THOR-Net:基于Grformer的自监督双手与物体重建技术
PDF格式 | 1.28MB |
更新于2025-01-16
| 109 浏览量 | 举报
"THOR-Net:基于Grformer的自监督实双手和物体重建"
THOR-Net是一种创新的深度学习模型,专为从单个RGB图像中进行真实感的双手和物体重建任务设计。这项技术融合了图卷积网络(GCN)、Transformer架构以及自我监督学习策略,以实现高精度的3D手部姿态和形状重建,同时还能重建与之交互的物体的形状。
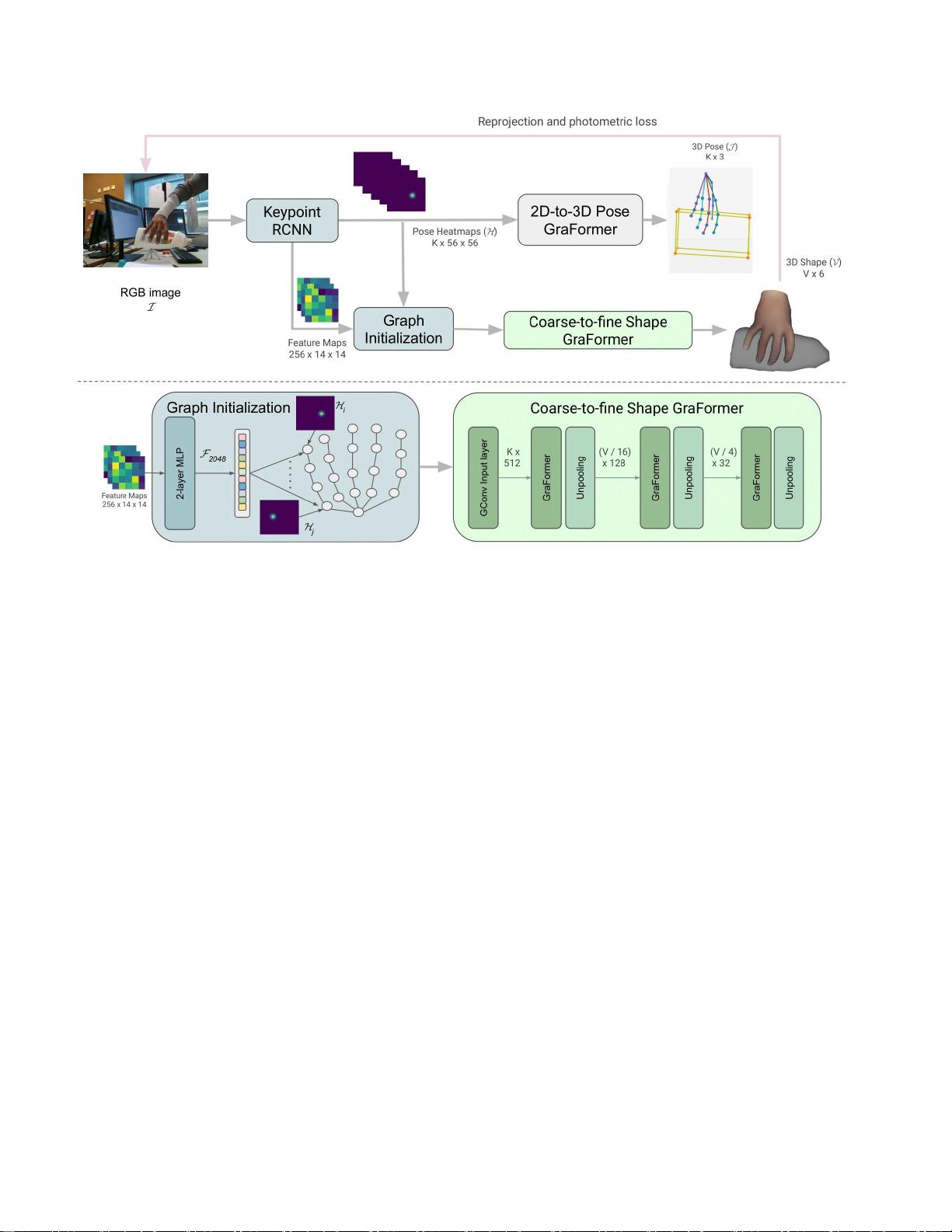
在THOR-Net的体系结构中,首先通过KeypointRCNN从输入的单目RGB图像中提取2D手部关键点、特征图、热图和边界框。这些2D信息随后被转换为图的形式,以便GCN能够利用拓扑结构来捕获手部和物体的复杂相互作用。在重建阶段,THOR-Net包含两个主要分支:形状重建分支和姿态重建分支。
形状重建分支利用GraFormer,这是一个基于Transformer的新型网络,采用自底向上的策略来估计两只手和一个物体的3D网格。GraFormer能够有效地处理非刚性变形和复杂的几何结构,从而提供更精确的形状估计。另一方面,姿态重建分支同样利用GraFormer网络,但专注于恢复手部和物体的3D姿态。
为了进一步提高重建的质量和准确性,THOR-Net引入了一个自我监督的光度损失函数。这个损失函数直接回归每个手部网格顶点的真实感纹理,以确保重建的几何形状与实际观察到的视觉信息一致,从而增强纹理细节。
THOR-Net在HO-3D数据集上实现了手部形状估计的最新最优结果,优于ArtiBoost,平均误差降低至10.0mm。在双手和对象(H2O)数据集上,对于左手姿态估计的误差低于5mm,右手姿态误差小于1mm,表明其在双手中同时处理多个目标的能力。
由于其在手部和物体重建任务中的卓越性能,THOR-Net为AR和VR应用提供了强大的支持,例如个性化虚拟体验、人机交互、动作识别、人类行为分析和手势识别。代码和更多资源可在https://github.com/ATAboukhadra/THOR-Net获取,这为研究者和开发者提供了实现此类高级重建任务的工具。
THOR-Net的贡献在于它解决了现有的挑战,如从单个图像中准确重建手部和物体的三维形态,尤其是在存在复杂交互的情况下。通过集成GCN、Transformer和自我监督学习,该方法开辟了新的可能性,有望推动未来在手部追踪和交互式场景理解领域的进展。
1003
图2.概述了我们的方法,以估计3D姿态和3D形状的手与对象交互从单目RGB帧。K是“姿势”中的关键点数量,V是“形状”中的
顶点数量。下半部分描述了关于图初始化和粗到细形状GraFormer网络的更多细节。
和徒手重建Hasson
等人。
[15]使用了一个网络,该网
络输出手和对象类的MANO [34]参数及其3D变换参
数。他们工作的一个重要方面是,当一些帧没有注释
时,他们使用随着时间推移的光度一致性作为在他们
的后续工作[16]中,Hasson
等人
首先在RGB图像中检
测和分割手和物体。之后,他们估计手形和物体姿
态,并使用平滑和碰撞的损失项对其进行优化。
Malik
等人。
[27,25]研究了根据深度图进行手部姿
势和形状估计。[25,28]使用体素化深度图来估计手
的 体 素 化 形 状 和 形 状 表 面 , 随 后 是 配 准 步 骤 。
EventHands
[35]是一个网络,它使用事件摄像机输入捕捉和重建
前所未有的速度的手部运动。Almadani
等人
[2]创建了
一个基于深度的从粗到细的手部对象重建网络,该网
络构建在GCN HopeNet [9]上。在评估了他们模型的不
同输入方式后,他们发现深度图和相应RGB图像的体
素化表示是最好的输入方式。Pixel2Mesh [38]是一个
GCN网络,它从单目RGB帧中估计物体的3D形状。
3.
方法
所提出的流水线如图
2
所示,它使用
RGB
帧
I
作为
输入,并预测手和对象的目标
3D
姿态
J
和
3D
形状
V
3.1.
关键点RCNN
Mask RCNN [18]是在Faster RCNN [33]上构建的有
效对象检测和语义分割模型。Mask RCNN在包含对象
的图像中提出感兴趣区域(ROI),并估计这些对象
的 边界Mask RCNN 的 作 者 创建了一个 名 为 Keypoint
RCNN的变体,该变体估计ROI内任何2D关键点集合
的位置的热图。对于每个关键点,都有该关键点位置
的热图。通过边界框和热图,Keypoint RCNN可以估
计图像中 构 成 2D 姿势的2D 位置。我 们 训 练关键点
RCNN来估计手和物体的2D姿势,知道3D姿势到2D的
投影。因此,Keypoint RCNN提供了来自RGB图像的
重要信息,例如手和对象的边界框
要训练Keypoint RCNN,需要边界框为了获得边界
框,我们使用2D
剩余10页未读,继续阅读
相关推荐


cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebDrive v16.00.4368: 简易易用的Windows风格FTP工具
- FirexKit:Python的FireX库组件
- Labview登录界面设计与主界面跳转实现指南
- ASP.NET JS引用管理器:解决重复问题
- HTML5 canvas绘图技术源代码下载
- 昆仑通态嵌入版ASD操舵仪软件应用解析
- JavaScript实现最小公倍数和最大公约数算法
- C++中实现XML操作类的方法与应用
- 设计编程工具集:材料重量快速计算指南
- Fancybox:Jquery图片轮播幻灯弹窗插件推荐
- Splunk Fitbit:全方位分析您的活动与睡眠数据
- Emoji表情编码资源及数据库查询实现
- JavaScript实现图片编辑:截取、旋转、缩放功能详解
- QNMS系统架构与应用实践
- 微软高薪面试题解析:通向世界500强的挑战
- 绿色全屏大气园林设计企业整站源码与多技术项目资源
