自适应边界建议网络:解决任意形状文本检测难题
145 浏览量
更新于2025-01-16
收藏 3.23MB PDF 举报
本文主要探讨了任意形状文本检测这一具有挑战性的任务,尤其是在场景文本检测领域,如在线教育、产品搜索和视频场景解析中的应用。随着深度学习技术的快速发展,对于能够适应各种复杂和多样场景的任意形状文本检测需求日益增长。当前的任意形状文本检测方法虽然取得了一定的进步,但依然面临着诸如多变形状、纹理和尺度等问题。
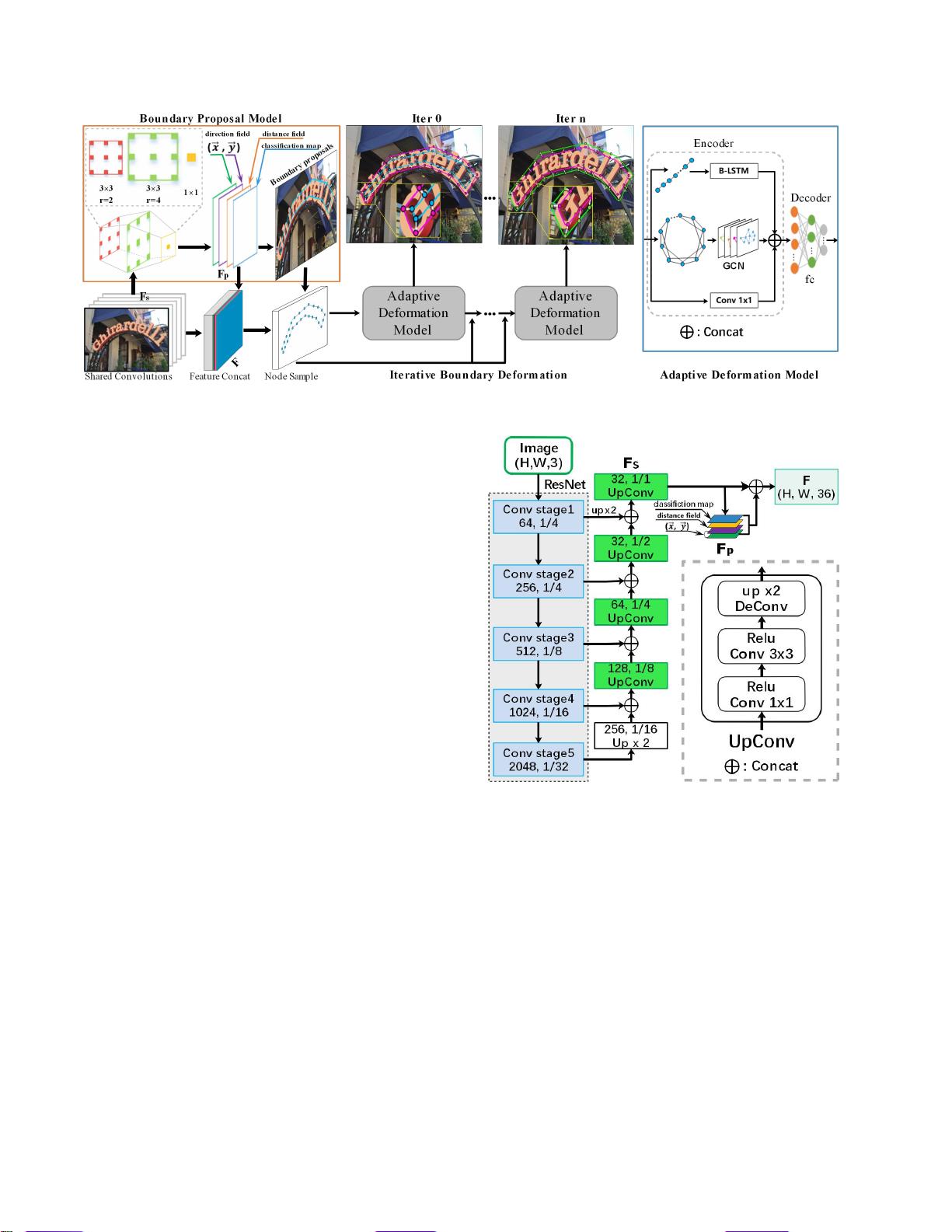
作者提出的自适应边界建议网络(Adaptive Boundary Proposal Network, TextBPN)旨在解决这些问题。核心部分包括两个关键组件:边界建议模型和自适应边界变形模型。边界建议模型采用多层扩张卷积,生成包含分类信息、距离场和方向场的先验信息,以及初步的粗边界建议。这个模型为后续的边界精确化提供了基础。
自适应边界变形模型则是一个编解码器结构,由图卷积网络(Graph Convolutional Networks, GCN)和递归神经网络(Recurrent Neural Networks, RNN)构成。它利用边界建议模型提供的先验信息,通过迭代的方式精细调整边界,从而更准确地捕捉文本实例的形状。这种方法的一大优点在于,它可以直接生成准确的文本边界,避免了传统方法中复杂的后处理步骤,显著提高了检测精度和效率。
论文还提到,尽管基于像素级分割的方法已经在一定程度上增强了对形状变化的鲁棒性,但在处理相邻文本实例的分离方面仍存在问题。为解决这个问题,TextBPN尝试通过自适应边界变形模型来增强实例间的区分能力,减少误检或漏检。
通过在公开可用数据集上的大量实验,作者展示了他们的方法在任意形状文本检测任务上表现出最先进的性能。此外,论文作者还提供了GitHub代码仓库(<https://github.com/GXYM/TextBPN>),以便于其他研究者和开发者进一步研究和应用这一技术。
总结来说,本文贡献了一种创新的任意形状文本检测框架,通过自适应边界处理,提高了文本检测的准确性和效率,为场景文本分析领域的实际应用提供了有力支持。
1307
V
.
.
p
V
/∈
其中
−
B
−
→
p
表示
B
之间的距离
图
2.
我们方法的框架我们的网络主要由共享卷积,边界建议模型,和自适应边界变形模型,这是一个统一的端到端可训练的迭
代优化框架。
3.
该方法
3.1.
概述
我们的方法的框架如图所示二、采用ResNet-50 [6]
提取特征。为了保持空间分辨率并充分利用多级信
息 , 我 们 采 用 了 多 级 特 征 融 合 策 略 ( 类 似 于 FPN
[14]),如图所示3.第三章。由多层扩张卷积组成的边
界提议模型使用共享特征进行文本像素分类,生成距
离场和方向场[37]。然后,我们使用这些信息来产生
粗略的边界建议。每个边界建议由N
个
点组成,代表
一个可能的文本实例。为了细化粗糙的文本边界,提
出了一种自适应边界变形模型,在先验信息(分类
图、距离场和距离场)的指导下进行迭代边界变形,
以获得更精确的文本边界
安装字段)。
3.2.
自适应边界建议网络
3.2.1
边界建议生成
边界建议模型由多层膨胀卷积组成,包括两个不同膨
胀率的3
×
3卷积层和一个1×1卷积层,
图3.共享卷积的体系结构,
FS
表示共享特征,并且
FP
表示先
验信息(分类
图、距离场和方向场)。
测试文本边界上的像素B
p
,如图所示。5.然后,从文
本像素p指向B
p
的二维单位向量
gt
(p)可以公式化
为:
−
B
−
→
p
p/
.
−
B
→
p
p
。
、
p
∈
T
如图2. 它将使用提取
从骨干网生成分类图,
距离场图和方向场图。
类似于其他文本检测方法[42,19,41],
V
gt
(
p
)=
. .
(0
,
0)
,
p
/∈
T
p
(一)
和文本
分类图包含每个像素(文本/非文本)的分类置信度。
如在[37,31]中,方向场
图(
V
)由二维单位向量(
-
x
,
-
y
)组成
,其指示边界中的每个文本像素到其边界上的
最近像素的方向对于文本实例T内的每个像素p,我们
将找到其附近的
像素P和T表示像素P中的文本实例的总集合。
一个形象对于非文本区域(p
T
),我们用(0
,
0)表
示这些像素。单位向量
gt
(p)不仅直接编码p在T中的
近似相对位置并突出显示相邻文本实例之间的边界
[37],而且还提供方向指示信息。
剩余11页未读,继续阅读

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机组成原理期末试题及答案(2011参考)
- 均值漂移算法深入解析及实践应用
- 掌握npm与yarn在React和pg库中的使用
- C++开发学生信息管理系统实现多功能查询
- 深入解析SIMATIC NET OPC服务器与PLC的S7连接技术
- 离心式水泵原理与Matlab仿真教程
- 实现JS星级评论打分与滑动提示效果
- VB.NET图书馆管理系统源码及程序发布
- C#实现程序A监控与自动启动机制
- 构建简易Android拨号功能的应用开发教程
- HTML技术在在线杂志中的应用
- 网页开发中的实用树形菜单插件应用
- 高压水清洗技术在储罐维修中的关键应用
- 流量计校正方法及操作指南
- WinCE系统下SD卡磁盘性能测试工具及代码解析
- ASP.NET学生管理系统的源码与数据库教程
