用Python运行感知机算法,尝试对一个数据集多次分类,对多个数据集进行分类
时间: 2024-09-27 18:09:25 浏览: 4
在Python中,我们可以使用scikit-learn库来实现感知机算法(Perceptron),这是一个常用的线性分类模型。下面是一个基本步骤:
1. **安装所需库**:首先确保已经安装了`numpy`, `pandas`以及`sklearn`库,如果没有,可以使用pip安装:
```
pip install numpy pandas scikit-learn
```
2. **加载和预处理数据**:
```python
import pandas as pd
from sklearn.model_selection import train_test_split
X = ... # 数据特征(例如二维数组)
y = ... # 目标变量(二进制标签)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
```
3. **创建并训练Perceptron模型**:
```python
from sklearn.linear_model import Perceptron
perceptron = Perceptron()
perceptron.fit(X_train, y_train)
```
4. **多次分类及评估**:
- 可以通过循环多次训练和测试,比如每次迭代使用不同的学习率或迭代次数,观察模型性能变化:
```python
for lr in [0.1, 0.5]: # 不同的学习率
perceptron = Perceptron(learning_rate=lr)
perceptron.fit(X_train, y_train)
predictions = perceptron.predict(X_test)
accuracy = (predictions == y_test).mean() # 计算准确率
print(f"Learning rate: {lr}, Accuracy: {accuracy}")
```
5. **处理多个数据集**:
如果有多个数据集,可以在每个数据集上重复上述步骤。通常,我们会将数据拆分为训练集和测试集,确保每个数据集都能得到验证。
相关推荐
最新推荐
基于鸢尾花数据集实现线性判别式多分类
在本项目中,我们利用鸢尾花数据集(Iris dataset)实现了一个基于逻辑斯蒂判别式(Logistic Discriminant Analysis, LDA)的多分类算法。鸢尾花数据集是一个经典的数据集,它包含了三种不同类型的鸢尾花样本,每种...
python实现多层感知器MLP(基于双月数据集)
在本教程中,我们将深入探讨如何使用Python实现一个多层感知器(MLP,Multilayer Perceptron)神经网络,特别是在处理双月数据集时。多层感知器是一种前馈神经网络,它允许非线性建模,适用于解决复杂的分类和回归...
python实现将两个文件夹合并至另一个文件夹(制作数据集)
在Python编程中,合并两个文件夹到另一个文件夹是一个常见的任务,特别是在数据预处理阶段,如制作深度学习数据集。本教程将详细讲解如何利用Python完成这个任务。 首先,我们需要导入必要的库,如`numpy`、`os`和`...
python 实现对数据集的归一化的方法(0-1之间)
本文将详细介绍如何使用Python的`sklearn`库中的`MinMaxScaler`对数据集进行归一化,使其值位于0到1之间。 归一化是将原始数据按比例缩放,使之落入一个特定的小区间,通常这个区间是[0, 1]。这样处理的原因在于,...
【K-means算法】{1} —— 使用Python实现K-means算法并处理Iris数据集
4. 使用一个循环进行迭代,直到质心不再改变或达到最大迭代次数: - 对于每个样本点,计算其与所有质心的距离,找到最近的那个质心并将样本点分配给对应的簇。 - 如果所有样本点的簇分配没有变化,则认为算法已经...
批量文件重命名神器:HaoZipRename使用技巧
资源摘要信息:"超实用的批量文件改名字小工具rename"
在进行文件管理时,经常会遇到需要对大量文件进行重命名的场景,以统一格式或适应特定的需求。此时,批量重命名工具成为了提高工作效率的得力助手。本资源聚焦于介绍一款名为“rename”的批量文件改名工具,它支持增删查改文件名,并能够方便地批量操作,从而极大地简化了文件管理流程。
### 知识点一:批量文件重命名的需求与场景
在日常工作中,无论是出于整理归档的目的还是为了符合特定的命名规则,批量重命名文件都是一个常见的需求。例如:
- 企业或组织中的文件归档,可能需要按照特定的格式命名,以便于管理和检索。
- 在处理下载的多媒体文件时,可能需要根据文件类型、日期或其他属性重新命名。
- 在软件开发过程中,对代码文件或资源文件进行统一的命名规范。
### 知识点二:rename工具的基本功能
rename工具专门设计用来处理文件名的批量修改,其基本功能包括但不限于:
- **批量修改**:一次性对多个文件进行重命名。
- **增删操作**:在文件名中添加或删除特定的文本。
- **查改功能**:查找文件名中的特定文本并将其替换为其他文本。
- **格式统一**:为一系列文件统一命名格式。
### 知识点三:使用rename工具的具体操作
以rename工具进行批量文件重命名通常遵循以下步骤:
1. 选择文件:根据需求选定需要重命名的文件列表。
2. 设定规则:定义重命名的规则,比如在文件名前添加“2023_”,或者将文件名中的“-”替换为“_”。
3. 执行重命名:应用设定的规则,批量修改文件名。
4. 预览与确认:在执行之前,工具通常会提供预览功能,允许用户查看重命名后的文件名,并进行最终确认。
### 知识点四:rename工具的使用场景
rename工具在不同的使用场景下能够发挥不同的作用:
- **IT行业**:对于软件开发者或系统管理员来说,批量重命名能够快速调整代码库中文件的命名结构,或者修改服务器上的文件名。
- **媒体制作**:视频编辑和摄影师经常需要批量重命名图片和视频文件,以便更好地进行分类和检索。
- **教育与学术**:教授和研究人员可能需要批量重命名大量的文档和资料,以符合学术规范或方便资料共享。
### 知识点五:rename工具的高级特性
除了基本的批量重命名功能,一些高级的rename工具可能还具备以下特性:
- **正则表达式支持**:利用正则表达式可以进行复杂的查找和替换操作。
- **模式匹配**:可以定义多种匹配模式,满足不同的重命名需求。
- **图形用户界面**:提供直观的操作界面,简化用户的操作流程。
- **命令行操作**:对于高级用户,可以通过命令行界面进行更为精准的定制化操作。
### 知识点六:与rename相似的其他批量文件重命名工具
除了rename工具之外,还有多种其他工具可以实现批量文件重命名的功能,如:
- **Bulk Rename Utility**:一个功能强大的批量重命名工具,特别适合Windows用户。
- **Advanced Renamer**:提供图形界面,并支持脚本,用户可以创建复杂的重命名方案。
- **MMB Free Batch Rename**:一款免费且易于使用的批量重命名工具,具有直观的用户界面。
### 知识点七:避免批量重命名中的常见错误
在使用批量重命名工具时,有几个常见的错误需要注意:
- **备份重要文件**:在批量重命名之前,确保对文件进行了备份,以防意外发生。
- **仔细检查规则**:设置好规则之后,一定要进行检查,确保规则的准确性,以免出现错误的命名。
- **逐步执行**:如果不确定规则的效果,可以先小批量试运行规则,确认无误后再批量执行。
- **避免使用通配符**:在没有充分理解通配符含义的情况下,不建议使用,以免误操作。
综上所述,批量文件改名工具rename是一个高效、便捷的解决方案,用于处理大量文件的重命名工作。通过掌握其使用方法和技巧,用户可以显著提升文件管理的效率,同时减少重复劳动,保持文件系统的整洁和有序。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
RestTemplate性能优化秘籍:提升API调用效率,打造极致响应速度
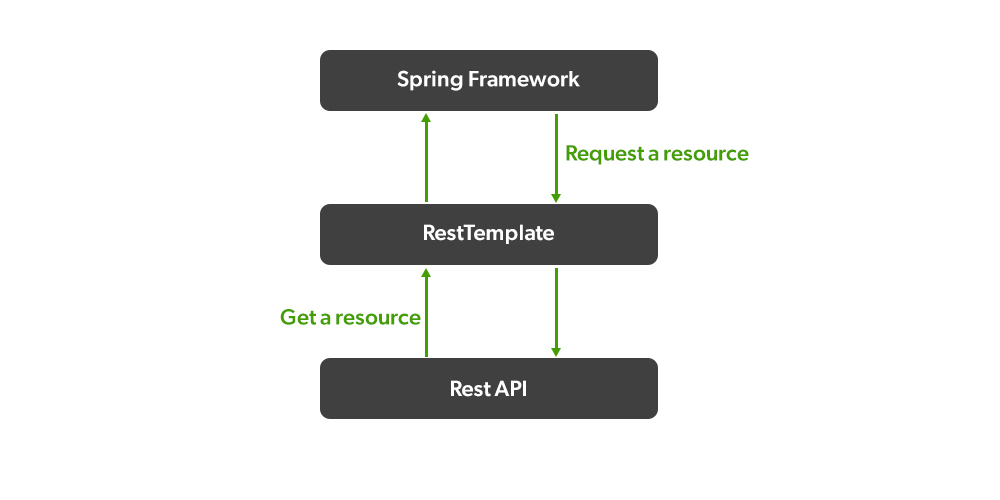
# 1. RestTemplate基础与API调用概述
## 1.1 RestTemplate简介
`RestTemplate`是Spring框架提供的一个同步HTTP客户端,设计用来简化客户端HTTP请求的发送以及HTTP响应的接收。它是针对Java开发者的REST API调用的高级抽象,为调用RESTful服务提供了便利。
Leader和follower 位置反了如何调换zookeeper
在ZooKeeper中,Leader和Follower的角色通常是静态分配的,并通过选举机制确定。如果需要调整它们的位置,通常是在集群初始化或者节点失效的情况下,会触发重新选举过程。
1. **停止服务**:首先,停止ZooKeeper服务的所有节点,包括当前的Leader和Follower。
2. **修改配置**:打开zoo.cfg配置文件,更改服务器列表(server.X=IP:port:角色),将原来的Leader的地址设为Follower,Follower的地址设为Leader。例如:
```
server.1=old_leader_ip:old_leader_po
简洁注册登录界面设计与代码实现
资源摘要信息:"在现代Web开发中,简洁美观的注册登录页面是用户界面设计的重要组成部分。简洁的页面设计不仅能够提升用户体验,还能提高用户完成注册或登录流程的意愿。本文将详细介绍如何创建两个简洁且功能完善的注册登录页面,涉及HTML5和前端技术。"
### 知识点一:HTML5基础
- **语义化标签**:HTML5引入了许多新标签,如`<header>`、`<footer>`、`<article>`、`<section>`等,这些语义化标签不仅有助于页面结构的清晰,还有利于搜索引擎优化(SEO)。
- **表单标签**:`<form>`标签是创建注册登录页面的核心,配合`<input>`、`<button>`、`<label>`等元素,可以构建出功能完善的表单。
- **增强型输入类型**:HTML5提供了多种新的输入类型,如`email`、`tel`、`number`等,这些类型可以提供更好的用户体验和数据校验。
### 知识点二:前端技术
- **CSS3**:简洁的页面设计往往需要巧妙的CSS布局和样式,如Flexbox或Grid布局技术可以实现灵活的页面布局,而CSS3的动画和过渡效果则可以提升交云体验。
- **JavaScript**:用于增加页面的动态功能,例如表单验证、响应式布局切换、与后端服务器交互等。
### 知识点三:响应式设计
- **媒体查询**:使用CSS媒体查询可以创建响应式设计,确保注册登录页面在不同设备上都能良好显示。
- **流式布局**:通过设置百分比宽度或视口单位(vw/vh),使得页面元素可以根据屏幕大小自动调整大小。
### 知识点四:注册登录页面设计细节
- **界面简洁性**:避免过多的装饰性元素,保持界面的整洁和专业感。
- **易用性**:设计简洁直观的用户交互,确保用户能够轻松理解和操作。
- **安全性和隐私**:注册登录页面应特别注意用户数据的安全,如使用HTTPS协议保护数据传输,以及在前端进行基本的输入验证。
### 知识点五:Zip文件内容解析
- **登录.zip**:该压缩包内可能包含登录页面的HTML、CSS和JavaScript文件,以及相关的图片和其他资源文件。开发者可以利用这些资源快速搭建一个登录界面。
- **滑动登录注册界面.zip**:该压缩包内可能包含了两个页面的文件,分别是注册和登录页面。文件可能包含用HTML5实现的滑动动画效果,通过CSS3和JavaScript的结合实现动态交互,提供更流畅的用户体验。
通过这些知识点,开发者能够创建出既简洁又功能完善的注册登录页面。需要注意的是,尽管页面设计要简洁,但安全措施不可忽视。使用加密技术保护用户数据,以及在用户端进行有效的数据验证,都是开发者在实现简洁界面同时需要考虑的安全要素。