全球视角的图像裁剪:多元作物集合预测新方法
PDF格式 | 1.45MB |
更新于2025-01-16
| 113 浏览量 | 举报
"这篇论文提出了一种新的图像裁剪方法,通过集合预测法来处理全球多元作物的裁剪问题,克服了传统锚点评价法和坐标回归法的局限性。研究中,作者将图像裁剪视为一个集合预测任务,利用多个可学习的锚点回归作物集合,再通过匹配和分类器训练选择有效的作物子集。为解决集合预测法可能导致的有效性标签不一致问题,文章提出了两种不同的标签平滑策略,一种适用于密集质量标签的数据集,另一种适用于稀疏标记数据集。实验结果显示,这种方法在公共数据集上表现优于当前最先进的技术。"
本文的核心知识点包括:
1. **图像裁剪技术**:图像裁剪是提高图像视觉效果的关键技术,常用于图像合成和编辑,使得非专业人士也能方便地使用。
2. **锚点评价法**:传统的图像裁剪方法之一,通过预定义的锚点(固定大小和位置的框)对图像进行评估,输出不同作物的评分,但可能因锚点限制而遗漏优质作物。
3. **坐标回归法**:另一种方法,直接回归输入图像上作物的坐标,能全局考虑,但仅输出一个最佳作物,忽略了多样性。
4. **集合预测法**:文中提出的新型方法,结合锚点评价和坐标回归的优点,从多个学习到的锚点回归作物集合,允许模型预测多样性的作物,同时具有全局性。
5. **有效性标签平滑**:为解决集合预测法的标签一致性问题,论文提出了两种策略:一是根据作物质量直接指导的平滑方法,适用于有密集质量标签的数据;二是基于自蒸馏的平滑方法,适用于稀疏标注数据。
6. **深度CNN**:近年来,基于深度卷积神经网络(CNN)的数据驱动方法在图像裁剪中广泛应用,能够学习复杂的图像特征。
7. **模型比较**:文中对比了新方法与传统方法的优劣,实验表明新方法在复杂性和性能上具有优势。
8. **实验验证**:通过在公共数据集上的实验,证明了新方法在作物裁剪效果上的优越性,超越了现有的最先进的技术。
9. **应用领域**:图像裁剪技术不仅限于专业摄影,还广泛应用于社交媒体、广告设计、图像分析等多个领域,新方法的提出有助于提升这些领域的效率和质量。
2448
∈
我
{1}
|
}
(
一
)
图
2.
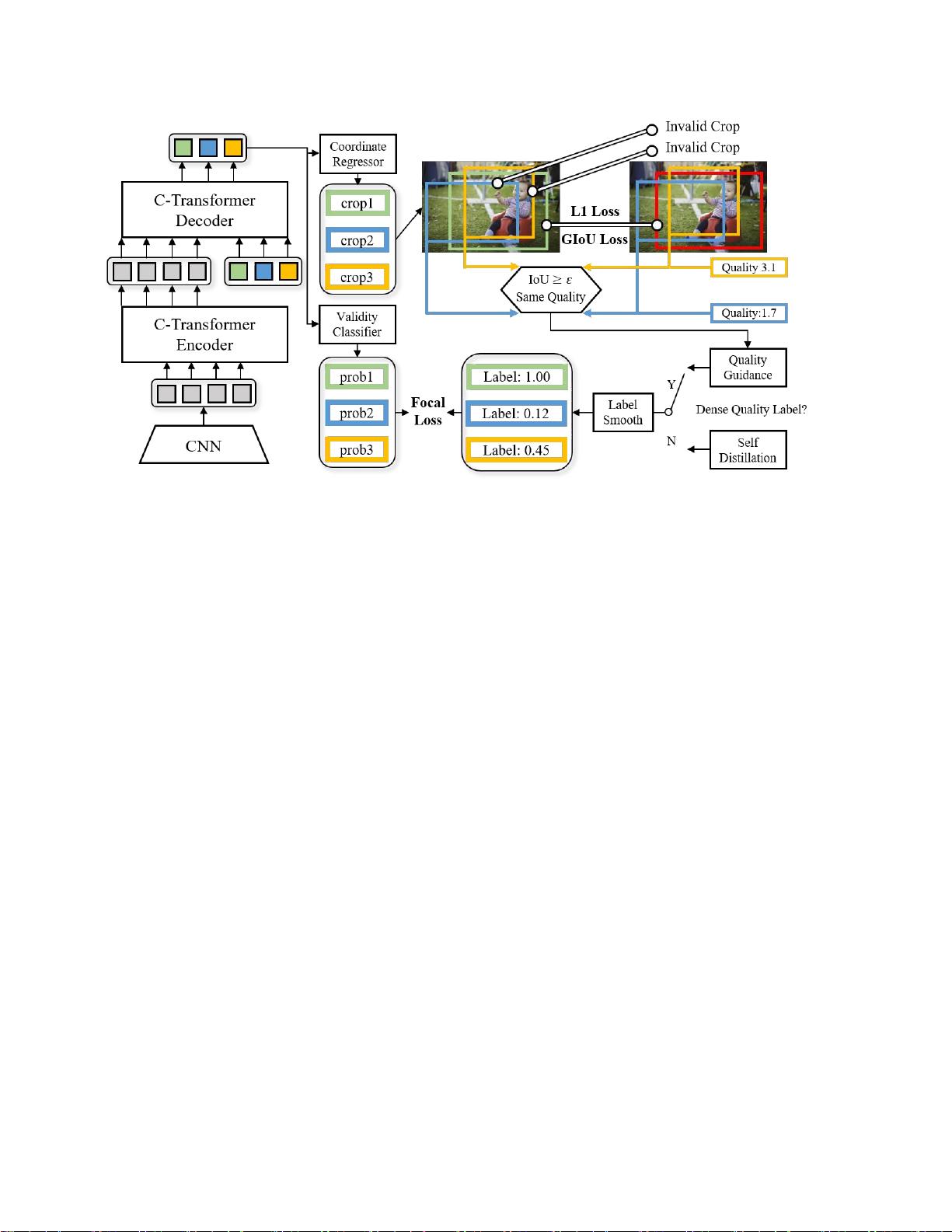
我们的模型框架。左侧部分是模型架构,包含
CNN
主干、条件
Transformer
编码器、条件
Transformer
解码器和两个预测头。
该模型预测每个锚点的裁剪和有效性概率(表示为彩色正方形)。右部分描述了二分匹配和标签平滑过程。预测的绿色作物与
给定的良好作物相匹配(红色框)。 在密集标记的数据集中,我们通过找到无效作物的高
IoU
邻居(右上角图像中的相同颜
色作物)来估计其质量分数,并使用分数来指导标签平滑。在稀疏标签数据集中,我们使用自蒸馏来平滑标签。
[45]包 括标 签正 则化 、标 签 关系 挖掘 和噪 声标 签学
习。这三个功能永远不会单独发挥作用[42]。通过挖
掘不同数据、类或学习阶段之间的关系,从简单的均
匀平滑[35]到一些更复杂的形式[10,19,21,45],已
经做出了许多努力。也有一些作品试图解释的机制和
其他技术的关系[25,29]。本文中的标签平滑是一种
标签关系挖掘方法,通过使质量相近的作物具有相近
的标签。
3.
方法
3.1.
基于集合预测的
我们介绍了我们的模型从传统的坐标回归模型的演
变路径。从这个角度来看,只有
多样性
需要增加,因
为
全球性
已经配备。因此,我们将任务分解为两个子
任务。第一子任务使模型能够预测固定数量的多种作
物,第二子任务将固定数量放宽为任意数量。
为了实现第一个目标,我们采用多输入有限元-
tures,
即
,锚,回归多种作物。具体地说,
chors和图像作为输入具有两种不同的功能。第一个函
数在不同的锚之间交换信息。第二功能将来自输入图
像的信息发送到锚。最后,利用回归头
预测作物
长势
。
从锚
q
i
的
R4
。
在第一个子任务中,我们定义一个足够大的锚数
N
q
。但两个新问题出现了。首先,来自第
j
个图像的好
作物的数量
N
B
j
可能达不到
N
q
,即,
N
B
j
< N
q
.
第
二,不同的图像可以具有不同数量的好作物,即,
N
B
j
=
N
B
i
。因 此 ,在第二子任务中,我们创建了
一个辅助的二元分类器来从所有
N
q
个
回归作物中找
到不同的有效子集。
分 类
器输出表示
输入图像
Ij
中的回
归作物
y
i
的有效性概率
。
为了训练有效性分类和坐标回归,使用与
[ 2 ]
相同
的匈牙利算法在标记的好作物和锚预测
之间执行二
分匹配。具 体 地,将
N
B
j
个
好作物填充到
N
q
。在
填充之后,我们具有地面实况标签集
Yj
=
yi i
=
1
,
2
,
.
,
其中
y
i
包含好作物的坐标
bi
和有效
性标签
vi
,
.
{
bi
=
[
c
x
,
c
y
,
w
,
h
]
,
v
i
= 1
}
1
≤
i
≤
N
B
j
我们随机初始化一组可学习的锚
q
i
∈
RC
,其中
i
∈
{1
,
2
,
.
,
N
q
}
。一个模型,既需要一个
-
y
i
=
{
bi
= 0
,
v
i
= 0
}
N
B
j
+
1≤
i
≤
N
q
剩余10页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- VB通过Modbus协议控制三菱PLC通讯实操指南
- simfinapi:R语言中简化SimFin数据获取与分析的包
- LabVIEW温度控制上位机程序开发指南
- 西门子工业网络通信实例解析与CP243-1应用
- 清华紫光全能王V9.1软件深度体验与功能解析
- VB实现Access数据库数据同步操作指南
- VB实现MSChart绘制实时监控曲线
- VC6.0通过实例深入访问Excel文件技巧
- 自动机可视化工具:编程语言与正则表达式的图形化解释
- 赛义德·莫比尼:揭秘其开创性技术成果
- 微信小程序开发教程:如何实现模仿ofo共享单车应用
- TrueTable在Windows10 64位及CAD2007中的完美适配
- 图解Win7搭建IIS7+PHP+MySQL+phpMyAdmin教程
- C#与LabVIEW联合采集NI设备的电压电流信号并创建Excel文件
- LP1800-3最小系统官方资料压缩包
- Linksys WUSB54GG无线网卡驱动程序下载指南
