解释下面的代码: for root, dirs, files in os.walk(folder_path): for file_name in files:
时间: 2024-05-22 20:15:00 浏览: 161
这段代码使用Python中的os模块中的walk函数,用于遍历指定文件夹及其子文件夹中的所有文件和文件夹。os.walk会返回3个值,分别是当前遍历到的文件夹路径root、当前文件夹下的目录列表dirs、当前文件夹下的文件列表files。这个for循环中,我们只需要遍历所有的文件,因此针对files列表进行遍历,对于其中的每个文件名file_name,我们可以进行进一步的操作。
相关问题
解释这段代码import os import multiprocessing as mp def count_letters(file_path, letter_counts): with open(file_path, 'r') as f: for line in f: for letter in line: if letter.isalpha(): letter_counts[letter.lower()] += 1 def process_folder(folder_path, letter_counts): for root, dirs, files in os.walk(folder_path): for name in files: if name.endswith('.txt'): file_path = os.path.join(root, name) count_letters(file_path, letter_counts) if __name__ == '__main__': folder_path = 'D:\\pachong\\并行\\blogs\\blogs' num_processes = mp.cpu_count() # 使用所有可用的 CPU 核心数 letter_counts = mp.Manager().dict({letter: 0 for letter in 'abcdefghijklmnopqrstuvwxyz'}) processes = [] for i in range(num_processes): p = mp.Process(target=process_folder, args=(folder_path, letter_counts)) p.start() processes.append(p) for p in processes: p.join() with open('letter_counts.txt', 'w') as f: for letter, count in letter_counts.items(): f.write(f'{letter}: {count}\n')
这段代码使用了 Python 的 multiprocessing 模块,实现了一个多进程的字母计数器。具体来说,代码首先定义了两个函数:
- count_letters(file_path, letter_counts):用于统计文件中每个字母出现的次数,其中 file_path 是文件路径,letter_counts 是一个字典,用于记录每个字母的出现次数。
- process_folder(folder_path, letter_counts):用于遍历目录中的所有文件,并对每个文件调用 count_letters 函数。
在主程序部分,代码首先获取了待处理的文件夹路径和可用的 CPU 核心数。然后,代码创建了一个字典 letter_counts,用于记录每个字母的出现次数,并使用 multiprocessing 模块的 Manager 类将其转换为共享字典,以便多个进程可以同时访问。接下来,代码创建了多个进程,并将它们分别赋予不同的任务。最后,代码等待所有进程完成后,将统计结果写入文件 letter_counts.txt。
需要注意的是,由于 multiprocessing 模块中的进程之间无法直接共享变量,因此这里使用了 Manager 类创建了一个共享字典。此外,为了避免多个进程同时写入同一个文件而导致的冲突,代码将文件写入操作放在了主进程中。
import os import pandas as pd import time while True: start = time.perf_counter() def get_txt_files(folder_path): files = [] try: for root, dirs, filenames in os.walk(folder_path): for filename in filenames: if filename.endswith(".txt"): files.append(os.path.abspath(os.path.join(root, filename))) except Exception as e: print("Error: {}".format(e)) return files def combine_txt_files(txt_files): content = "" try: for txt_file in txt_files: with open(txt_file, "r") as f: content += f.read() except Exception as e: print("Error: {}".format(e)) return content def write_combined_content_to_file(content, file_path): try: with open(file_path, "w") as f: f.write(content) except Exception as e: print("Error: {}".format(e)) def txt_to_excel(txt_file, excel_file): try: df = pd.read_csv(txt_file, delimiter="\t", header=None) df.to_excel(excel_file, index=False, header=None) except Exception as e: print("Error: {}".format(e)) if __name__=="__main__": folder_path="Z:\看板v2" txt_files=get_txt_files(folder_path) combined_content=combine_txt_files(txt_files) combined_file_path="D:\\測試log\\TXT合1并.txt" write_combined_content_to_file(combined_content,combined_file_path) excel_file_path="D:\\測試log\\123.xlsx" txt_to_excel(combined_file_path,excel_file_path) end = time.perf_counter() print('運行時間為:{}秒'.format(end-start)) time.sleep(30)
这是一段 Python 代码,主要功能是将指定文件夹中的所有 .txt 文件合并为一个文件,并将合并后的内容转换为 Excel 文件。
首先使用 `os.walk` 函数获取指定文件夹中所有的 .txt 文件路径,然后使用 `open` 函数读取每个文件的内容,并将所有内容合并为一个字符串。接着使用 `open` 函数将合并后的字符串写入到指定路径的文件中。最后使用 Pandas 库中的 `read_csv` 函数读取合并后的文本文件,并使用 `to_excel` 函数将其转换为 Excel 文件。
代码中使用了一个死循环,每隔 30 秒就会执行一次上述操作。遇到任何异常都会输出错误信息。最后会输出每次操作的运行时间。
阅读全文
相关推荐
大家在看
r3epthook-master.zip
VT ept进行hook,可以隐藏hook
邮件系统灾备方案建议及资源配置-新华人寿灾备方案
邮件系统灾备方案建议及资源配置
建议在灾备中心建立邮件系统作为南方省份公司的邮件服务器,用于分担生产中心工作负荷,北京长沙的邮件系统可以互为灾备。
灾备中心邮件系统服务器的配置
3台PC服务器(2C1G)(邮件接收、发送服务器及前端邮件服务器)
2台PC服务器(2C4G)(后台邮件服务器)
1台PC服务器(2C2G)(域用户管理及DNS服务器)
应用环境
Exchange 2003
北京
长沙
北方各省公司的
生产邮件服务器
南方各省公司的
备份邮件服务器
南方各省公司的
生产邮件服务器
北方各省公司的
备份邮件服务器
底层数据
复制
底层数据
复制
SSL and TLS Theory and Practice.pdf
SSL and TLS Theory and Practice.pdf SSL and TLS Theory and Practice.pdf SSL and TLS Theory and Practice.pdf SSL and TLS Theory and Practice.pdf SSL and TLS Theory and Practice.pdf SSL and TLS Theory and Practice.pdf SSL and TLS Theory and Practice.pdf SSL and TLS Theory and Practice.pdf SSL and TLS Theory and Practice.pdf
QT实现动画右下角提示信息弹窗
QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动画右下角提示信息弹窗QT实现动
HP 3PAR 存储配置手册(详细)
根据HP原厂工程师的指导,把每一步的详细配置过程按配置顺序都用QQ进行了截图,并在每张截图下面都有详细说明,没接触过3PAR的人用这个手册完全可以完成初始化的配置过程,包括加主机、加CPG、加VV、映射,另外还包括这个存储的一些特殊概念的描述。因为是一点点做出来的,而且很详细。
最新推荐
Java源码ssm框架的房屋租赁系统-合同-毕业设计论文-期末大作业.rar
本项目是一个基于Java源码的SSM框架房屋租赁系统,旨在为房屋租赁市场提供一个便捷、高效、安全的管理平台。系统主要功能包括房屋信息管理、租赁合同管理、租金收取管理、租客信息管理等。通过该系统,房东可以轻松发布房屋信息,管理租赁合同和租金收取,而租客则可以方便地查找合适的房源,提交租赁申请,签订电子合同,并进行租金支付。系统采用SSM框架(Spring、Spring MVC、MyBatis)进行开发,确保了系统的稳定性和扩展性。Spring框架负责依赖注入和业务逻辑管理,Spring MVC处理前端请求和页面展示,MyBatis则用于数据库操作。项目还集成了权限管理、日志记录等模块,提升了系统的安全性和可维护性。项目为完整毕设源码,先看项目演示,希望对需要的同学有帮助。
MDM Bypasser Tool激活锁并保存数据工具
MDM Bypasser Tool激活锁并保存数据工具
绕过 iPhone 上的 iCloud 激活锁并保存您的数据。
OC-Dialect线上多语言(多列表) 3.SDK每个方法解析
OC-Dialect线上多语言(多列表) 3.SDK每个方法解析
数学实验中MATLAB的应用技巧与实例解析
内容概要:本文档围绕数学实验的MATLAB应用进行了详细介绍,涵盖了基本的四则运算、含有三角函数和指数函数的复杂运算、向量及其多种类型的运算方法(包括数乘、加减及点积计算)、不同方式实现的数的阶乘(普通脚本函数、递归函数以及直接利用MATLAB内置函数)和矩阵的基本及高级运算等多个方面的内容。每个部分都有25道练习题目帮助理解。
适合人群:面向对MATLAB感兴趣的学习者和有一定编程基础的研究者。
使用场景及目标:通过一系列具体的数学实验和编程训练,加深对于MATLAB这一强大科学计算工具的认识与掌握程度,能够灵活运用各种基本函数解决实际问题。
阅读建议:随着教程逐步深入,读者应在电脑上跟随指南亲自操作,以便更好地理解决定思路与具体步骤,将理论转化为实操能力。
Java源码ssm框架汽车在线销售系统-毕业设计论文-期末大作业.rar
本项目是一个基于Java源码的SSM框架汽车在线销售系统,旨在为汽车销售行业提供一个便捷、高效的在线交易平台。系统采用了Spring、Spring MVC和MyBatis三大框架技术,实现了前后端的分离与高效交互,确保了系统的稳定性和可扩展性。主要功能包括用户注册与登录、汽车信息展示、在线购车、订单管理、支付系统以及客户服务等。用户可以通过系统浏览各类汽车信息,进行在线咨询和购买,系统提供了详细的车型介绍、价格以及用户评价等信息,帮助用户做出更为明智的购车决策。订单管理模块允许用户查看和管理自己的购车订单,支付系统则支持多种支付方式,确保交易的安全与便捷。项目为完整毕设源码,先看项目演示,希望对需要的同学有帮助。
易语言例程:用易核心支持库打造功能丰富的IE浏览框
资源摘要信息:"易语言-易核心支持库实现功能完善的IE浏览框"
易语言是一种简单易学的编程语言,主要面向中文用户。它提供了大量的库和组件,使得开发者能够快速开发各种应用程序。在易语言中,通过调用易核心支持库,可以实现功能完善的IE浏览框。IE浏览框,顾名思义,就是能够在一个应用程序窗口内嵌入一个Internet Explorer浏览器控件,从而实现网页浏览的功能。
易核心支持库是易语言中的一个重要组件,它提供了对IE浏览器核心的调用接口,使得开发者能够在易语言环境下使用IE浏览器的功能。通过这种方式,开发者可以创建一个具有完整功能的IE浏览器实例,它不仅能够显示网页,还能够支持各种浏览器操作,如前进、后退、刷新、停止等,并且还能够响应各种事件,如页面加载完成、链接点击等。
在易语言中实现IE浏览框,通常需要以下几个步骤:
1. 引入易核心支持库:首先需要在易语言的开发环境中引入易核心支持库,这样才能在程序中使用库提供的功能。
2. 创建浏览器控件:使用易核心支持库提供的API,创建一个浏览器控件实例。在这个过程中,可以设置控件的初始大小、位置等属性。
3. 加载网页:将浏览器控件与一个网页地址关联起来,即可在控件中加载显示网页内容。
4. 控制浏览器行为:通过易核心支持库提供的接口,可以控制浏览器的行为,如前进、后退、刷新页面等。同时,也可以响应浏览器事件,实现自定义的交互逻辑。
5. 调试和优化:在开发完成后,需要对IE浏览框进行调试,确保其在不同的操作和网页内容下均能够正常工作。对于性能和兼容性的问题需要进行相应的优化处理。
易语言的易核心支持库使得在易语言环境下实现IE浏览框变得非常方便,它极大地降低了开发难度,并且提高了开发效率。由于易语言的易用性,即使是初学者也能够在短时间内学会如何创建和操作IE浏览框,实现网页浏览的功能。
需要注意的是,由于IE浏览器已经逐渐被微软边缘浏览器(Microsoft Edge)所替代,使用IE核心的技术未来可能面临兼容性和安全性的挑战。因此,在实际开发中,开发者应考虑到这一点,并根据需求选择合适的浏览器控件实现技术。
此外,易语言虽然简化了编程过程,但其在功能上可能不如主流的编程语言(如C++, Java等)强大,且社区和技术支持相比其他语言可能较为有限,这些都是在选择易语言作为开发工具时需要考虑的因素。
文件名列表中的“IE类”可能是指包含实现IE浏览框功能的类库或者示例代码。在易语言中,类库是一组封装好的代码模块,其中包含了各种功能的实现。通过在易语言项目中引用这些类库,开发者可以简化开发过程,快速实现特定功能。而示例代码则为开发者提供了具体的实现参考,帮助理解和学习如何使用易核心支持库来创建IE浏览框。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
STM32F407ZG引脚功能深度剖析:掌握引脚分布与配置的秘密(全面解读)
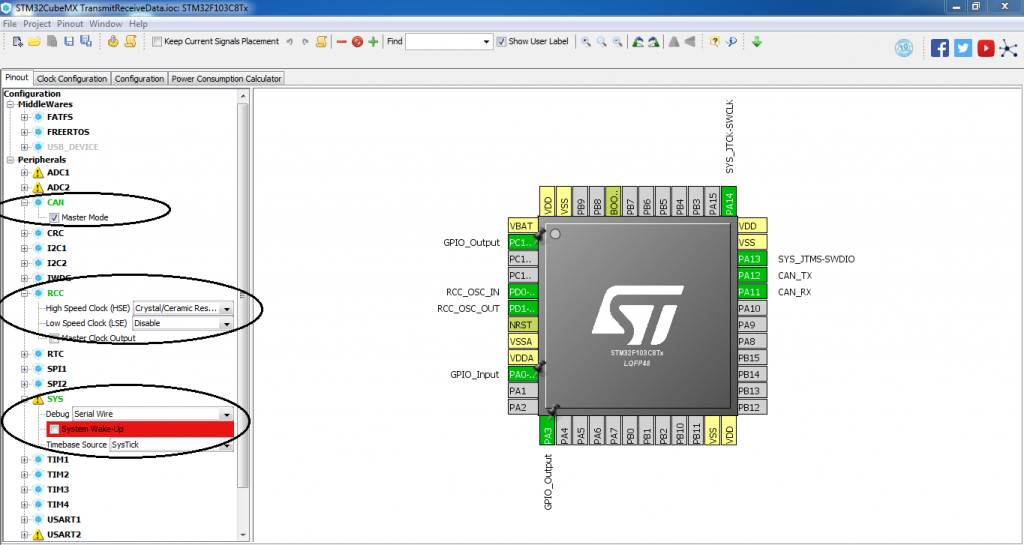
# 摘要
本文全面介绍了STM32F407ZG微控制器的引脚特性、功能、配置和应用。首先概述了该芯片的引脚布局,然后详细探讨了标准外设、高级控制以及特殊功能引脚的不同配置和使用方法。在此基础上,文章深入分析了引脚模式配置、高级配置技巧,并提供了实际应用案例,如LED控制和串口通信。在设计方面,阐述了引脚布局策略、多层板设计及高密度引脚应用的解决方案。最后,介绍
给出文档中问题的答案代码
您提到的是需要编写MATLAB代码来实现文档中的实验任务。以下是根据文档内容编写的MATLAB代码示例:
```matlab
% 上机2 实验代码
% 读取输入图像
inputImage = imread('your_face_image.jpg'); % 替换为您的图像文件路径
if size(inputImage, 1) < 1024 || size(inputImage, 2) < 1024
error('图像尺寸必须大于1024x1024');
end
% 将彩色图像转换为灰度图像
grayImage = rgb2gray(inputImage);
% 调整图像大小为5
Docker构建与运行Next.js应用的指南
资源摘要信息:"rivoltafilippo-next-main"
在探讨“rivoltafilippo-next-main”这一资源时,首先要从标题“rivoltafilippo-next”入手。这个标题可能是某一项目、代码库或应用的命名,结合描述中提到的Docker构建和运行命令,我们可以推断这是一个基于Docker的Node.js应用,特别是使用了Next.js框架的项目。Next.js是一个流行的React框架,用于服务器端渲染和静态网站生成。
描述部分提供了构建和运行基于Docker的Next.js应用的具体命令:
1. `docker build`命令用于创建一个新的Docker镜像。在构建镜像的过程中,开发者可以定义Dockerfile文件,该文件是一个文本文件,包含了创建Docker镜像所需的指令集。通过使用`-t`参数,用户可以为生成的镜像指定一个标签,这里的标签是`my-next-js-app`,意味着构建的镜像将被标记为`my-next-js-app`,方便后续的识别和引用。
2. `docker run`命令则用于运行一个Docker容器,即基于镜像启动一个实例。在这个命令中,`-p 3000:3000`参数指示Docker将容器内的3000端口映射到宿主机的3000端口,这样做通常是为了让宿主机能够访问容器内运行的应用。`my-next-js-app`是容器运行时使用的镜像名称,这个名称应该与构建时指定的标签一致。
最后,我们注意到资源包含了“TypeScript”这一标签,这表明项目可能使用了TypeScript语言。TypeScript是JavaScript的一个超集,它添加了静态类型定义的特性,能够帮助开发者更容易地维护和扩展代码,尤其是在大型项目中。
结合资源名称“rivoltafilippo-next-main”,我们可以推测这是项目的主目录或主仓库。通常情况下,开发者会将项目的源代码、配置文件、构建脚本等放在一个主要的目录中,这个目录通常命名为“main”或“src”等,以便于管理和维护。
综上所述,我们可以总结出以下几个重要的知识点:
- Docker容器和镜像的概念以及它们之间的关系:Docker镜像是静态的只读模板,而Docker容器是从镜像实例化的动态运行环境。
- `docker build`命令的使用方法和作用:这个命令用于创建新的Docker镜像,通常需要一个Dockerfile来指定构建的指令和环境。
- `docker run`命令的使用方法和作用:该命令用于根据镜像启动一个或多个容器实例,并可指定端口映射等运行参数。
- Next.js框架的特点:Next.js是一个支持服务器端渲染和静态网站生成的React框架,适合构建现代的Web应用。
- TypeScript的作用和优势:TypeScript是JavaScript的一个超集,它提供了静态类型检查等特性,有助于提高代码质量和可维护性。
- 项目资源命名习惯:通常项目会有一个主目录,用来存放项目的源代码和核心配置文件,以便于项目的版本控制和团队协作。
以上内容基于给定的信息进行了深入的分析,为理解该项目的构建、运行方式以及技术栈提供了基础。在实际开发中,开发者应当参考更详细的文档和指南,以更高效地管理和部署基于Docker和TypeScript的Next.js项目。