LwM: 新增信息保持惩罚与注意力蒸馏损失提升增量学习性能
200 浏览量
更新于2025-01-16
收藏 1.85MB PDF 举报
增量学习(Incremental Learning, IL)是一种机器学习领域的关键挑战,目标是让模型在面对不断增加的新类别时能够持续改进其性能,同时保持对已有类别的识别能力。传统的训练模型往往受限于固定的类别数量,一旦增加新类别,就可能面临灾难性遗忘问题,即模型会忘记已学习的基础类别。
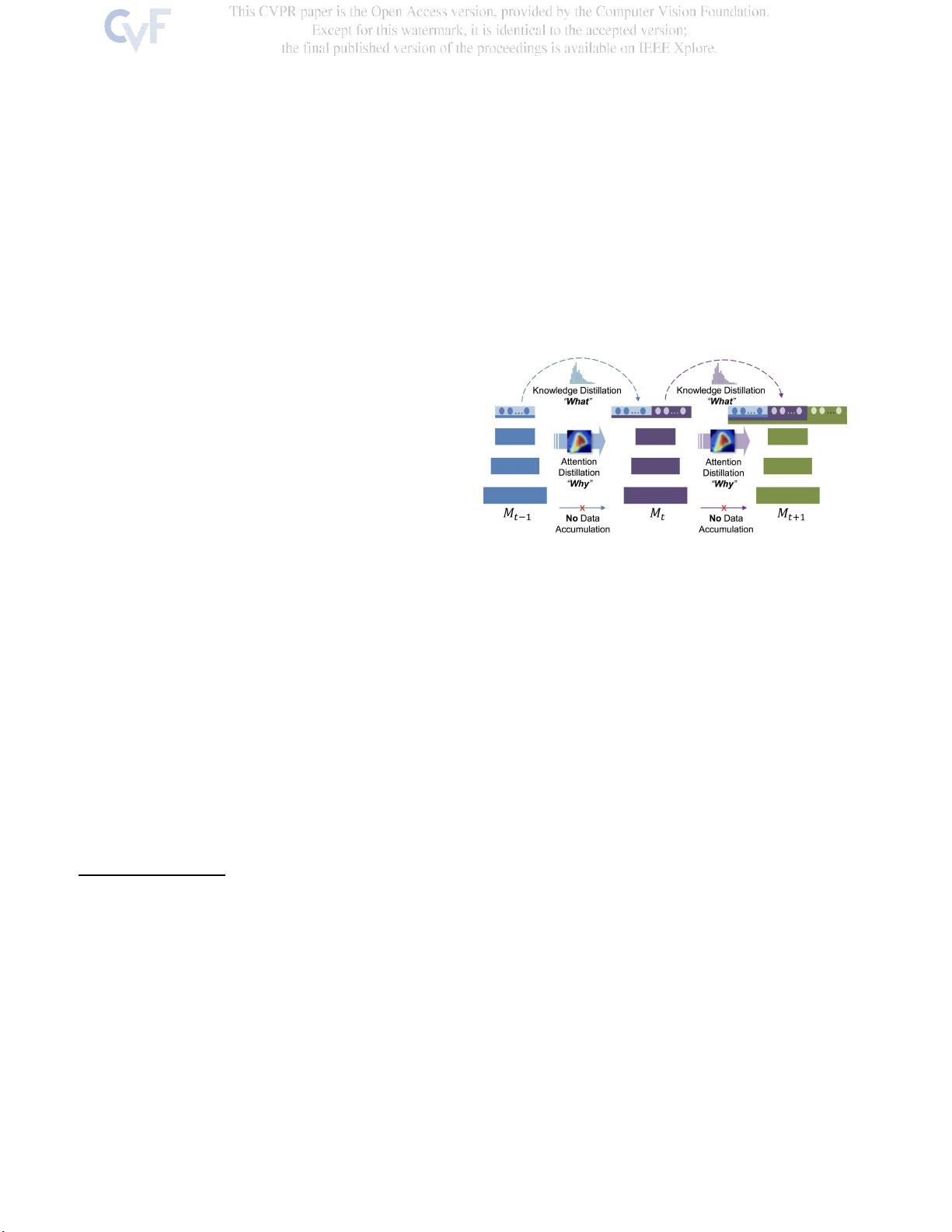
为了解决这个问题,本文提出了一个新的方法——LwM(Lightweight Memory, 轻量级记忆),其中的关键创新是引入了一个名为Attention Distillation Loss (LAD)的信息保持惩罚。LAD关注的是模型在处理新任务时注意力分布的变化,通过这种方式,它能够有效地抑制模型对新类别学习过度而忽视原有知识的情况。
LAD是在现有蒸馏损失的基础上发展起来的,蒸馏损失是一种信息保留策略,旨在确保模型在接收新数据时能保留对旧知识的记忆。通过结合LAD,研究者证明了这种惩罚能够显著提升模型在既定和新增类别上的整体准确性,从而实现增量学习过程中良好的知识迁移和保持。
论文的研究背景指出,许多先进的视觉识别系统依赖于专门针对任务训练的模型,但这类模型的复杂性随着目标类别的增加而受限。为了适应不断变化的环境,如工业应用中的对象分类,模型需要具备动态学习的能力,既能处理新出现的类别,又不会丢失原有的识别能力。
LwM方法通过控制注意力分布,实现了存储效率的提升,这对于资源受限的边缘设备尤为重要,如在内存有限的设备上进行实时学习。它克服了存储旧类别数据或编码信息的模型所带来的扩展性问题,并在实际场景中展示了其有效性和实用性。
这篇论文提出了一种创新的增量学习策略,通过LAD惩罚机制,平衡了新类别学习和旧类别保持,有助于构建一个在不断变化的任务环境中更加灵活和高效的模型。这对于推动人工智能在实际场景中的应用具有重要意义。
5138
学而不记
Prithviraj Dhar*
1
,Rajat Vikram Singh*
2
,Kuan-Chuan Peng
2
,Ziyan Wu
2
,Rama
Chellappa
11
马里兰大学帕克分校
2
Siemens Corporate Technology,新泽西
{prithvi,rama}@ umiacs.umd.edu,{singh.rajat,kuanchuan.peng,ziyan.wu}@ siemens.com
摘要
增量学习(
IL
)是一项重要的任务,旨在提高训练
模型的能力,在模型可识别的类的数量方面。在这个
任 务 中 的 关 键 问 题 是 存 储 数 据 的 要 求 ( 例 如 , 图
像),同时教导分类器学习新的类。然而,这是不实
际的,因为它在每一个递增步骤中增加了存储器需
求,这使得不可能在具有有限存储器的边缘设备因
此,我们提出了一种新的方法,称为在
LwM
中,我们
提 出 了 一 个 信 息 保 持 惩 罚 :
Atten- tion
蒸 馏 损 失
(
L
AD
),并证明了惩罚分类器的注意力地图的变化我
们表明,将
LAD
添加到蒸馏损失(这是一种现有的信息
保留损失)中,在基础和增量学习类的整体准确性
1.
介绍
视觉识别任务的大多数最先进的解决方案都使用
专门为这些任务训练的模型[6,13]。对于涉及类别的
任务(如对象分类、分割),任务的复杂度(即目标
类的数量)限制了这些训练模型的能力。例如,一个
用于对象识别的训练模型只能对它所训练的对象类别
进行分类。但是,如果目标类的数量增加,则必须以
这样的方式更新模型,即它在其上的原始类上表现良
好。
* 这些作者对这项工作做出了同样的贡献,部分工作是在PD在
西门子公司技术实习期间完成的
图1:我们的问题设置没有存储与在之前的增量步骤中学习
的类
被训练的类,也被称为基类,同时它也会逐渐学习新
的类
如果我们只在新的、以前看不见的类上重新训练模
型, 它会 完全忘记基类,这被称为灾 难性 遗忘[9,
10],这是一种在人类学习中通常不会观察到的现象。
因此,大多数现有的解决方案[4,14,18]通过允许模
型保留基类的一部分训练数据,同时增加学习新类来
探索增量学习(IL)。Yu等人。[18]提出保留编码基
类信息的训练模型,将其知识转移到学习新类的模型
中然而,该过程是不可扩展的。这是因为存储基类数
据或对基类信息进行编码的模型此外,在工业环境
中,当训练的对象分类模型被递送给最终用户时,训
练数据出于专有原因而保持私有。因此,最终用户将
无法更新训练模型以在缺少基类数据的情况下并入新
此外,存储基类数据用于增量学习新类不是生物学
上的启发。 例如,当幼儿学习识别新的形状/物体
时,观察到它不会完全忘记它已经知道的形状或物
体。它也不总是需要重温旧的信息时,学习
下载后可阅读完整内容,剩余8页未读,立即下载
200 浏览量
1599 浏览量
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- A7Demo.appstudio:探索JavaScript应用开发
- 百度地图范围内的标注点技术实现
- Foobar2000绿色汉化版:全面提升音频播放体验
- Rhythm Core .NET库:字符串与集合扩展方法详解
- 深入了解Tomcat源码及其依赖包结构
- 物流节约里程法的文档整理与实践分享
- NUnit3.vsix:快速安装NUnit三件套到VS2017及以上版本
- JQuery核心函数使用速查手册详解
- 多种风格的Select下拉框美化插件及其js代码下载
- Mac用户必备:SmartSVN版本控制工具介绍
- ELTE IK Web编程与Web开发课程内容详解
- QuartusII环境下的Verilog锁相环实现
- 横版过关游戏完整VC源码及资源包
- MVC后台管理框架2021版:源码与代码生成器详解
- 宗成庆主讲的自然语言理解课程PPT解析
- Memcached与Tomcat会话共享与Kryo序列化配置指南
