提供一份判断异常数据功能需求
时间: 2023-09-29 07:05:53 浏览: 51
当提供异常数据判断功能时,有以下需求:
1. 数据输入:系统应支持从多种数据源中导入数据,包括文件、数据库、API等。用户应能够指定数据源并提供必要的连接信息。
2. 数据预处理:系统应提供数据预处理功能,包括数据清洗、去重、缺失值处理等。这将确保输入数据的质量和一致性。
3. 异常检测算法:系统应集成多种异常检测算法,例如统计方法(如均值、标准差)、聚类方法(如离群点检测)、机器学习方法(如异常检测模型)等。用户应能够选择适合其数据类型和需求的算法。
4. 自定义规则:系统应允许用户定义自己的异常检测规则。用户可以基于业务经验或特定需求,设置自定义的阈值或条件。
5. 可视化分析:系统应提供可视化分析功能,以便用户能够直观地观察和分析异常数据。这包括绘制图表、生成报告等功能,以便用户能够更好地理解异常数据的分布和趋势。
6. 异常报警与通知:系统应能够及时发现异常数据,并通过邮件、短信、推送通知等方式及时通知相关人员。这有助于用户能够快速采取措施处理异常情况。
7. 异常数据处理:系统应提供异常数据处理功能,例如自动剔除异常数据、标记异常数据、生成异常报告等。用户可以根据具体情况选择合适的处理方式。
8. 安全和隐私:系统应确保异常数据的安全性和隐私性,采取合适的安全措施,例如数据加密、权限控制等,以保护用户数据的安全。
9. 可扩展性:系统应具备良好的可扩展性,能够适应不同规模和复杂度的数据集。同时,系统应易于集成和部署,以便用户能够方便地使用该功能。
以上是判断异常数据功能的一些基本需求,具体需求可能会根据实际场景和用户需求而有所不同。
相关问题
编写一份流程引擎需求功能能点
当然,下面是一份流程引擎的需求功能点清单:
1. 流程设计与编辑功能:提供可视化的界面,支持创建、编辑和删除流程图,包括节点的添加、移动和连接,以及条件和规则的配置。
2. 节点库:提供丰富的节点库,包括开始节点、结束节点、任务节点、决策节点等常见节点,同时支持自定义节点的创建和导入。
3. 条件判断与规则引擎:支持根据条件判断执行路径,提供强大的条件判断和规则引擎,以便根据不同的条件执行相应的操作。
4. 并发与并行处理:能够处理并发执行的流程,支持并行执行多个子流程,提高流程执行效率。
5. 异常处理与回滚机制:具备异常处理机制,能够处理节点执行失败或异常情况,并支持回滚到合适的状态,确保流程的正确执行。
6. 监控与日志功能:提供监控和日志功能,记录流程执行过程中的关键信息,并支持实时监控流程的执行状态。
7. 定时任务与提醒功能:支持定时触发任务节点,以及发送邮件、短信等提醒功能,确保流程按时执行并及时通知相关人员。
8. 安全与权限控制:具备安全机制,支持对流程进行权限控制,确保数据和流程的安全性,同时提供用户管理和角色管理功能。
9. 集成与扩展能力:具备良好的集成能力,能够与其他系统或服务进行集成,支持自定义插件或扩展机制,以满足特定的业务需求。
10. 性能与扩展性:具备高性能和可扩展性,能够处理大规模的流程并发执行,并支持水平扩展,以应对不断增长的业务需求。
请注意,这只是一个示例的功能点清单,你可以根据实际需求进行调整和补充。
写一个代码。代码要能提供以下几个基本功能。 (1)考勤数据是由多条数据记录构成,其信息包括:学号(唯一)、姓名、班级、考勤日期(由月和日组成)等等。 (2)数据保存形式:所有信息要以文本或二进制文件保存。 (3)需要实现的功能 a 新增学生信息数据(避免重复记录,若在,不可再增加)。 b 查找数据(可按学号、姓名、考勤日期等查找)。 c 修改学生记录(可以先查找,再修改)。 d 删除学生记录(请参考上面修改的处理)。 e 显示学生考勤数据列表(可显示部分或全部)。 f 排序(可按学号、姓名、考勤日期等排序)。 g 数据统计(对考勤数据统计分析,统计完成后,可以通过考勤系统中得出考勤明细表,考勤日报表、考勤汇总表、考勤异常表,请假汇总表等)。 h 保存数据到文件中并从文件中读入数据。 (4)界面功能要求: 1) 采用友好的界面,实现一个功能控制菜单。 2) 每次操作都从该菜单选择,利用循环结构使得一次运行程序可进行多次操作。 备注: (1)数据完整性保证。例如:学号和姓名必须严格、规范。 (2)要求报表格式灵活、形式多样、内容清楚,具体请学生自己构思、设计。 (3)考勤符号:出 勤√ 旷 课 X 事 假 △ 病 假 ○ 迟 到 + 早 退 – (4)考勤时间段不少于十条。
由于这是一个较为复杂的项目,我将提供一份 Python 代码的框架,以便您进行参考和修改。请注意,这只是一个示例代码,具体实现可能因需求而异,您可以根据自己的需要进行修改和完善。
```python
import pickle # 用于序列化数据
class Student:
def __init__(self, id, name, cls):
self.id = id
self.name = name
self.cls = cls
self.attendance = {} # 考勤记录以字典形式保存
def add_attendance(self, date, status):
self.attendance[date] = status
def get_attendance(self):
return self.attendance
class AttendanceSystem:
def __init__(self):
self.students = []
self.file_name = "data.pkl" # 数据保存文件名
def add_student(self, id, name, cls):
# 判断学生是否已存在
for s in self.students:
if s.id == id:
print("该学生已存在!")
return False
# 添加新学生
self.students.append(Student(id, name, cls))
return True
def search(self, keyword):
result = []
for s in self.students:
if keyword in s.id or keyword in s.name:
result.append(s)
return result
def modify(self, id, date, status):
for s in self.students:
if s.id == id:
s.add_attendance(date, status)
return True
print("未找到该学生!")
return False
def delete(self, id):
for s in self.students:
if s.id == id:
self.students.remove(s)
return True
print("未找到该学生!")
return False
def sort(self, key):
self.students.sort(key=lambda s: getattr(s, key))
return self.students
def save(self):
with open(self.file_name, "wb") as f:
pickle.dump(self.students, f)
def load(self):
try:
with open(self.file_name, "rb") as f:
self.students = pickle.load(f)
except FileNotFoundError:
print("未找到数据文件!")
# 界面代码可以使用 PyQT、Tkinter 等工具包进行实现
# 这里只提供一个命令行界面的示例
def main():
system = AttendanceSystem()
while True:
print("请选择操作:")
print("1. 新增学生信息")
print("2. 查找学生信息")
print("3. 修改学生考勤记录")
print("4. 删除学生信息")
print("5. 显示学生考勤数据列表")
print("6. 排序")
print("7. 数据统计")
print("8. 保存数据")
print("9. 读取数据")
print("0. 退出程序")
choice = input("请输入操作编号:")
if choice == "1":
id = input("请输入学号:")
name = input("请输入姓名:")
cls = input("请输入班级:")
if system.add_student(id, name, cls):
print("添加成功!")
else:
print("添加失败!")
elif choice == "2":
keyword = input("请输入关键字:")
result = system.search(keyword)
if len(result) == 0:
print("未找到匹配的学生信息!")
else:
for s in result:
print("学号:{},姓名:{},班级:{}".format(s.id, s.name, s.cls))
elif choice == "3":
id = input("请输入学号:")
date = input("请输入考勤日期:")
status = input("请输入考勤状态:")
if system.modify(id, date, status):
print("修改成功!")
else:
print("修改失败!")
elif choice == "4":
id = input("请输入学号:")
if system.delete(id):
print("删除成功!")
else:
print("删除失败!")
elif choice == "5":
for s in system.students:
print("学号:{},姓名:{},班级:{}".format(s.id, s.name, s.cls))
attendance = s.get_attendance()
for date, status in attendance.items():
print("日期:{},状态:{}".format(date, status))
elif choice == "6":
key = input("请输入排序关键字(id、name、cls):")
result = system.sort(key)
for s in result:
print("学号:{},姓名:{},班级:{}".format(s.id, s.name, s.cls))
elif choice == "7":
# 数据统计代码
pass
elif choice == "8":
system.save()
print("数据保存成功!")
elif choice == "9":
system.load()
print("数据读取成功!")
elif choice == "0":
break
else:
print("无效的操作!")
if __name__ == "__main__":
main()
```
请注意,在这个示例代码中,数据存储方式是使用 pickle 序列化数据并保存到二进制文件中。如果您需要使用其他的存储方式(例如文本文件、数据库等),请根据自己的需要进行修改。
阅读全文
相关推荐
最新推荐
250个shell脚本
3. MySQL数据库备份:脚本提供了两种备份策略,一种是对所有数据库进行一次完整备份,另一种是按数据库-表结构进行逐个备份。这涉及到mysqldump命令的使用,以及Shell脚本的循环控制,确保数据的安全和可恢复性。 4...
Android之有效防止按钮多次重复点击的方法(必看篇)
在Android应用中,当用户点击按钮时,如果不加以限制,可能会在短时间内连续触发多次点击事件,这可能导致后台服务的并发问题,比如多次提交同一份数据,或者在等待服务器响应的过程中引发不必要的操作。为了解决这...
ARC CPU 编程手册
《ARCv2 ISA程序员参考公共版手册》是针对ARC EM处理器的一份详细指南,由Synopsys公司出版。这份文档旨在帮助那些使用ARCv2指令集架构(ISA)的程序员理解和编程。ARCv2 ISA是一种包含基本功能集合以及一系列可选...
1-DDI0487A_a_2_armv8_arm_arch_reference_manual.pdf
《ARMv8体系结构参考手册》是ARM公司发布的一份技术文档,主要针对ARMv8-A架构进行详尽的描述,适用于飞腾和鲲鹏等基于ARM架构的CPU的学习和研究。该手册属于ARM的datasheet系列,是理解、开发和优化基于ARMv8架构...
JAVA 实现ATM模拟系统
9. **静态变量与静态块**:`bankName`和`allNum`是静态变量,意味着它们属于类而不是对象,所有用户共享同一份数据。`static`块在类加载时执行,用于打印欢迎信息。 这个ATM模拟系统展示了Java语言在构建面向对象...
AA4MM开源软件:多建模与模拟耦合工具介绍
资源摘要信息:"AA4MM-开源"
知识点:
1. AA4MM概述: AA4MM是一种开源工具,专门用于多建模和模拟耦合。它利用代理(Agent)和人工制品(Artifact)的概念来进行复杂的模拟任务。
2. 开源软件介绍: 开源软件是指源代码可以被公众访问的软件,任何人都可以使用、修改和分发这些软件。开源软件的优势在于其透明性、可定制性和社区支持。
3. 多建模和模拟耦合: 多建模是指使用多种模型来描述和预测一个复杂系统的行为,而模拟耦合则是将这些模型链接起来,以便它们可以协同工作,提供更准确的模拟结果。
4. 代理和人工制品: 在多建模和模拟中,代理通常指具有自主行为能力的个体,可以是实体或者软件中模拟的抽象对象。人工制品则是代理活动的产物,比如软件、数据文件等。
5. AA4MM的应用: AA4MM可能被应用于多个领域,如生态学、社会学、经济学、城市规划等,以理解和预测系统的复杂行为。
6. AA4MM软件包文件: AA4MM软件包可能包含多个文件,以支持其功能。例如,AA4MMDemo.jar可能是一个演示AA4MM功能的可执行JAR文件,而netlogo_models可能包含了NetLogo模型文件,NetLogo是一种用于模拟自然和社会现象的多主体编程语言和平台。
7. 技术栈和依赖: 由于AA4MM可能使用Java作为编程语言(因为存在JAR文件),了解Java技术栈对于理解和使用AA4MM至关重要。此外,如果AA4MM依赖于特定的库或框架,那么对这些技术的了解也是必须的。
8. 社区和资源: 开源软件通常拥有活跃的社区,社区成员互相协助、分享知识和资源。对于AA4MM而言,这意味着用户可以找到相关的文档、教程、示例项目以及如何参与该项目贡献的指南。
9. 许可证和合规性: 使用开源软件时,了解其许可证条款至关重要,以确保合法合规地使用该软件。AA4MM作为开源软件,用户需要确认其遵循的是哪种开源许可证(如GPL、MIT、Apache等)。
10. 安装和配置: 使用AA4MM前,用户可能需要进行安装和配置。这可能涉及到设置环境变量、安装依赖软件包以及进行初始的软件设置。
11. 排错和优化: 在使用AA4MM时,用户可能会遇到一些问题,此时需要能够进行有效的排错。此外,为了提高模拟的效率和准确性,可能需要对软件进行性能优化。
12. 培训和学习: 对于不熟悉多建模和模拟耦合的用户来说,可能需要通过在线课程、研讨会或阅读相关文献来提升自己的技能。
综上所述,AA4MM作为一款开源多建模和模拟耦合工具,具备强大的功能和灵活性,能够应用于多个学科领域中进行复杂系统的模拟与分析。对于技术开发者和科研人员来说,掌握相关的知识点和技术细节,将有助于更高效地利用AA4MM进行研究和开发工作。同时,由于其开源特性,用户还可以参与到项目的开发中,为改进和推广该工具贡献力量。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
HDFS写入超时问题:深入分析与专家提供的10大解决策略
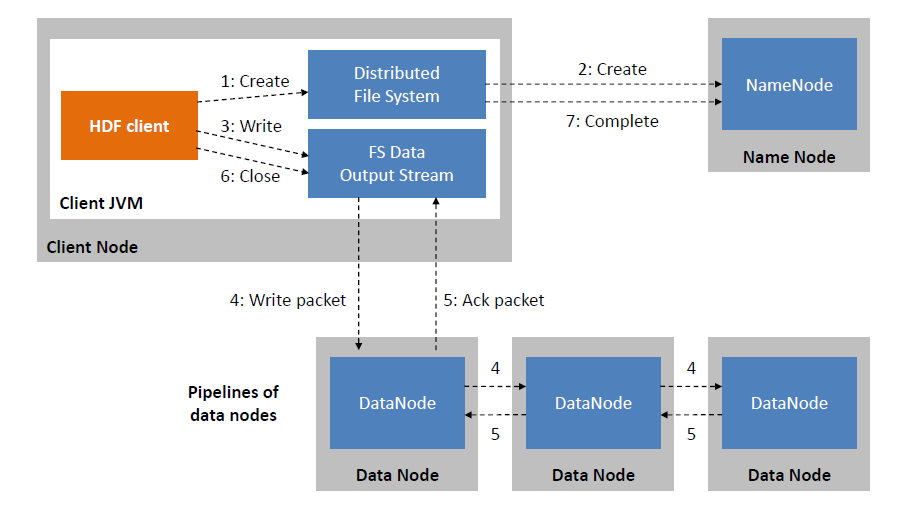
# 1. HDFS写入超时问题概述
## 1.1 HDFS写入超时问题简介
Hadoop分布式文件系统(HDFS)作为大数据生态中存储的核心组件,为大规模数据处理提供了高效支持。然而,在实际应用过程中,用户常遇到写入超时的问题,这会导致数据完整性受损、计算任务失败,甚至业务中断。本文将探讨HDFS写入超时问题,以帮助用户快速定位并解决相关问题。
## 1.2 超时问题的影响
在数据密集型应用中,
如何利用STLINK调试器和WCHISPTool工具将CH32F103C8T6微控制器进行USB下载操作?
为了有效地将CH32F103C8T6微控制器与STLINK调试器配合使用进行程序下载,你需要按照以下步骤操作并注意相应的细节:(步骤、代码、mermaid流程图、扩展内容,此处略)
参考资源链接:[CH32F103C8T6芯片下载教程:STLINK与USB方式](https://wenku.csdn.net/doc/15zenzvboq)
首先,在Keil uVision环境中配置项目以使用STLINK调试器。确保你已经安装了正确的设备支持包`Keil.WCH32F1xx_DFP.1.0.0.pack`,这样软件才能识别CH32F103C8T6微控制器。在项目设置中选择目标设备,配
Swagger实时生成器的探索与应用
资源摘要信息:"Swagger Generator 实时API文档生成工具"
Swagger是一种用于描述、生产和消费RESTful Web服务的接口描述语言,它提供了一套强大的工具集来生成交互式API文档,用于API的设计、测试和文档生成。"swagger-generator-realti"(即Swagger Generator 实时API文档生成工具)是一个专注于通过实时信息来自动化生成API文档的工具。
知识点详细说明:
1. Swagger的定义与作用:
- Swagger是一种规范和完整的框架,用于描述API的结构,使得开发者能够清晰地理解和使用API。
- 它通过一套简洁的接口描述语言(OpenAPI Specification,原名Swagger Specification),来定义API接口的标准语言和结构。
-Swagger工具集包括Swagger Editor(在线编辑器)、Swagger UI(文档展示界面)、Swagger Codegen(代码生成器)等,可以用来设计API、生成API文档、以及客户端和服务端的代码。
2. 实时API文档的概念:
- 实时API文档意味着文档能够即时反映API的最新状态和变更。
- 这种文档能够帮助开发者在API开发和维护过程中,及时了解API的结构、参数、调用示例等信息。
- 实时API文档对于团队协作和API的使用者来说非常有价值,能够减少因文档更新滞后导致的误解和错误。
3. Swagger Generator的功能:
-Swagger Generator通过解析API的规范文件(通常是JSON或YAML格式),自动地生成结构化、可交互的API文档。
-它支持多种编程语言和框架,可以通过简单的配置,生成对应的客户端和服务端代码,极大地提高了开发效率。
-该工具可以集成到持续集成和持续部署(CI/CD)的流程中,确保文档和API的同步更新。
4. Swagger Generator的实时性:
-Swagger Generator实时性强调的是对于API变动的快速响应和文档的即时更新。
-通过集成到API的开发和部署流程中,Swagger Generator可以在API发布后迅速更新文档,减少文档与实际API之间的差异。
-实时API文档不仅减少了开发者查看和理解API所需的维护成本,还能够提升API的可用性和可靠性。
5. 标签说明:
- "swagger_generato"标签指向与Swagger工具相关的生成器,这可以是Swagger Codegen或任何类似的工具,用于生成代码、文档等资源。
6. 文件名称列表解析:
- "swagger_generator_realtime"文件名称暗示了这是一个专注于实时API文档生成的Swagger相关工具或插件。
- 名称中的"realtime"可能表明工具具有实时监控API变更并自动更新文档的能力。
Swagger Generator的实时API文档生成能力,对于API的高效管理和维护提供了重要的支持,极大地提升了API文档的准确性和时效性。开发团队通过使用这样的工具可以更加快速和准确地进行API的设计、开发、测试和文档维护工作,从而提高整个API生态系统的质量。