如何将html转换为word
时间: 2024-05-21 22:16:14 浏览: 148
你可以使用Microsoft Word中的“另存为”功能将HTML文件转换为Word文档。具体操作步骤如下:
1. 打开Microsoft Word软件。
2. 在菜单栏中选择“文件”选项,然后选择“打开”。
3. 选择您要转换的HTML文件,然后点击“打开”。
4. 在Word中查看HTML文件,并进行必要的编辑。
5. 在菜单栏中选择“文件”选项,然后选择“另存为”。
6. 在“文件类型”下拉菜单中选择“Word文档(.docx)”或“Word 97-2003文档(.doc)”。
7. 选择您要保存的位置和文件名,然后点击“保存”。
8. Word将自动将HTML文件转换为Word文档格式。
相关问题
使用python将html转换为word示例代码
### 回答1:
以下是使用 python 将 HTML 转换为 Word 的示例代码:
```
import requests
from bs4 import BeautifulSoup
import docx
# 获取 HTML 页面内容
url = 'https://www.example.com'
response = requests.get(url)
html_content = response.text
# 使用 BeautifulSoup 解析 HTML 内容
soup = BeautifulSoup(html_content, 'html.parser')
# 创建 Word 文档
doc = docx.Document()
# 遍历 HTML 中的所有段落
for p in soup.find_all('p'):
# 将每个段落的内容添加到 Word 文档中
doc.add_paragraph(p.text)
# 保存 Word 文档
doc.save('example.docx')
```
请注意,上面的代码仅仅是一个简单的示例,实际应用中可能需要根据实际需求进行修改和优化。
### 回答2:
使用Python将HTML转换为Word可以使用python-docx库来实现。示例代码如下:
```python
from docx import Document
from bs4 import BeautifulSoup
def html_to_word(html_file, output_file):
# 打开HTML文件并读取内容
with open(html_file, 'r', encoding='utf-8') as f:
html_content = f.read()
# 创建一个新的Word文档
doc = Document()
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(html_content, 'html.parser')
# 查找所有的段落标签
paragraphs = soup.find_all('p')
# 遍历每个段落,并将内容添加到Word文档中
for p in paragraphs:
doc.add_paragraph(p.get_text())
# 保存Word文档
doc.save(output_file)
if __name__ == '__main__':
html_file = 'input.html'
output_file = 'output.docx'
html_to_word(html_file, output_file)
```
以上代码中,通过使用python-docx库创建一个新的Word文档`doc`,然后使用BeautifulSoup库解析HTML内容,并使用`find_all`方法找到所有的段落标签,最后将每个段落的文本内容添加到Word文档中。最后,使用`save`方法保存Word文档到指定的输出文件路径。
### 回答3:
使用Python将HTML转换为Word示例代码可以使用python-docx库来实现。以下是一个简单的示例代码:
```python
from bs4 import BeautifulSoup
from docx import Document
def convert_html_to_word(html_file, docx_file):
# 打开HTML文件并解析
with open(html_file, 'r', encoding='utf-8') as file:
html_content = file.read()
soup = BeautifulSoup(html_content, 'html.parser')
# 创建Word文档对象
doc = Document()
# 循环处理HTML标签
for tag in soup.recursiveChildGenerator():
# 处理文本内容
if hasattr(tag, 'name') and tag.name in ['p', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6', 'li', 'div']:
text = tag.get_text().strip()
if text:
if tag.name.startswith('h'):
doc.add_heading(text, level=int(tag.name[1:]))
elif tag.name == 'li':
doc.add_paragraph(text, style='List Bullet')
else:
doc.add_paragraph(text)
# 保存为Word文档
doc.save(docx_file)
# 调用示例
convert_html_to_word('example.html', 'example.docx')
```
以上示例代码通过使用BeautifulSoup解析HTML文件,并通过docx库创建Word文档对象。然后根据HTML标签的不同,逐行处理并添加相应的内容到Word文档中。最后将转换后的Word文档保存为`.docx`文件。
请注意,此示例代码仅演示了基本的功能,实际应用中可能需要根据HTML的具体结构和样式进行更复杂的处理,以及可能存在一些特殊标签和样式的转换问题。
用python将html转换为word,并将标题作为文件名
### 回答1:
使用 Python 将 HTML 转换为 Word 文档并将标题作为文件名,可以使用 python-docx 库。首先,安装 python-docx 库:
```
pip install python-docx
```
然后,使用下面的代码把 HTML 转换为 Word 文档:
```python
import requests
from bs4 import BeautifulSoup
import docx
def html_to_word(html_str, title):
# 解析 HTML 字符串
soup = BeautifulSoup(html_str, 'html.parser')
# 创建一个 Word 文档
doc = docx.Document()
# 遍历 HTML 文档中的所有元素
for element in soup.body.descendants:
# 如果是标题
if element.name in ['h1', 'h2', 'h3', 'h4', 'h5', 'h6']:
# 添加标题
doc.add_heading(element.text, level=int(element.name[1]))
# 如果是段落
elif element.name == 'p':
# 添加段落
doc.add_paragraph(element.text)
# 保存 Word 文档
doc.save(title + '.docx')
```
以上代码会创建一个 Word 文档,并把 HTML 中的标题和段落添加到文档中,最后使用标题作为文件名保存 Word 文档。
### 回答2:
使用Python将HTML转换为Word可以使用python-docx库。首先,我们需要安装该库,在命令行中输入以下命令:
```
pip install python-docx
```
安装完成后,我们可以编写Python代码来实现将HTML转换为Word的功能:
```python
from docx import Document
from bs4 import BeautifulSoup
def html_to_word(html_file):
# 读取HTML文件
with open(html_file, 'r', encoding='utf-8') as f:
html_content = f.read()
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 提取标题作为文件名
title = soup.title.string
# 创建Word文档
doc = Document()
# 将HTML内容转换为Word
doc.add_paragraph(str(soup))
# 保存为Word文件
doc.save(title + '.docx')
# 使用示例
html_to_word('sample.html')
```
在上述代码中,我们首先使用BeautifulSoup库解析HTML文件,然后提取标题作为文件名。接下来,我们创建一个空的Word文档,并将HTML内容转换后添加到文档中。最后,使用标题加上扩展名 `.docx` 作为文件名保存Word文档。
当然,这只是一个简单的示例,如果HTML文件中包含更复杂的内容,可能需要进一步处理,考虑样式、图像或其他元素的转换。具体转换方式可以根据HTML文件的结构和需求进行定制。
### 回答3:
使用Python进行HTML到Word的转换可以使用python-docx库来实现。下面是一个简单的示例代码,将HTML文件转换成Word,使用标题作为文件名:
```python
from bs4 import BeautifulSoup
from docx import Document
def html_to_word(html_filename):
# 打开HTML文件并读取内容
with open(html_filename, 'r', encoding='utf-8') as file:
html_content = file.read()
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(html_content, 'html.parser')
# 获取标题作为文件名
title = soup.title.text.strip()
# 创建一个新的Word文档对象
doc = Document()
# 获取HTML内容中的所有段落
paragraphs = soup.find_all('p')
# 将每个段落添加到Word文档中
for p in paragraphs:
doc.add_paragraph(p.text)
# 保存Word文档,文件名使用标题
doc.save(title + '.docx')
# 调用函数,传入HTML文件名
html_to_word('example.html')
```
以上代码使用了`bs4`库来解析HTML内容,将所有的`<p>`标签中的文本添加到Word文档中。最终,保存的Word文档的文件名将会是HTML文件中的标题。
请注意,要运行此代码,你需要安装所需的库。可以通过运行`pip install beautifulsoup4 python-docx`来安装`bs4`和`python-docx`库。
相关推荐
最新推荐
Java实现将word转换为html的方法示例【doc与docx格式】
Java实现将word转换为html的方法示例【doc与docx格式】 Java语言中实现将word文档转换为html格式的方法示例,结合实例形式分析了java针对doc与docx格式文件的相关转换操作技巧。 知识点1:Java中word文档的读取 ...
java使用POI实现html和word相互转换
这意味着,我们将学习如何使用 Java 语言编写程序来将 HTML 文件转换为 Word 文件,反之亦然。 描述解读 主要为大家详细介绍了 Java 使用 POI 实现 HTML 和 Word 的相互转换,具有一定的参考价值,感兴趣的小伙伴们...
可以将word转成html的js代码
在IT领域,转换文档格式是常见的需求之一,例如将Microsoft Word文档转换为HTML网页。这个过程可以通过编程语言实现,比如JavaScript。在提供的标题和描述中,我们看到一个使用JavaScript(js)来转换Word文档(doc...
word转html带目录结构的实现方式.docx
1. **将Word转换为HTML** - 有两种常见的方法:使用Word自带的API(如Jacob库)或者使用Apache POI库。Jacob是Java与COM接口的桥梁,可以直接调用Word的API来转换,而POI则是专门用于处理Office文档的Java库。根据...
pdf转word、html等目前是转换最好的软件了,软件名叫:AdobeAcrobatDC
Adobe Acrobat DC是一款由Adobe公司开发的专业PDF处理软件,它提供了丰富的PDF转换功能,包括将PDF文档转换为Word、HTML等多种格式。这款软件以其强大的转换准确度和用户友好的界面而备受推崇,尤其适合需要在不同...
最优条件下三次B样条小波边缘检测算子研究
"这篇文档是关于B样条小波在边缘检测中的应用,特别是基于最优条件的三次B样条小波多尺度边缘检测算子的介绍。文档涉及到图像处理、计算机视觉、小波分析和优化理论等多个IT领域的知识点。"
在图像处理中,边缘检测是一项至关重要的任务,因为它能提取出图像的主要特征。Canny算子是一种经典且广泛使用的边缘检测算法,但它并未考虑最优滤波器的概念。本文档提出了一个新的方法,即基于三次B样条小波的边缘提取算子,该算子通过构建目标函数来寻找最优滤波器系数,从而实现更精确的边缘检测。
小波分析是一种强大的数学工具,它能够同时在时域和频域中分析信号,被誉为数学中的"显微镜"。B样条小波是小波家族中的一种,尤其适合于图像处理和信号分析,因为它们具有良好的局部化性质和连续性。三次B样条小波在边缘检测中表现出色,其一阶导数可以用来检测小波变换的局部极大值,这些极大值往往对应于图像的边缘。
文档中提到了Canny算子的三个最优边缘检测准则,包括低虚假响应率、高边缘检测概率以及单像素宽的边缘。作者在此基础上构建了一个目标函数,该函数考虑了这些准则,以找到一组最优的滤波器系数。这些系数与三次B样条函数构成的线性组合形成最优边缘检测算子,能够在不同尺度上有效地检测图像边缘。
实验结果表明,基于最优条件的三次B样条小波边缘检测算子在性能上优于传统的Canny算子,这意味着它可能提供更准确、更稳定的边缘检测结果,这对于计算机视觉、图像分析以及其他依赖边缘信息的领域有着显著的优势。
此外,文档还提到了小波变换的定义,包括尺度函数和小波函数的概念,以及它们如何通过伸缩和平移操作来适应不同的分析需求。稳定性条件和重构小波的概念也得到了讨论,这些都是理解小波分析基础的重要组成部分。
这篇文档深入探讨了如何利用优化理论和三次B样条小波改进边缘检测技术,对于从事图像处理、信号分析和相关研究的IT专业人士来说,是一份极具价值的学习资料。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
递归阶乘速成:从基础到高级的9个优化策略
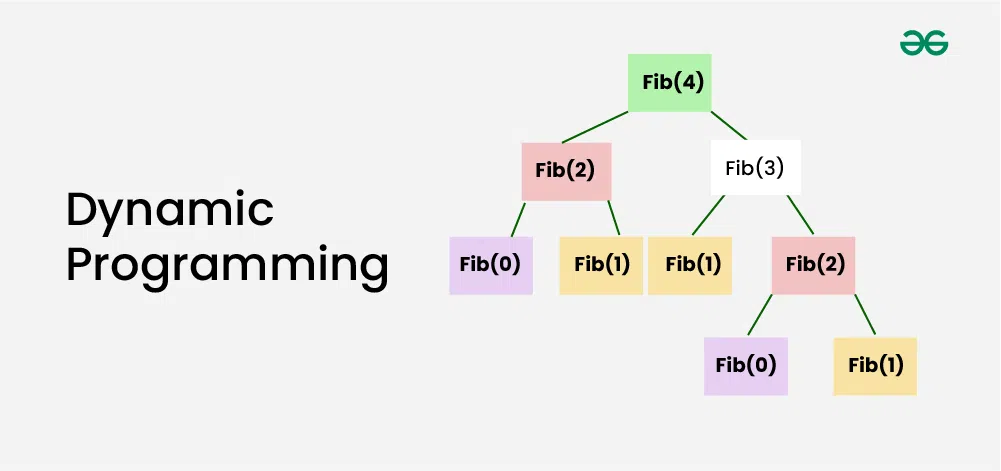
# 1. 递归阶乘算法的基本概念
在计算机科学中,递归是一种常见的编程技巧,用于解决可以分解为相似子问题的问题。阶乘函数是递归应用中的一个典型示例,它计算一个非负整数的阶乘,即该数以下所有正整数的乘积。阶乘通常用符号"!"表示,例如5的阶乘写作5! = 5 * 4 * 3 * 2 * 1。通过递归,我们可以将较大数的阶乘计算简化为更小数的阶乘计算,直到达到基本情况
pcl库在CMakeLists。txt配置
PCL (Point Cloud Library) 是一个用于处理点云数据的开源计算机视觉库,常用于机器人、三维重建等应用。在 CMakeLists.txt 文件中配置 PCL 需要以下步骤:
1. **添加找到包依赖**:
在 CMakeLists.txt 的顶部,你需要找到并包含 PCL 的 CMake 找包模块。例如:
```cmake
find_package(PCL REQUIRED)
```
2. **指定链接目标**:
如果你打算在你的项目中使用 PCL,你需要告诉 CMake 你需要哪些特定组件。例如,如果你需要 PointCloud 和 vi
深入解析:wav文件格式结构
"该文主要深入解析了wav文件格式,详细介绍了其基于RIFF标准的结构以及包含的Chunk组成。"
在多媒体领域,WAV文件格式是一种广泛使用的未压缩音频文件格式,它的基础是Resource Interchange File Format (RIFF) 标准。RIFF是一种块(Chunk)结构的数据存储格式,通过将数据分为不同的部分来组织文件内容。每个WAV文件由几个关键的Chunk组成,这些Chunk共同定义了音频数据的特性。
1. RIFFWAVE Chunk
RIFFWAVE Chunk是文件的起始部分,其前四个字节标识为"RIFF",紧接着的四个字节表示整个Chunk(不包括"RIFF"和Size字段)的大小。接着是'RiffType',在这个情况下是"WAVE",表明这是一个WAV文件。这个Chunk的作用是确认文件的整体类型。
2. Format Chunk
Format Chunk标识为"fmt",是WAV文件中至关重要的部分,因为它包含了音频数据的格式信息。例如,采样率、位深度、通道数等都在这个Chunk中定义。这些参数决定了音频的质量和大小。Format Chunk通常包括以下子字段:
- Audio Format:2字节,表示音频编码格式,如PCM(无损)或压缩格式。
- Num Channels:2字节,表示音频的声道数,如单声道(1)或立体声(2)。
- Sample Rate:4字节,表示每秒的样本数,如44100 Hz。
- Byte Rate:4字节,每秒音频数据的字节数,等于Sample Rate乘以Bits Per Sample和Num Channels。
- Block Align:2字节,每个样本数据的字节数,等于Bits Per Sample除以8乘以Num Channels。
- Bits Per Sample:2字节,每个样本的位深度,影响声音质量和文件大小。
3. Fact Chunk(可选)
Fact Chunk标识为'fact',虽然不是所有WAV文件都包含此Chunk,但它提供了额外的样本信息,如实际的样本数,对于非整数倍采样率的文件尤其有用。
4. Data Chunk
Data Chunk标识为'data',是WAV文件中真正包含音频样本数据的部分。其ID后面是4字节的Size字段,表示数据区域的大小,不包括ID和Size本身。这个Chunk的内容就是连续的音频样本值,根据Format Chunk定义的格式进行编码。
所有Chunk的大小字段都是以低字节在前,高字节在后的顺序存储,这是遵循了RIFF格式的规定。理解这些Chunk的结构和内容对于处理和分析WAV文件至关重要,无论是编程处理音频数据还是进行音频文件的转换和编辑。