"认知AI:超越深度的黑暗常识"
PDF格式 | 5.82MB |
更新于2025-01-16
| 13 浏览量 | 举报
工程
6
(
2020
)
310
研究
人工智能
-
专题文章
黑暗,超越深度:一个具有人类常识的认知AI的范式转变
朱一新
a
,
刘
晓波a,高
涛
a
,范立峰
a
,黄思远
a
,马克·埃德蒙兹
a
,刘航新
a
,高
峰
a
,张驰
a
,
四元奇
a
,影念武
a
,约书亚B。特南鲍姆
b
,朱松春
a
a
视觉、认知、学习和自主中心,加利福尼亚大学,洛杉矶,
CA 90095
,美国
b
美国麻省理工学院大脑、思维和机器中心,剑桥,
MA 02139
阿提奇莱 因福奥
文章历史记录:
收到2019年
2019
年
12
月
11
日修订
2020年1月3日接受
2020年2月22日在线提供
保留字:
计算机视觉人工智能
直观的物理功能感知的
意图实用程序
A B S T R A C T
深度学习的最新进展基本上是基于“小任务的大数据”范式,在这种范式下,大量的数据被用来为单个窄任务训
练分类器。在本文中,我们呼吁改变这种范式。具体来说,我们提出了一个“大任务的小数据”范式,其中单个
人工智能(AI)系统面临着开发“常识”的挑战,使其能够用很少的训练数据解决各种任务。我们通过回顾综合
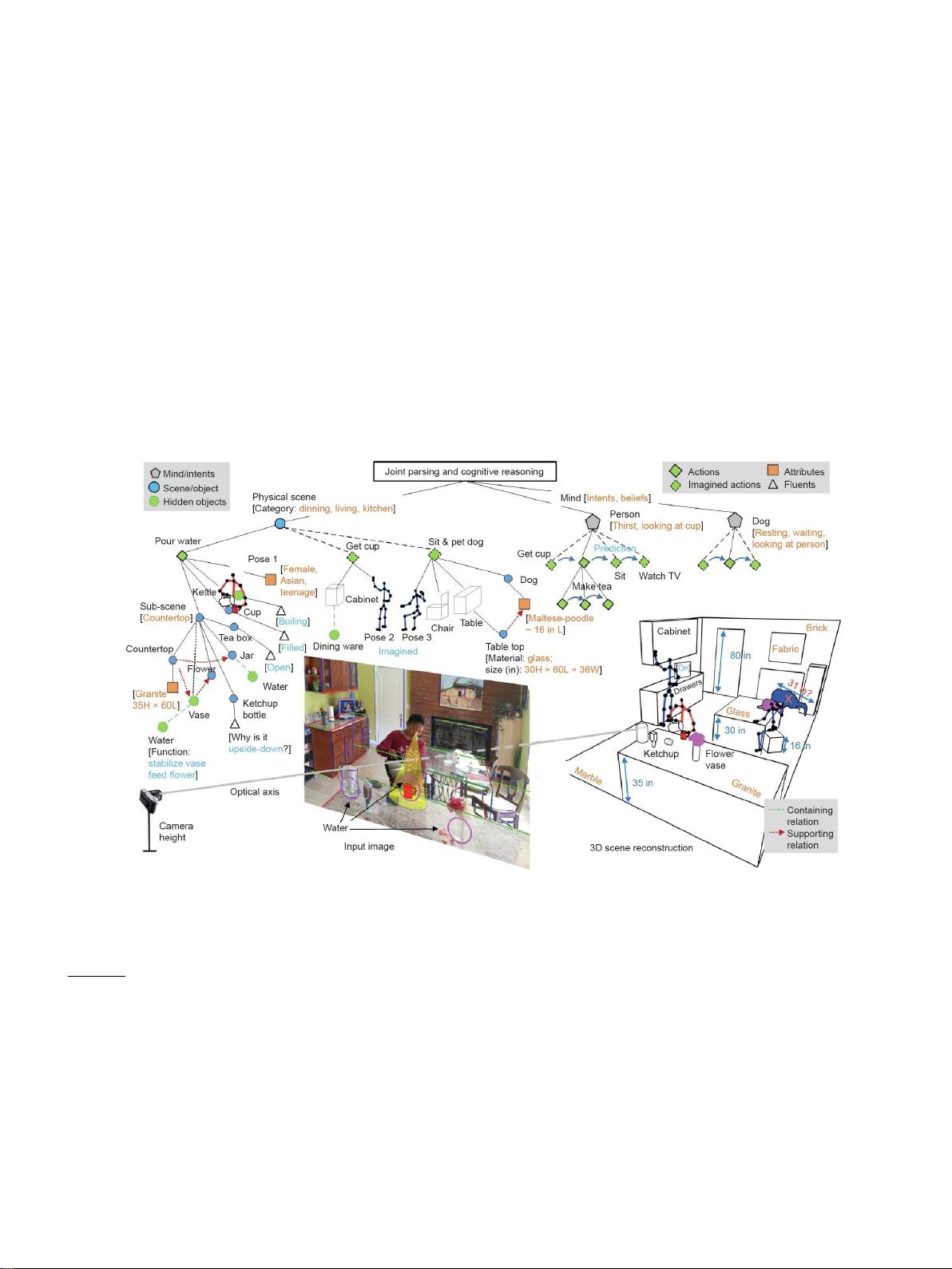
了机器和人类视觉最近突破的常识模型来说明这种新范式的潜在力量。我们将功能、物理、意图、因果和效用
(FPICU)确定为具有人类常识的认知AI的五个核心领域当作为一个统一的概念时,FPICU关注的是“为什么”
和“如何”的问题它们在像素方面是不可见的,但却推动着视觉场景的创造、维护和发展。因此我们称它们为视
觉的“暗物质”。正如我们的宇宙不能仅仅通过研究可观察物质来理解一样,我们认为,如果不研究FPICU,就
不能理解视觉。我们展示了这种观点的力量,通过展示如何观察和应用FPICU来解决各种具有挑战性的任务,
包括工具使用,规划,效用推理和社会学习,开发具有人类常识的认知AI系统。总之,我们认为下一代人工智
能必须接受“黑暗”的人类常识来解决新的
©2020 THE COUNTORS.Elsevier LTD代表中国工程院出版,
高等教育出版社有限公司。这是一篇CC BY-NC-ND许可下的开放获取文章
(
http://creativecommons.org/licenses/by-nc-nd/4.0/
)。
1.
对视觉和人工智能范式转变的呼吁
计算机视觉是人工智能的大门,是现代智能系统的重要组成部分
由先驱
David Marr
提出的计算机视觉的经典定义
[1]
是看
“
什么
”
是
“
在哪里
”
。这里,这种定义对应于人脑中的两条通
路:①腹侧通路用于物体和场景的分类识别,②背侧通路用于深度
和形状、场景布局、视觉引导动作等的重构。这一范式指导了基于
几何的
*
通讯作者。
电子邮件地址:
yixin.zhu@ ucla.edu(Y。Zhu)。
20
世纪
80 - 90
年代的计算机视觉方法
在过去的几年里,随着深度神经网络(DNN)的快速发展,在硬件
加速和大量标记数据集的可用性的推动下,在对象检测和定位方面取得
了进展。然而,我们离解决计算机视觉或真正的机器智能还很远;当前计
算机视觉系统的推理和推理能力是狭窄的,高度专业化的,需要为特殊
任务设计的大量标记训练数据集,并且缺乏对常见事实的普遍理解-即对
普通人类成年人来说显而易见的事实-描述我们的物理和社会世界如何工
作。为了填补现代计算机视觉和人类视觉之间的差距,我们必须找到一
个更广阔的视角,从这个视角来建模和推理缺失的维度,即人类的常
识。
https://doi.org/10.1016/j.eng.2020.01.011
2095-8099/
©
2020 THE COMEORS.
由爱思唯尔有限公司代表中国工程院和高等教育出版社有限公司出版。这是一篇基于
CC BY-NC-ND
许可证的开放获取文章
(
http://creativecommons.org/licenses/by-nc-nd/4.0/
)。
可在ScienceDirect上获得目录列表
工程
杂志 主页:
www.elsevier.com/locate/eng


剩余35页未读,继续阅读
相关推荐








cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握PerfView:高效配置.NET程序性能数据
- SQL2000与Delphi结合的超市管理系统设计
- 冲压模具设计的高效拉伸计算器软件介绍
- jQuery文字图片滚动插件:单行多行及按钮控制
- 最新C++参考手册:包含C++11标准新增内容
- 实现Android嵌套倒计时及活动启动教程
- TMS320F2837xD DSP技术手册详解
- 嵌入式系统实验入门:掌握VxWorks及通信程序设计
- Magento支付宝接口使用教程
- GOIT MARKUP HW-06 项目文件综述
- 全面掌握JBossESB组件与配置教程
- 古风水墨风艾灸养生响应式网站模板
- 讯飞SDK中的音频增益调整方法与实践
- 银联加密解密工具集 - Des算法与Bitmap查看器
- 全面解读OA系统源码中的权限管理与人员管理技术
- PHP HTTP扩展1.7.0版本发布,支持PHP5.3环境
