jupyter离散化案例
时间: 2024-09-13 07:02:02 浏览: 59
离散化是数据预处理中的一种技术,其目的是将连续的特征数据转换为离散的特征表示,这样可以降低计算复杂性,并有助于算法更好地捕捉数据中的模式。在Python中,我们可以使用Jupyter Notebook来展示离散化的案例,这里我们以Pandas和Scikit-learn库来展示一个简单的例子。
首先,我们需要安装必要的库(如果尚未安装):
```python
# 如果还未安装,可以使用pip来安装必要的库
# pip install numpy pandas scikit-learn matplotlib
```
然后,我们可以使用以下代码来演示离散化的过程:
```python
import numpy as np
import pandas as pd
from sklearn.preprocessing import KBinsDiscretizer
import matplotlib.pyplot as plt
# 创建一个简单的数据集
data = np.random.randn(100)
df = pd.DataFrame(data, columns=['feature'])
# 使用KBinsDiscretizer进行离散化,将数据分为5个区间
est = KBinsDiscretizer(n_bins=5, encode='ordinal', strategy='uniform')
df['feature_discretized'] = est.fit_transform(df[['feature']])
# 展示离散化后的数据
print(df.head())
# 绘制原始数据和离散化后的数据的分布图
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.hist(df['feature'], bins=10, edgecolor='black')
plt.title('原始特征分布')
plt.subplot(1, 2, 2)
plt.hist(df['feature_discretized'], bins=5, edgecolor='black')
plt.title('离散化特征分布')
plt.show()
```
在这个案例中,我们首先创建了一个包含100个随机数的简单数据集。然后,我们使用`KBinsDiscretizer`类将这些连续值数据分为5个区间。最后,我们通过直方图比较了原始数据和离散化后数据的分布情况。
阅读全文
相关推荐
最新推荐
利用Python将数值型特征进行离散化操作的方法
在数据分析和机器学习中,离散化是一种将连续数值型数据转换为离散或分类数据的过程,这有助于简化数据、减少噪声以及提高模型的解释性。Python提供了多种方法来实现这个过程,本篇文章将深入探讨如何利用Python进行...
离散数学手写笔记.pdf
7. **初步的数理逻辑**:可能包含形式系统、公理化方法、 Gödel不完备定理等内容,这些都是计算机科学理论的基础。 这些内容的深入理解和掌握对于理解计算机科学中的算法设计、数据结构、计算复杂性等高级主题至关...
基于java的化妆品配方及工艺管理系统的开题报告.docx
基于java的化妆品配方及工艺管理系统的开题报告.docx
Angular实现MarcHayek简历展示应用教程
资源摘要信息:"MarcHayek-CV:我的简历的Angular应用"
Angular 应用是一个基于Angular框架开发的前端应用程序。Angular是一个由谷歌(Google)维护和开发的开源前端框架,它使用TypeScript作为主要编程语言,并且是单页面应用程序(SPA)的优秀解决方案。该应用不仅展示了Marc Hayek的个人简历,而且还介绍了如何在本地环境中设置和配置该Angular项目。
知识点详细说明:
1. Angular 应用程序设置:
- Angular 应用程序通常依赖于Node.js运行环境,因此首先需要全局安装Node.js包管理器npm。
- 在本案例中,通过npm安装了两个开发工具:bower和gulp。bower是一个前端包管理器,用于管理项目依赖,而gulp则是一个自动化构建工具,用于处理如压缩、编译、单元测试等任务。
2. 本地环境安装步骤:
- 安装命令`npm install -g bower`和`npm install --global gulp`用来全局安装这两个工具。
- 使用git命令克隆远程仓库到本地服务器。支持使用SSH方式(`***:marc-hayek/MarcHayek-CV.git`)和HTTPS方式(需要替换为具体用户名,如`git clone ***`)。
3. 配置流程:
- 在server文件夹中的config.json文件里,需要添加用户的电子邮件和密码,以便该应用能够通过内置的联系功能发送信息给Marc Hayek。
- 如果想要在本地服务器上运行该应用程序,则需要根据不同的环境配置(开发环境或生产环境)修改config.json文件中的“baseURL”选项。具体而言,开发环境下通常设置为“../build”,生产环境下设置为“../bin”。
4. 使用的技术栈:
- JavaScript:虽然没有直接提到,但是由于Angular框架主要是用JavaScript来编写的,因此这是必须理解的核心技术之一。
- TypeScript:Angular使用TypeScript作为开发语言,它是JavaScript的一个超集,添加了静态类型检查等功能。
- Node.js和npm:用于运行JavaScript代码以及管理JavaScript项目的依赖。
- Git:版本控制系统,用于代码的版本管理及协作开发。
5. 关于项目结构:
- 该应用的项目文件夹结构可能遵循Angular CLI的典型结构,包含了如下目录:app(存放应用组件)、assets(存放静态资源如图片、样式表等)、environments(存放环境配置文件)、server(存放服务器配置文件如上文的config.json)等。
6. 开发和构建流程:
- 开发时,可能会使用Angular CLI来快速生成组件、服务等,并利用热重载等特性进行实时开发。
- 构建应用时,通过gulp等构建工具可以进行代码压缩、ES6转译、单元测试等自动化任务,以确保代码的质量和性能优化。
7. 部署:
- 项目最终需要部署到服务器上,配置文件中的“baseURL”选项指明了服务器上的资源基础路径。
8. 关于Git仓库:
- 压缩包子文件的名称为MarcHayek-CV-master,表明这是一个使用Git版本控制的仓库,且存在一个名为master的分支,这通常是项目的主分支。
以上知识点围绕Angular应用“MarcHayek-CV:我的简历”的创建、配置、开发、构建及部署流程进行了详细说明,涉及了前端开发中常见的工具、技术及工作流。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
深入剖析:内存溢出背后的原因、预防及应急策略(专家版)
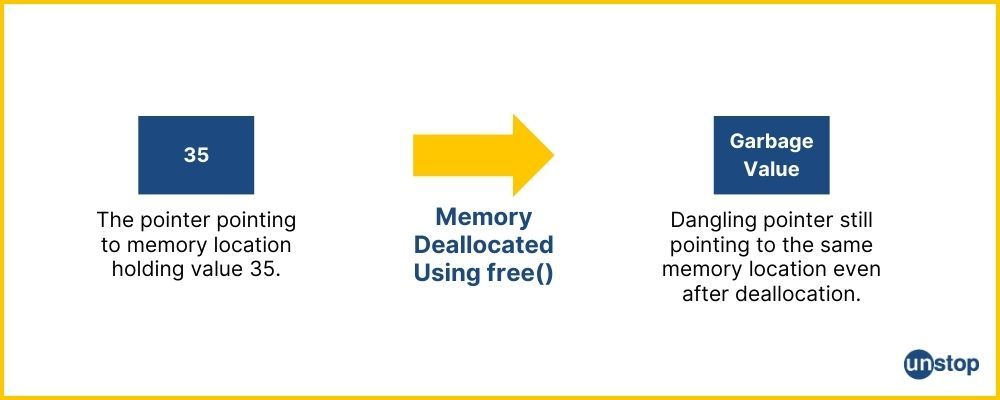
参考资源链接:[Net 内存溢出(System.OutOfMemoryException)的常见情况和处理方式总结](https://wenku.csdn.net/doc/6412b784be7fbd1778d4a95f?spm=1055.2635.3001.10343)
# 1. 内存溢出的概念及影响
内存溢出,又称
Java中如何对年月日时分秒的日期字符串作如下处理:如何日期分钟介于两个相连的半点之间,就将分钟数调整为前半点
在Java中,你可以使用`java.time`包中的类来处理日期和时间,包括格式化和调整。下面是一个示例,展示了如何根据给定的日期字符串(假设格式为"yyyy-MM-dd HH:mm:ss")进行这样的处理:
```java
import java.text.SimpleDateFormat;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.ZonedDateTime;
public class Main {
public static void main(String[] args
Crossbow Spot最新更新 - 获取Chrome扩展新闻
资源摘要信息:"Crossbow Spot - Latest News Update-crx插件"
该信息是关于一款特定的Google Chrome浏览器扩展程序,名为"Crossbow Spot - Latest News Update"。此插件的目的是帮助用户第一时间获取最新的Crossbow Spot相关信息,它作为一个RSS阅读器,自动聚合并展示Crossbow Spot的最新新闻内容。
从描述中可以提取以下关键知识点:
1. 功能概述:
- 扩展程序能让用户领先一步了解Crossbow Spot的最新消息,提供实时更新。
- 它支持自动更新功能,用户不必手动点击即可刷新获取最新资讯。
- 用户界面设计灵活,具有美观的新闻小部件,使得信息的展现既实用又吸引人。
2. 用户体验:
- 桌面通知功能,通过Chrome的新通知中心托盘进行实时推送,确保用户不会错过任何重要新闻。
- 提供一个便捷的方式来保持与Crossbow Spot最新动态的同步。
3. 语言支持:
- 该插件目前仅支持英语,但开发者已经计划在未来的版本中添加对其他语言的支持。
4. 技术实现:
- 此扩展程序是基于RSS Feed实现的,即从Crossbow Spot的RSS源中提取最新新闻。
- 扩展程序利用了Chrome的通知API,以及RSS Feed处理机制来实现新闻的即时推送和展示。
5. 版权与免责声明:
- 所有的新闻内容都是通过RSS Feed聚合而来,扩展程序本身不提供原创内容。
- 用户在使用插件时应遵守相关的版权和隐私政策。
6. 安装与使用:
- 用户需要从Chrome网上应用店下载.crx格式的插件文件,即Crossbow_Spot_-_Latest_News_Update.crx。
- 安装后,插件会自动运行,并且用户可以对其进行配置以满足个人偏好。
从以上信息可以看出,该扩展程序为那些对Crossbow Spot感兴趣或需要密切跟进其更新的用户提供了一个便捷的解决方案,通过集成RSS源和Chrome通知机制,使得信息获取变得更加高效和及时。这对于需要实时更新信息的用户而言,具有一定的实用价值。同时,插件的未来发展计划中包括了多语言支持,这将使得更多的用户能够使用并从中受益。
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
【Java内存管理终极指南】:一次性解决内存溢出、泄漏和性能瓶颈
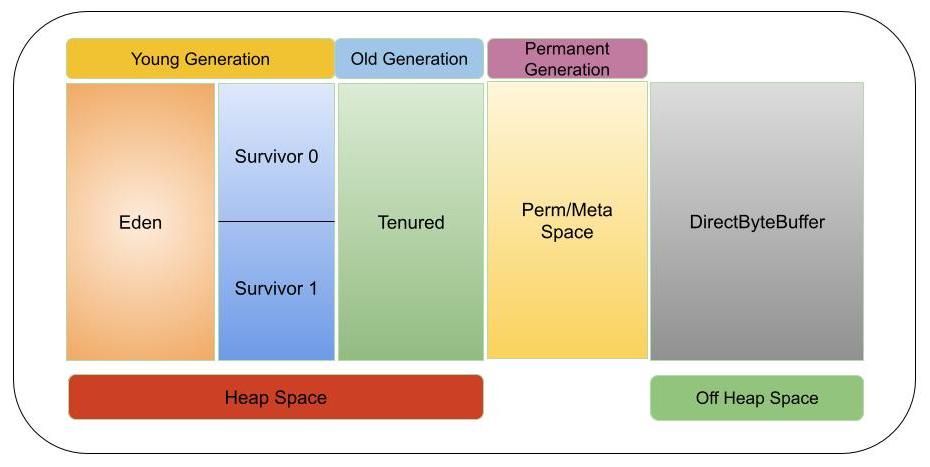
参考资源链接:[Net 内存溢出(System.OutOfMemoryException)的常见情况和处理方式总结](https://wenku.csdn.net/doc/6412b784be7fbd1778d4a95f?spm=1055.2635.3001.10343)
# 1. Java内存模型