GHVAE:解决大规模视频预测的内存优化方法
64 浏览量
更新于2025-01-16
收藏 1.09MB PDF 举报
【贪婪分层变分自编码器(GHVAE):解决大规模视频预测的创新方法】
视频预测模型对于智能代理,如机器人,至关重要,因为它允许它们通过模型规划执行多样化任务。然而,现有的视频预测模型在处理大规模、多样化的数据集时,往往面临严重的欠拟合问题。现有的技术限制,特别是GPU或TPU的内存限制,成为了优化大型模型的关键障碍。
GHVAE,即贪婪分层变分自动编码器,是针对这一问题提出的一种创新解决方案。它通过借鉴深度层次潜变量模型的优势,如捕捉未来观测的多级随机性,以产生高质量预测,同时解决了内存瓶颈。GHVAE的核心理念在于采用分层自动编码器的模块化和贪婪训练策略。
传统的分层变分自编码器(VAE)在训练过程中需要一次性加载整个模型,这在内存有限的设备上难以实现。而GHVAE通过逐级训练,每层都利用先前已训练好的模块的固定权重,这种方法允许模型在不增加内存需求的情况下进行扩展。这种贪婪训练方式不仅降低了内存压力,还通过打破潜在变量间的双向依赖关系,提高了模型的优化稳定性。
GHVAE的独特之处在于其预测能力的显著提升。与最先进的模型相比,GHVAE在四个视频数据集上的预测性能提升了17%至55%,在实际的机器人任务中,成功率也得到了35%至40%的提升。而且,模型的性能可以通过简单地添加更多的模块来进一步增强,显示出良好的可扩展性。
总结来说,GHVAE是一种在大规模视频预测领域具有竞争力的模型,它通过巧妙地利用内存资源和改进的优化策略,实现了在保持高质量预测的同时,有效应对大规模数据集的挑战。这种模型的引入对于推动智能代理在现实世界中的应用具有重要意义,特别是在机器人技术、自动驾驶等领域,为未来的高效预测提供了新的可能。
1
2320
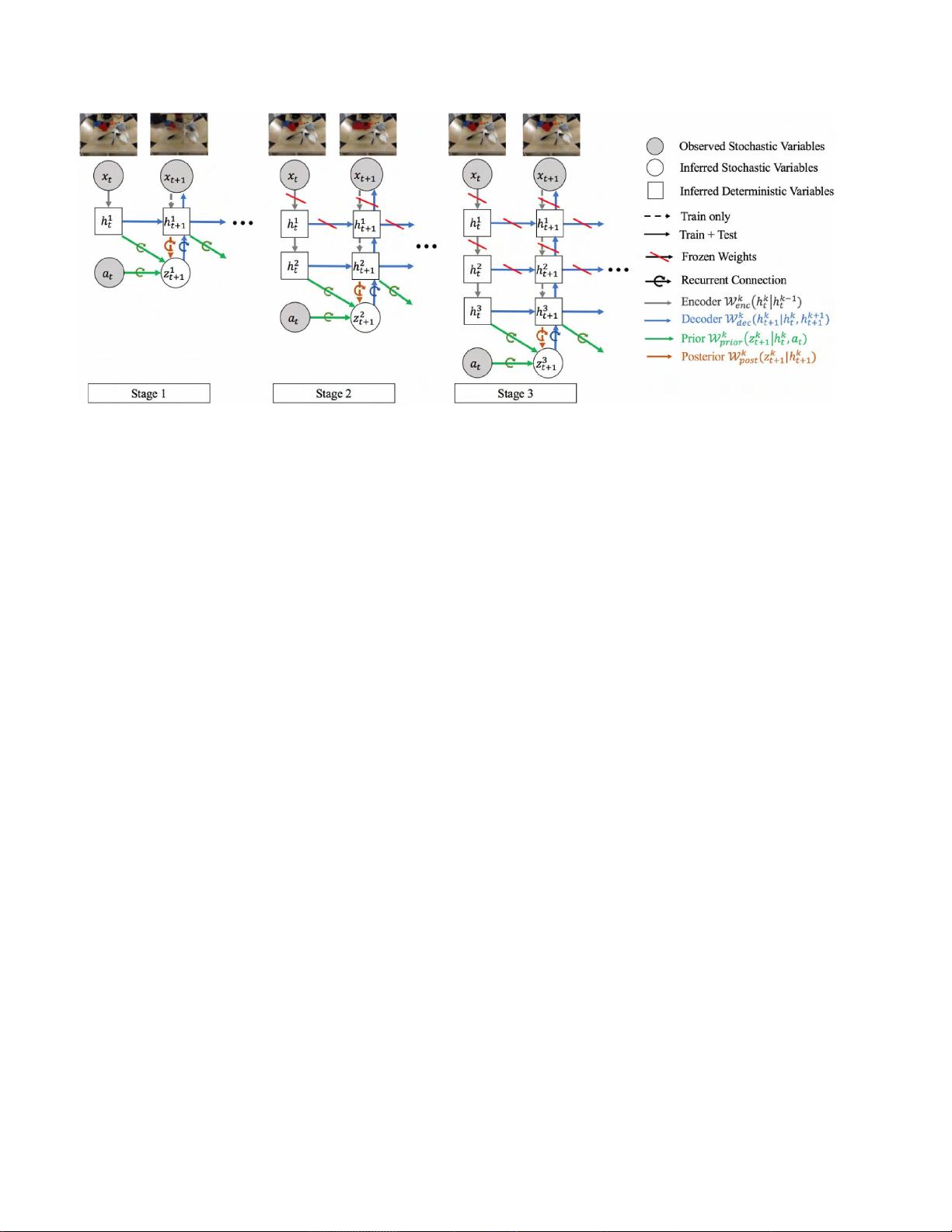
图2:三模块GHVAE的培训程序和架构。
在第一阶段,所有第一模块重量
1
EN
C
1
De
c
1
之前
1
邮政
)进行端到端的培训在第二阶段,来自第一个模块的所有权重都被冻结,第二个模
块的
模块已训练。 在第三阶段,所有第一和第二模块的权重都被冻结,只有第三模块被训练,依此类推
。x t
+1的视频预测质量随着更多模块的添加而提高。图中的图例表示每个GHVAE模块中的四个
组件(编码器、
解码器、先验和后验),以及每个组件是被冻结(倾斜的红色条)还是仅用于训练而不是在测试时使用
(虚线与实线相对)。为了限制需要从先验网络进行预测的空间维度的数量,仅使用最终的第
K
个
GHVAE
模块
中的先验和后验。 动作
a
t
被包括在动作调节视频预测中,而被排除在无动作视频预测中。
贪婪机器学习
贪婪机器学习[61,62,63,64,
65,66]最初被引入为深度网络提供良好的权重
初始化,以在端到端反向传播期间避免糟糕的
局部最优正如最初提出的那样,深度网络的每
个随后,贪婪机器学习已被应用于预训练好的
特征 提取器和 堆叠自动 编码器[67,68,69,
70,71,72],用于下游
视觉,声音和语言的任务[73,74,75]。通过自
监督学习训练,这些特征提取器和自动编码器
在捕获和保存视频等序列数据中的时不变信息
方面表现出色。相比之下,我们提出了一种视
频预测方法,使用层次结构的潜在
变量来显式地
模拟
未来的时变
信息
。最后,提出了生成对抗网
络(GAN)的贪婪训练,以生成高质量,高分
辨率的单图像[76]。与这些先前的工作不同,我
们提出了一种贪婪的方法来训练大规模的视频
预测模型,同时解决了内存限制和分层VAE的
优化挑战。
分层变分自动编码器。
最近引入了分层[77]和顺序
VAE [78],以改善各种环境
视觉任务,如视频预测[11]和图像生成[79]。已
知它们具有优化挑战[10],主要是由于各个潜在
变量之间的双向依赖性。当端到端优化时,分
层VAE需要在整个训练过程中保持每个潜在变
量对视频预测任务有用为此,以前的工作引入
了各种归纳偏差,例如密集连接[11],梯形结构
[80],双向干扰[81],渐进有损压缩[82,83]和频
谱正则化[79],以减轻分层VAE特有的优化困
难。这些方法在图像生成的背景下已经取得了
很大的成功,而我们研究更困难的视频预测问
题。与这些方法不同的是,我们提出了一个贪
婪的训练方案,显着提高了条件分层VAE的优
化挑战。
3.
贪婪分层VAE(GHVAE)
概况
. 为了开发一个有表现力但稳定优化的视频
预测模型,我们引入了贪婪分层VAE(图1)。
2),它们是局部优化的VAE模块,可以顺序地
堆叠在一起 要训练一堆模块,而不需要安装
(
W
,
W
,
W
,
W
剩余11页未读,继续阅读
121 浏览量
659 浏览量
2022-11-29 上传
557 浏览量
166 浏览量
2025-02-24 上传
2021-05-10 上传
2021-05-24 上传
2024-10-02 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 小学水墨风学校网站模板设计
- 深入理解线程池的实现原理与应用
- MSP430编程代码集锦:实用例程源码分享
- 绿色大图幻灯商务响应式企业网站开发源码包
- 深入理解CSS与Web标准的专业解决方案
- Qt/C++集成Google拼音输入法演示Demo
- Apache Hive 0.13.1 版本安装包详解
- 百度地图范围标注技术及应用
- 打造个性化的Windows 8锁屏体验
- Atlantis移动应用开发深度解析
- ASP.NET实验教程:源代码详细解析与实践
- 2012年工业观察杂志完整版
- 全国综合缴费营业厅系统11.5:一站式缴费与运营管理解决方案
- JAVA原生实现HTTP请求的简易指南
- 便携PDF浏览器:随时随地快速查看文档
- VTF格式图片编辑工具:深入起源引擎贴图修改
