【机器学习项目实战】:用Jupyter构建Python模型的完整教程
发布时间: 2024-10-06 03:01:04 阅读量: 62 订阅数: 22 

机器学习练习-jupyter

# 1. 机器学习和Python简介
在当今的IT领域,机器学习和Python是两个无比热门的话题。机器学习作为人工智能的一个分支,正被广泛应用于各种场景中,从简单的推荐系统到复杂的预测分析。Python,以其简洁的语法和强大的功能库,已成为数据科学和机器学习领域的首选编程语言。本章将从机器学习的基本概念讲起,过渡到Python的简介,为读者提供一个全面的入门指南。
## 1.1 机器学习简介
机器学习是使计算机能够从数据中学习并根据数据做出决策的技术。它允许系统在没有明确编程的情况下进行预测或决策。按照学习方式的不同,机器学习可分为监督学习、无监督学习、半监督学习和强化学习等类型。
## 1.2 Python简介
Python是一种高级编程语言,以其简洁易读的语法和强大的功能库而闻名。在机器学习领域,Python有许多强大的库,如NumPy、Pandas、Matplotlib和scikit-learn,这些都极大地简化了数据分析和机器学习模型的构建过程。
通过对本章的学习,您将掌握机器学习的基础知识,了解Python在这一领域的应用,并为进一步深入学习打下坚实的基础。接下来,我们将详细介绍如何利用Python进行机器学习的实际操作。
# 2. Jupyter Notebook的基础使用
Jupyter Notebook 是一种开源的Web应用程序,允许用户创建和共享包含实时代码、方程、可视化和文本的文档。它支持多种编程语言,其中最常用的是 Python。Jupyter Notebook 适用于数据分析、机器学习、科学计算等领域的开发工作,使得数据探索和实验变得更加直观和可交互。
## 2.1 Jupyter Notebook的安装和配置
### 2.1.1 安装Jupyter Notebook
在安装 Jupyter Notebook 之前,确保你的环境中已经安装了 Python。推荐使用 Anaconda 发行版,因为它预装了大量的科学计算库,包括 Jupyter Notebook。
如果你还没有安装 Anaconda,可以从 [Anaconda 官网](*** 下载并安装。安装完成后,打开命令行工具,并输入以下命令来安装 Jupyter Notebook:
```bash
conda install jupyter notebook
```
如果你选择不使用 Anaconda,也可以使用 pip 安装 Jupyter Notebook:
```bash
pip install notebook
```
安装完成后,你可以通过在命令行输入 `jupyter notebook` 来启动 Jupyter Notebook 服务。
### 2.1.2 Jupyter Notebook的配置和优化
为了使 ***r Notebook 的使用更加高效,我们可以对其进行一些配置。
首先,通过 `jupyter notebook --generate-config` 命令生成配置文件 `jupyter_notebook_config.py`。然后,编辑该文件来设置一些基本的配置项。例如,设置访问密码:
```python
c.NotebookApp.password = 'sha1:xxx...' # 生成密码哈希,例如使用 jupyter notebook password 命令
```
还可以通过配置来指定 Jupyter Notebook 的工作目录:
```python
c.NotebookApp.notebook_dir = '/path/to/your/directory'
```
此外,安装一些插件来增强 Jupyter Notebook 的功能也是很有用的。例如,可以安装 `nb_conda` 来帮助管理和切换不同版本的 Conda 环境,以及 `jupyterthemes` 来改变界面主题:
```bash
conda install -c conda-forge nb_conda
pip install jupyterthemes
jt -t onedork
```
## 2.2 Jupyter Notebook的操作和功能
### 2.2.1 基本操作介绍
当 Jupyter Notebook 启动后,浏览器会自动打开一个新标签页,显示文件浏览器界面。你可以创建新的 Notebook 或者打开现有的 Notebook。
在 Notebook 中,你可以使用单元格来组织代码。单元格可以是代码单元格,也可以是 Markdown 文本单元格。代码单元格可以直接运行 Python 代码,并且结果会在单元格下方显示。
运行单元格的基本操作包括:
- 选中单元格后,使用快捷键 Shift+Enter 运行单元格。
- 使用快捷键 Alt+Enter 可以运行单元格,并在下方插入一个新单元格。
### 2.2.2 功能拓展和插件使用
Jupyter Notebook 的功能可以通过安装扩展插件来增强。一种流行的方式是通过 `jupyter_contrib_nbextensions` 包来安装社区贡献的扩展。
安装该扩展前,你需要安装 `nbextensions`:
```bash
pip install jupyter_contrib_nbextensions
jupyter contrib nbextension install --user
```
安装后,你可以在 Jupyter Notebook 的 "Nbextensions" 标签页中启用或禁用各个扩展。例如,你可以启用 "Collapsible headings" 来创建可折叠的标题单元格,或者 "ExecuteTime" 来显示代码单元格的执行时间。
请注意,启用某些扩展可能需要重启 Jupyter Notebook 服务。
通过这些基本操作和功能拓展,你可以更加高效地使用 Jupyter Notebook 进行数据科学工作。这些工具将为你的数据探索和模型构建提供强大的支持。
```mermaid
flowchart LR
A[启动Jupyter Notebook] --> B[访问文件浏览器]
B --> C{选择操作}
C -->|创建Notebook| D[新建Python文件]
C -->|打开Notebook| E[选择现有文件]
D --> F[编写代码或文本]
E --> F
F --> G[运行单元格]
G --> H[查看结果]
H --> I[使用插件增强功能]
I --> J[进行数据分析或机器学习]
```
以上是本章节的概览,接下来我们将深入到 Jupyter Notebook 更加具体的使用方法,包括代码块的编写、Markdown文本的编辑以及丰富的交互操作。随着本章节内容的展开,你将能够熟练掌握 Jupyter Notebook 的核心功能,为数据科学工作打下坚实的基础。
# 3. 数据处理和分析基础
在数据科学的世界中,数据处理和分析是构建任何模型或进行深入研究的基石。没有精确和高质量的数据,再强大的算法也无法提供有效的结果。本章将引导读者了解数据预处理和分析的基础知识,并通过实际案例加深理解。
## 3.1 数据预处理
### 3.1.1 数据清洗
数据清洗是数据预处理中最关键的步骤之一。它涉及识别并修正或删除数据集中的不一致和错误。例如,数据集中可能会有缺失值、重复记录、格式不一致等问题。
一个常见的数据清洗任务是处理缺失值。在Python中,Pandas库提供了一系列方法来处理这些情况。例如,我们可以使用简单的策略填充缺失值,如使用列的平均值或中位数。
```python
import pandas as pd
# 假设有一个DataFrame df,其中包含缺失值
df = pd.DataFrame({
'A': [1, 2, None, 4],
'B': [None, 2, 3, 4],
'C': [1, 2, 3, None]
})
# 使用列的平均值填充缺失值
df_filled = df.fillna(df.mean())
# 使用前一个值填充缺失值
df_filled = df.fillna(method='ffill')
```
在上述代码中,`fillna`方法用于填充DataFrame中的缺失值。参数`df.mean()`计算每列的平均值,并使用这些值填充相应的缺失值。`method='ffill'`选项将使用前一个非缺失值填充后续的缺失值。
### 3.1.2 数据格式转换
数据格式转换通常涉及将数据从一种格式转换为另一种格式,以便于后续处理。例如,我们可能需要将数据从宽格式转换为长格式,或者进行数据类型转换。
```python
# 将数据从宽格式转换为长格式
df_long = pd.melt(df, var_name='Variable', value_name='Value')
# 转换数据类型
df['A'] = df['A'].astype('int32')
```
使用Pandas的`melt`函数,我们可以将宽格式的DataFrame转换为长格式,其中`var_name`和`value_name`参数分别定义了新的列名。`astype`方法用于将列`A`的数据类型转换为`int32`。
## 3.2 数据分析技巧
### 3.2.1 常用数据分析库介绍
在Python中,有多个库在数据分析中发挥着关键作用。Pandas用于数据结构和操作,NumPy用于高效的数值计算,Matplotlib和Seaborn用于数据可视化。
```python
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 使用NumPy创建一个数组
array = np.array([1, 2, 3, 4, 5])
# 使用Matplotlib绘制简单图表
plt.plot(array)
plt.title('Simple Line Chart')
plt.show()
# 使用Seaborn绘制散点图
sns.scatterplot(x='A', y='B', data=df)
plt.title('Scatter Plot')
plt.show()
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python库文件学习之Jupyter》专栏深入探索了Jupyter笔记本的方方面面,为Python开发者提供了全面的指南。从搭建编程环境到构建交互式数据报告,再到调试、数据可视化和版本控制,专栏涵盖了各种主题。它还介绍了Jupyter扩展工具箱、虚拟环境协同、数据清理和自动化报告生成等高级用法。此外,专栏还比较了Jupyter与Python IDE,并提供了数据安全和隐私方面的策略。通过深入的教程、秘籍和最佳实践,该专栏旨在帮助读者充分利用Jupyter,提高Python编程效率和数据分析能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VisionPro故障诊断手册:网络问题的系统诊断与调试

# 摘要
网络问题诊断与调试是确保网络高效、稳定运行的关键环节。本文从网络基础理论与故障模型出发,详细阐述了网络通信协议、网络故障的类型及原因,并介绍网络故障诊断的理论框架和管理工具。随后,本文深入探讨了网络故障诊断的实践技巧,包括诊断工具与命令、故障定位方法以及
【Nginx负载均衡终极指南】:打造属于你的高效访问入口
.webp)
# 摘要
Nginx作为一款高性能的HTTP和反向代理服务器,已成为实现负载均衡的首选工具之一。本文首先介绍了Nginx负载均衡的概念及其理论基础,阐述了负载均衡的定义、作用以及常见算法,进而探讨了Nginx的架构和关键组件。文章深入到配置实践,解析了Nginx配置文件的关键指令,并通过具体配置案例展示了如何在不同场景下设置Nginx以实现高效的负载分配。
云计算助力餐饮业:系统部署与管理的最佳实践
# 摘要
云计算作为一种先进的信息技术,在餐饮业中的应用正日益普及。本文详细探讨了云计算与餐饮业务的结合方式,包括不同类型和部署模型的云服务,并分析了其在成本效益、扩展性、资源分配和高可用性等方面的优势。文中还提供餐饮业务系统云部署的实践案例,包括云服务选择、迁移策略以及安全合规性方面的考量。进一步地,文章深入讨论了餐饮业务云管理与优化的方法,并通过案例研究展示了云计算在餐饮业中的成功应用。最后,本文对云计算在餐饮业中
【Nginx安全与性能】:根目录迁移,如何在保障安全的同时优化性能
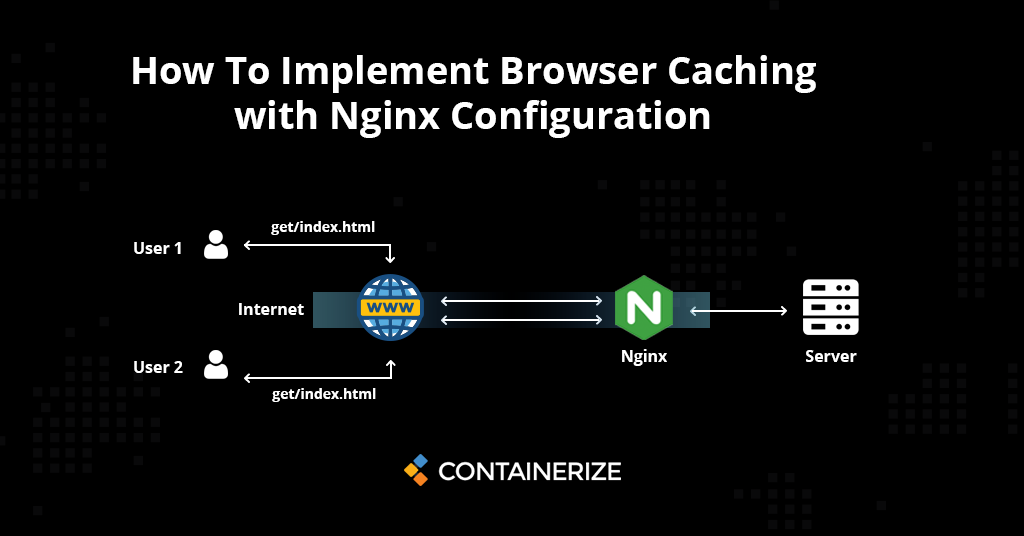
# 摘要
本文对Nginx根目录迁移过程、安全性加固策略、性能优化技巧及实践指南进行了全面的探讨。首先概述了根目录迁移的必要性与准备步骤,随后深入分析了如何加固Nginx的安全性,包括访问控制、证书加密、
RJ-CMS主题模板定制:个性化内容展示的终极指南

# 摘要
本文详细介绍了RJ-CMS主题模板定制的各个方面,涵盖基础架构、语言教程、最佳实践、理论与实践、高级技巧以及未来发展趋势。通过解析RJ-CMS模板的文件结构和继承机制,介绍基本语法和标签使用,本文旨在提供一套系统的方法论,以指导用户进行高效和安全的主题定制。同时,本文也探讨了如何优化定制化模板的性能,并分析了模板定制过程中的高级技术应用和安全性问题。最后,本文展望了RJ-CMS模板定制的
【板坯连铸热传导进阶】:专家教你如何精确预测和控制温度场

# 摘要
本文系统地探讨了板坯连铸过程中热传导的基础理论及其优化方法。首先,介绍了热传导的基本理论和建立热传导模型的方法,包括导热微分方程及其边界和初始条件的设定。接着,详细阐述了热传导模型的数值解法,并分析了影响模型准确性的多种因素,如材料热物性、几何尺寸和环境条件。本文还讨论了温度场预测的计算方法,包括有限差分法、有限元法和边界元法,并对温度场控制技术进行了深入分析。最后,文章探讨了温度场优化策略、
【性能优化大揭秘】:3个方法显著提升Android自定义View公交轨迹图响应速度

# 摘要
本文旨在探讨Android自定义View在实现公交轨迹图时的性能优化。首先介绍了自定义View的基础知识及其在公交轨迹图中应用的基本要求。随后,文章深入分析了性能瓶颈,包括常见性能问题如界面卡顿、内存泄漏,以及绘制过程中的性能考量。接着,提出了提升响应速度的三大方法论,包括减少视图层次、视图更新优化以及异步处理和多线程技术应用。第四章通过实践应用展示了性能优化的实战过程和
Python环境管理:一次性解决Scripts文件夹不出现的根本原因

# 摘要
本文系统地探讨了Python环境的管理,从Python安装与配置的基础知识,到Scripts文件夹生成和管理的机制,再到解决环境问题的实践案例。文章首先介绍了Python环境管理的基本概念,详细阐述了安装Python解释器、配置环境变量以及使用虚拟环境的重要性。随
通讯录备份系统高可用性设计:MySQL集群与负载均衡实战技巧

# 摘要
本文探讨了通讯录备份系统的高可用性架构设计及其实际应用。首先对MySQL集群基础进行了详细的分析,包括集群的原理、搭建与配置以及数据同步与管理。随后,文章深入探讨了负载均衡技术的原理与实践,及其与MySQL集群的整合方法。在此基础上,详细阐述了通讯录备份系统的高可用性架构设计,包括架构的需求与目标、双活或多活数据库架构的构建,以及监
【20分钟精通MPU-9250】:九轴传感器全攻略,从入门到精通(必备手册)

# 摘要
本文对MPU-9250传感器进行了全面的概述,涵盖了其市场定位、理论基础、硬件连接、实践应用、高级应用技巧以及故障排除与调试等方面。首先,介绍了MPU-9250作为一种九轴传感器的工作原理及其在数据融合中的应用。随后,详细阐述了传感器的硬件连
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )