y
,
z
,
v
,
p),其中x,y,z
表示雷达点云的XYZ坐标数据,v表示多普勒速度,并
且p表示点的能量。
雷达点云投影R G B 图像为
二维(2D)垂直平面,而雷达数据是
剩余10页未读,继续阅读
相关推荐






cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ruby语言集成Mandrill API的gem开发
- 开源嵌入式qt软键盘SYSZUXpinyin可移植源代码
- Kinect2.0实现高清面部特征精确对齐技术
- React与GitHub Jobs API整合的就业搜索应用
- MATLAB傅里叶变换函数应用实例分析
- 探索鼠标悬停特效的实现与应用
- 工行捷德U盾64位驱动程序安装指南
- Apache与Tomcat整合集群配置教程
- 成为JavaScript英雄:掌握be-the-hero-master技巧
- 深入实践Java编程珠玑:第13章源代码解析
- Proficy Maintenance Gateway软件:实时维护策略助力业务变革
- HTML5图片上传与编辑控件的实现
- RTDS环境下电网STATCOM模型的应用与分析
- 掌握Matlab下偏微分方程的有限元方法解析
- Aop原理与示例程序解读
- projete大语言项目登陆页面设计与实现
