支持matplotlib.pyplot和numpy的在线编译网站
时间: 2024-06-06 10:06:10 浏览: 249
有很多在线编译网站支持numpy和matplotlib.pyplot,下面列出几个常用的:
1. Colab:Google提供的在线Jupyter笔记本,支持numpy和matplotlib.pyplot等常用的Python库。
2. Repl.it:一个在线代码编写和分享平台,支持Python、numpy和matplotlib.pyplot等常用的Python库。
3. OnlineGDB:一个在线IDE,支持多种编程语言,包括Python、numpy和matplotlib.pyplot等常用的Python库。
4. CodeSandbox:一个在线代码编辑器,支持多种编程语言,包括Python、numpy和matplotlib.pyplot等常用的Python库。
这些网站都提供了在线编写和运行Python代码的功能,您可以根据自己的需求选择其中的一个。
相关问题
import pandas as pd import numpy as np import datetime import matplotlib.pyplot as plt from pandas.plotting import radviz该环境下输出每次更新的权重的代码
好的,以下是一个基于TensorFlow的神经网络模型,可以输出每次更新的权重的代码:
```python
import tensorflow as tf
from tensorflow import keras
import pandas as pd
import numpy as np
# 加载数据集
data = pd.read_csv('data.csv')
labels = pd.read_csv('labels.csv')
# 构建模型
model = keras.Sequential([
keras.layers.Dense(128, input_shape=(data.shape[1],), activation='relu'),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
# 定义回调函数
class MyCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
for layer in self.model.layers:
weights = layer.get_weights()
print(weights)
# 编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 创建回调函数实例
callbacks = MyCallback()
# 训练模型
model.fit(data, labels, epochs=10, verbose=1, callbacks=[callbacks])
```
这个代码首先加载了数据集,然后定义了一个包含三个层的神经网络模型。模型的第一层是一个具有128个神经元的全连接层,使用ReLU激活函数。第二层是一个具有64个神经元的全连接层,同样使用ReLU激活函数。最后一层是一个具有1个神经元的全连接层,使用sigmoid激活函数。
接着,代码定义了一个回调函数MyCallback,当每个epoch结束时,该函数会输出每个层的权重。
然后,代码编译了模型,使用adam优化器和二元交叉熵损失函数进行训练,并在控制台输出了训练过程中的准确率等信息。使用callbacks=[callbacks]将回调函数传递给了fit()函数,以便在每个epoch结束时调用回调函数。
希望这个代码对你有所帮助!
import numpy as np import matplotlib.pyplot as plt import pandas as pd import math from keras.models import Sequential from keras.layers import Dense, Activation, Dropout, LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error from keras import optimizers import time解说代码
这段代码主要是用于机器学习模型的建立和训练,具体解释如下:
- `numpy` 是 Python 中用于科学计算的一个库。
- `matplotlib` 是 Python 中一个常用的绘图库。
- `pandas` 是 Python 中用于数据分析的一个库。
- `math` 是 Python 中的数学库,提供了许多数学函数。
- `keras` 是一个用于构建深度学习模型的框架。
- `Sequential` 是 Keras 中的一种模型类型,表示将多个神经网络层按顺序堆叠的模型。
- `Dense` 是 Keras 中的一种层类型,表示全连接层。
- `Activation` 是 Keras 中的一种层类型,表示激活函数层。
- `Dropout` 是 Keras 中的一种层类型,表示随机丢弃一定比例的神经元,以防止过拟合。
- `LSTM` 是 Keras 中的一种层类型,表示长短期记忆网络,用于处理序列数据。
- `MinMaxScaler` 是 scikit-learn 中的一个预处理类,用于将数据缩放到指定范围内。
- `mean_squared_error` 是 scikit-learn 中的一个回归评价指标,用于计算均方误差。
- `optimizers` 是 Keras 中的一个优化器模块,提供了多种优化算法。
这段代码中主要完成了以下几个任务:
1. 导入所需的库和模块。
2. 定义一个序列模型 `Sequential`。
3. 添加多个全连接层 `Dense`,并使用激活函数 `Activation` 进行非线性变换。
4. 添加多个随机丢弃层 `Dropout`,以防止过拟合。
5. 添加一个 LSTM 层 `LSTM`,用于处理序列数据。
6. 编译模型,并指定优化算法和评价指标。
7. 对数据进行预处理,将其缩放到指定范围内。
8. 将训练数据拟合到模型中,并指定训练次数和批次大小。
9. 对测试数据进行预测,并计算均方误差。
相关推荐
最新推荐
Python的地形三维可视化Matplotlib和gdal使用实例
【Python的地形三维可视化】是Python编程领域中的一个重要应用,主要通过使用Matplotlib和gdal这两个库来实现。Matplotlib是Python中最常用的绘图库,它提供了丰富的图表绘制功能,包括二维和三维图形。gdal则是一个...
解决Matplotlib图表不能在Pycharm中显示的问题
当尝试在PyCharm中运行`%matplotlib inline`时,会出现编译错误。 Magic Function是IPython特有的功能,它们是预定义的一系列命令,用于增强IPython的交互性。行Magic Function以`%`开头,如`%timeit`,用于测量...
文件转换为Base64形式(可来回转换,带加密功能)
文件转换为Base64形式(可来回转换,带加密功能)
使用说明
===
https://blog.csdn.net/sxzlc/article/details/139076076
====
基于粒子群算法的配电网日前优化调度 采用IEEE33节点配电网搭建含风光,储能,柴油发电机和燃气轮机的经济调度模型 以运行成本
基于粒子群算法的配电网日前优化调度
采用IEEE33节点配电网搭建含风光,储能,柴油发电机和燃气轮机的经济调度模型。
以运行成本和环境成本最小为目标,考虑储能以及潮流等约束,采用粒子群算法对模型进行求解,得到电源的每小时出力情况。
ECU ccp协议上位机测试与标定源码,C#源码上位机ECU标定与测量程序 - ASAM MCD -1MC的 ccp 标定与测
ECU ccp协议上位机测试与标定源码,C#源码上位机ECU标定与测量程序。
- ASAM MCD -1MC的 ccp 标定与测量上位机软件,短上传和DAQ功能,支持一维二维等测量和标定,显示控件丰富,具有仪表盘,进度条,二维map等。
- ASAM MCD-2MC 的文件读取(a2l文件读取)
- 在解析的同时提供了文件结构检查
- 读取和导出ECU 测量数据为excel文件
- 支持多个设备 ,包括 ETAs, Vector, Peak, 8Devices, Kvaser, usbcan兼容设备 等等CAN设备的支持,同时有一个简单的接口,用于实现其他设备支持,接口dll函数替即可。
.Net 目标框架为 4.0,需要引用Excel程序,默认版本为 office 2019,也可在源码中修改。
BGP协议首选值(PrefVal)属性与模拟组网实验
资源摘要信息: "本课程介绍了边界网关协议(BGP)中一个关键的概念——协议首选值(PrefVal)属性。BGP是互联网上使用的一种核心路由协议,用于在不同的自治系统之间交换路由信息。在BGP选路过程中,有多个属性会被用来决定最佳路径,而协议首选值就是其中之一。虽然它是一个私有属性,但其作用类似于Cisco IOS中的管理性权值(Administrative Weight),可以被网络管理员主动设置,用于反映本地用户对于不同路由的偏好。
协议首选值(PrefVal)属性仅在本地路由器上有效,不会通过BGP协议传递给邻居路由器。这意味着,该属性不会影响其他路由器的路由决策,只对设置它的路由器本身有用。管理员可以根据网络策略或业务需求,对不同的路由设置不同的首选值。当路由器收到多条到达同一目的地址前缀的路由时,它会优先选择具有最大首选值的那一条路由。如果没有显式地设置首选值,从邻居学习到的路由将默认拥有首选值0。
在BGP的选路决策中,首选值(PrefVal)通常会被优先考虑。即使其他属性(如AS路径长度、下一跳的可达性等)可能对选路结果有显著影响,但是BGP会首先比较所有候选路由的首选值。因此,对首选值的合理配置可以有效地控制流量的走向,从而满足特定的业务需求或优化网络性能。
值得注意的是,华为和华三等厂商定义了协议首选值(PrefVal)这一私有属性,这体现了不同网络设备供应商可能会有自己的扩展属性来满足特定的市场需求。对于使用这些厂商设备的网络管理员来说,了解并正确配置这些私有属性是十分重要的。
课程还提到模拟器使用的是HCL 5.5.0版本。HCL(Hewlett Packard Enterprise Command Language)是惠普企业开发的一种脚本语言,它通常用于自动化网络设备的配置和管理任务。在本课程的上下文中,HCL可能被用来配置模拟组网实验,帮助学生更好地理解和掌握BGP协议首选值属性的实际应用。
通过本课程的学习,学生应该能够掌握如何在实际的网络环境中应用协议首选值属性来优化路由决策,并能够熟练地使用相关工具进行模拟实验,以加深对BGP选路过程的理解。"
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
【Django异常处理精讲】:从错误中提炼最佳实践(案例分析)
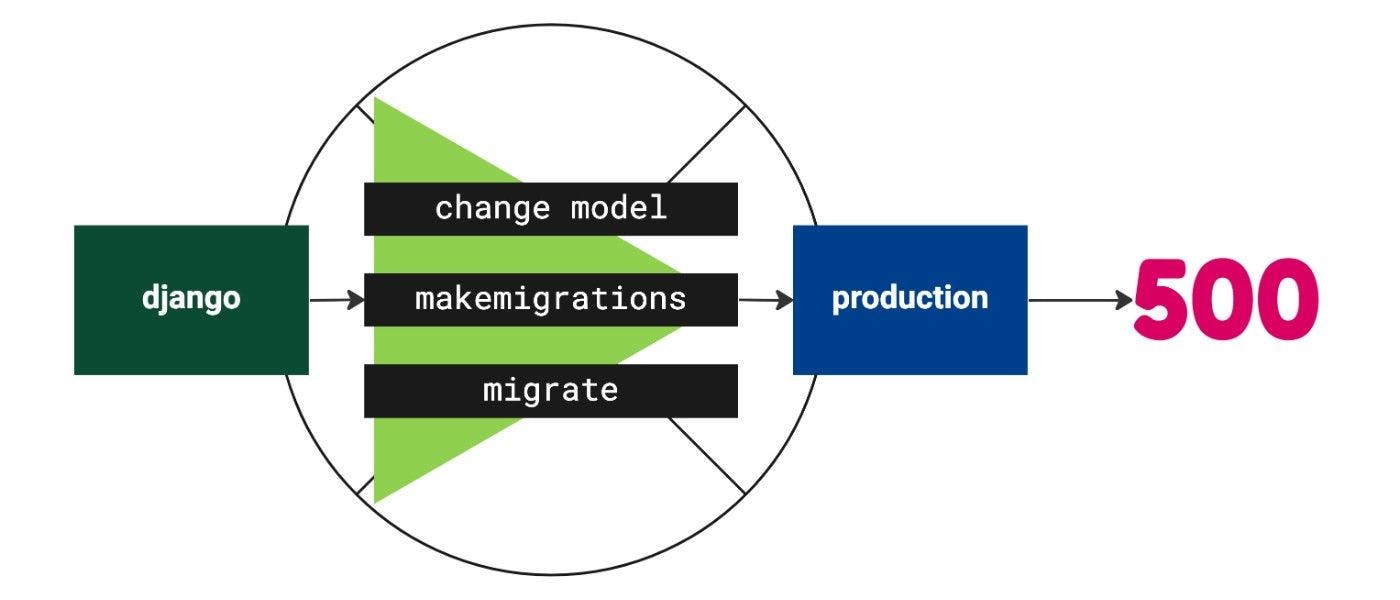
# 1. Django异常处理概述
## Django异常处理的基本概念
在编写Web应用时,处理异常是确保系统健壮性的重要环节。Django作为一个高级的Python Web框架,提供了强大的异常处理机制。了解Django异常处理的基本概念是构建稳定应用的起点。
## 异常处理的重要性
Django中的异常处理确保了当错误发生时,应用能够优雅地处理错误,并向用
圆有没有办法知道顺逆,已经知道圆心 半径 数学方法 C++
确定一个圆弧是顺时针还是逆时针(即所谓的顺逆圆),通常依赖于起点和终点相对于圆心的位置关系。如果你已经知道圆心坐标(x, y)和半径r,可以通过计算向量的叉积来判断:
1. 首先,计算起点到圆心的向量OP1 = (x - x0, y - y0),其中(x0, y0)是圆心坐标。
2. 再计算终点到圆心的向量OP2 = (x1 - x0, y1 - y0),其中(x1, y1)是另一个已知点的坐标。
3. 计算这两个向量的叉积,如果结果是正数,则弧从起点顺时针到终点;如果是负数,则逆时针;如果等于零,则表示两点重合,无法判断。
在C++中,可以这样实现:
```cpp
#include <
C#实现VS***单元测试coverage文件转xml工具
资源摘要信息:"VS***单元测试的coverage文件转换为xml文件源代码"
知识点一:VS***单元测试coverage文件
VS2010(Visual Studio 2010)是一款由微软公司开发的集成开发环境(IDE),其中包含了单元测试功能。单元测试是在软件开发过程中,针对最小的可测试单元(通常是函数或方法)进行检查和验证的一种测试方法。通过单元测试,开发者可以验证代码的各个部分是否按预期工作。
coverage文件是单元测试的一个重要输出结果,它记录了哪些代码被执行到了,哪些没有。通过分析coverage文件,开发者能够了解代码的测试覆盖情况,识别未被测试覆盖的代码区域,从而优化测试用例,提高代码质量。
知识点二:coverage文件转换为xml文件的问题
在实际开发过程中,开发人员通常需要将coverage文件转换为xml格式以供后续的处理和分析。然而,VS2010本身并不提供将coverage文件直接转换为xml文件的命令行工具或选项。这导致了开发人员在处理大规模项目或者需要自动化处理coverage数据时遇到了障碍。
知识点三:C#代码转换coverage为xml文件
为解决上述问题,可以通过编写C#代码来实现coverage文件到xml文件的转换。具体的实现方式是通过读取coverage文件的内容,解析文件中的数据,然后按照xml格式的要求重新组织数据并输出到xml文件中。这种方法的优点是可以灵活定制输出内容,满足各种特定需求。
知识点四:Coverage2xml工具的使用说明
Coverage2xml是一个用C#实现的工具,专门用于将VS2010的coverage文件转换为xml文件。该工具的使用方法十分简单,主要通过命令行调用,并接受三个参数:
- coveragePath:coverage文件的路径。
- dllDir:单元测试项目生成的dll文件所在的目录。
- xmlPath:转换后xml文件的存储路径。
使用示例为:Coverage2xml e:\data.coverage e:\debug e:\xx.xml。在这个示例中,coverage文件位于e:\data.coverage,单元测试项目的dll文件位于e:\debug目录下,转换生成的xml文件将保存在e:\xx.xml。
知识点五:xml文件的作用
xml(可扩展标记语言)是一种用于存储和传输数据的标记语言。它具有良好的结构化特性,能够清晰地描述数据的层次和关系。xml文件在软件开发领域有着广泛的应用,常被用作配置文件、数据交换格式等。
通过将coverage文件转换为xml格式,开发人员可以更方便地利用各种xml处理工具或库对测试覆盖数据进行分析、比较或集成到其他系统中。例如,可以使用xml处理库来编写脚本,自动化地生成覆盖报告,或者将覆盖数据与其他系统集成以进行更深入的分析。
知识点六:软件包的结构
在提供的文件信息中,还包含了一个压缩包文件名称列表,其中包含了README.md、Coverage2xml.sln和Coverage2xml三个文件。README.md文件通常包含项目的说明文档,介绍了如何使用该项目以及任何安装和配置指南。Coverage2xml.sln是Visual Studio解决方案文件,用于加载和构建项目。Coverage2xml则可能是实际执行转换操作的可执行文件或源代码文件。
总的来说,这个压缩包可能包含了一个完整的软件包,提供了工具的源代码、编译后的可执行文件以及相关文档,方便用户直接下载、使用和理解如何操作这个工具。