idea运行时出现Could not create the Java Virtual Machine
时间: 2024-08-15 08:04:04 浏览: 71
当你尝试使用IntelliJ IDEA(一种集成开发环境,IDEA)启动项目时,如果遇到"Could not create the Java Virtual Machine"这样的错误,通常意味着IDEA无法找到有效的Java运行环境或者是JVM(Java Virtual Machine,Java虚拟机)配置出现问题。这可能是以下几个原因:
1. **Java路径未设置**:检查`JAVA_HOME`环境变量是否指向正确的Java安装目录,且该目录下的`bin`文件夹不在系统路径中。
2. **JDK版本冲突**:有时候电脑上可能同时安装了多个JDK版本,IDEA需要明确指定使用的JDK版本。确认IDEA中配置的是你想要运行项目的JDK。
3. **JVM内存不足**:检查`idea.exe.vmoptions`(Windows)或`idea64.exe.vmoptions`(Mac/Linux)文件中的内存分配,确保有足够的堆内存(-Xmx)给IDEA使用。
4. **IDEA自身问题**:有时候IDEA的内部组件可能会损坏,可以尝试卸载并重新安装IntelliJ IDEA。
5. **兼容性问题**:如果是在新版本的IDEA中运行老项目,可能存在版本不兼容的情况。
解决这个问题通常需要定位具体原因然后针对性地调整。你可以按照上述步骤排查,如果还是不能解决问题,可以尝试重启计算机,或者寻求官方文档或社区的帮助。
相关问题
idea Error: Could not create the Java Virtual Machine.
当在IntelliJ IDEA中遇到 "Error: Could not create the Java Virtual Machine" 这样的错误时,通常意味着IDEA无法找到或启动Java虚拟机(JVM)。这可能是由于以下几个原因:
1. **JDK路径不正确**:确保IntelliJ IDEA配置的JDK路径是正确的,并且JDK已安装且添加到系统环境变量中。
2. **JVM版本问题**:如果IDEA与系统的JDK版本不匹配,可能需要更新或回滚到兼容的JDK版本。
3. **JVM路径问题**:检查IDEA的配置文件(如`idea64.exe.vmoptions`),确认JVM的绝对路径没有误写。
4. **内存限制**:确保IDEA或JVM有足够的内存可用,如果内存设置过低,可能会导致JVM启动失败。
5. **IDEA缓存问题**:尝试清理IntelliJ IDEA的缓存和日志文件,有时候这些文件的损坏可能导致启动问题。
6. **第三方插件冲突**:某些插件可能会与JVM产生冲突,尝试禁用或卸载它们,看看问题是否解决。
7. **操作系统问题**:在某些情况下,操作系统的问题,如防火墙阻止或安全软件干扰也可能导致此错误。
为了解决这个问题,请按照以下步骤进行排查:
1. **检查JDK路径**:在IDEA的设置中确认JDK路径是否正确。
2. **重启IDEA并重试**:有时简单的重启可能会解决问题。
3. **更新或降级JDK**:确保使用的JDK版本与IDEA兼容。
4. **修改IDEA配置**:编辑IDEA配置文件,确保JVM路径和内存设置正确。
5. **清理缓存**:尝试清理IntelliJ IDEA的本地目录(`%APPDATA%\IntelliJIdeaXX`)下的缓存文件。
6. **排查第三方插件**:禁用或卸载最近安装的插件,看看是否有帮助。
如果你需要更详细的帮助,提供更多信息(例如你的操作系统、IDEA版本、JDK版本等)将有助于找到解决方案。
运行项目IDEA报 Could not create the Java Virtual Machine问题解决
您好!对于 "Could not create the Java Virtual Machine" 错误,有几种可能的解决方法:
1. 增加JVM堆内存:在运行项目之前,您可以尝试增加JVM堆内存的大小。在您的项目的启动配置中,找到 "VM options" 或 "JVM arguments",并添加以下参数:-Xmx512m(或其他大于默认值的数值)。这将增加JVM的最大堆内存大小。
2. 检查JAVA_HOME 变量:确保您的JAVA_HOME环境变量已正确配置。您可以在命令行中运行 "echo %JAVA_HOME%"(Windows)或 "echo $JAVA_HOME"(Linux/macOS)来验证。
3. 检查项目依赖:确保您的项目依赖项正确配置,并且所需的Java版本与您的项目要求的Java版本一致。如果依赖项存在冲突,可能会导致JVM无法创建。
4. 更新Java版本:尝试升级您的Java版本到最新稳定版本。有时,旧版Java可能存在某些问题,通过升级到最新版本可以解决问题。
5. 检查系统资源:如果您的计算机内存不足,可能无法创建足够大的Java虚拟机。请确保您的计算机具有足够的可用内存来运行Java应用程序。
如果上述解决方法都无效,还请提供更多详细信息,例如您使用的操作系统、Java版本、IDEA版本等,以便更好地帮助您解决问题。
相关推荐
最新推荐
Google C++ Style Guide(Google C++编程规范)高清PDF
For example, if your header file uses the File class in ways that do not require access to the declaration of the File class, your header file can just forward declare class File; instead of having ...
微软内部资料-SQL性能优化2
By leveraging the Address Windowing Extensions API, an application can create a fixed-size window into the additional physical memory. This allows a process to access any portion of the physical ...
java基于SpringBoot+vue 美食信息推荐系统源码 带毕业论文
1、开发环境:SpringBoot框架;内含Mysql数据库;VUE技术;内含说明文档
2、需要项目部署的可以私信
3、项目代码都经过严格调试,代码没有任何bug!
4、该资源包括项目的全部源码,下载可以直接使用!
5、本项目适合作为计算机、数学、电子信息等专业的课程设计、期末大作业和毕设项目,作为参考资料学习借鉴。
6、本资源作为“参考资料”如果需要实现其他功能,需要能看懂代码,并且热爱钻研,自行调试。
Sigrity-SystemSI-Statistical Analysis Application Note.rar
Sigrity-SystemSI-Statistical Analysis Application Note.rar
介绍
Sigrity SystemSI-串行链路分析中使用的传统分析流程涉及
基于高级卷积信道的信道电路冲激响应
并在接收器处导出时域波形。这些波形是
经过统计后处理,生成眼图、浴缸曲线和其他输出。
通过信道运行的比特数越多,结果就越准确。
统计分析通常适用于线性时不变(LTI)系统。a中的线性
系统指示叠加适用。时间不变性表明,对于具有
x(t)输入和y(t)输出,输入中的时移z,例如x(t+z)将导致
对应的时移输出y(t+z)。许多(尽管不是全部)串行链路系统可以近似为LTI,因此统计分析是串行链路分析工具箱中一种有用的功能。
与时域仿真方法相比,纯统计分析的主要优点是可以直接考虑所有符号间干扰(ISI)。
因此,它的准确性不依赖于模拟的比特数,就像传统的时域方法一样。
统计分析的主要局限性是它只适用于LTI系统。
使用AMI_GetWave函数执行实时波形处理的算法(AMI)模型不能保证LTI操作。
许多使用Decision的多千兆位接收器
反馈均衡(DFE)使
MATLAB的汉字定位检测识别系统GUI设计.zip
产品经理项目实战案例
最优条件下三次B样条小波边缘检测算子研究
"这篇文档是关于B样条小波在边缘检测中的应用,特别是基于最优条件的三次B样条小波多尺度边缘检测算子的介绍。文档涉及到图像处理、计算机视觉、小波分析和优化理论等多个IT领域的知识点。"
在图像处理中,边缘检测是一项至关重要的任务,因为它能提取出图像的主要特征。Canny算子是一种经典且广泛使用的边缘检测算法,但它并未考虑最优滤波器的概念。本文档提出了一个新的方法,即基于三次B样条小波的边缘提取算子,该算子通过构建目标函数来寻找最优滤波器系数,从而实现更精确的边缘检测。
小波分析是一种强大的数学工具,它能够同时在时域和频域中分析信号,被誉为数学中的"显微镜"。B样条小波是小波家族中的一种,尤其适合于图像处理和信号分析,因为它们具有良好的局部化性质和连续性。三次B样条小波在边缘检测中表现出色,其一阶导数可以用来检测小波变换的局部极大值,这些极大值往往对应于图像的边缘。
文档中提到了Canny算子的三个最优边缘检测准则,包括低虚假响应率、高边缘检测概率以及单像素宽的边缘。作者在此基础上构建了一个目标函数,该函数考虑了这些准则,以找到一组最优的滤波器系数。这些系数与三次B样条函数构成的线性组合形成最优边缘检测算子,能够在不同尺度上有效地检测图像边缘。
实验结果表明,基于最优条件的三次B样条小波边缘检测算子在性能上优于传统的Canny算子,这意味着它可能提供更准确、更稳定的边缘检测结果,这对于计算机视觉、图像分析以及其他依赖边缘信息的领域有着显著的优势。
此外,文档还提到了小波变换的定义,包括尺度函数和小波函数的概念,以及它们如何通过伸缩和平移操作来适应不同的分析需求。稳定性条件和重构小波的概念也得到了讨论,这些都是理解小波分析基础的重要组成部分。
这篇文档深入探讨了如何利用优化理论和三次B样条小波改进边缘检测技术,对于从事图像处理、信号分析和相关研究的IT专业人士来说,是一份极具价值的学习资料。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
递归阶乘速成:从基础到高级的9个优化策略
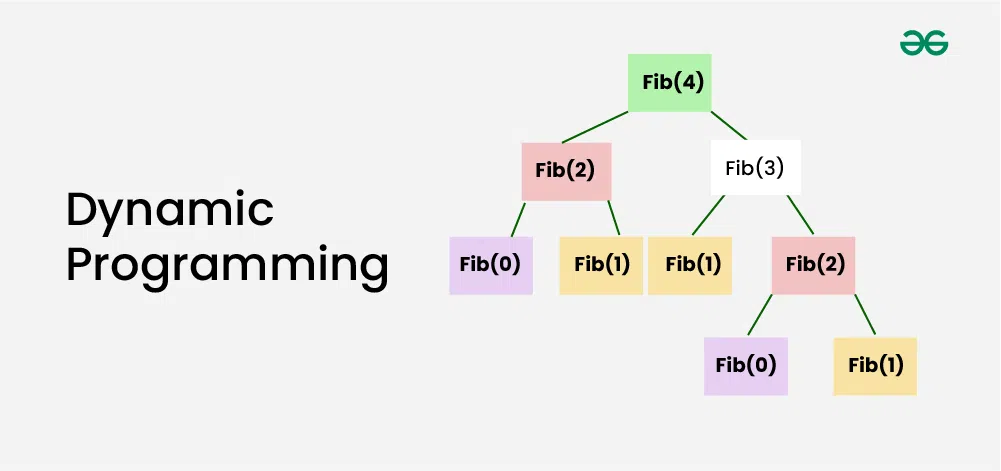
# 1. 递归阶乘算法的基本概念
在计算机科学中,递归是一种常见的编程技巧,用于解决可以分解为相似子问题的问题。阶乘函数是递归应用中的一个典型示例,它计算一个非负整数的阶乘,即该数以下所有正整数的乘积。阶乘通常用符号"!"表示,例如5的阶乘写作5! = 5 * 4 * 3 * 2 * 1。通过递归,我们可以将较大数的阶乘计算简化为更小数的阶乘计算,直到达到基本情况
pcl库在CMakeLists。txt配置
PCL (Point Cloud Library) 是一个用于处理点云数据的开源计算机视觉库,常用于机器人、三维重建等应用。在 CMakeLists.txt 文件中配置 PCL 需要以下步骤:
1. **添加找到包依赖**:
在 CMakeLists.txt 的顶部,你需要找到并包含 PCL 的 CMake 找包模块。例如:
```cmake
find_package(PCL REQUIRED)
```
2. **指定链接目标**:
如果你打算在你的项目中使用 PCL,你需要告诉 CMake 你需要哪些特定组件。例如,如果你需要 PointCloud 和 vi
深入解析:wav文件格式结构
"该文主要深入解析了wav文件格式,详细介绍了其基于RIFF标准的结构以及包含的Chunk组成。"
在多媒体领域,WAV文件格式是一种广泛使用的未压缩音频文件格式,它的基础是Resource Interchange File Format (RIFF) 标准。RIFF是一种块(Chunk)结构的数据存储格式,通过将数据分为不同的部分来组织文件内容。每个WAV文件由几个关键的Chunk组成,这些Chunk共同定义了音频数据的特性。
1. RIFFWAVE Chunk
RIFFWAVE Chunk是文件的起始部分,其前四个字节标识为"RIFF",紧接着的四个字节表示整个Chunk(不包括"RIFF"和Size字段)的大小。接着是'RiffType',在这个情况下是"WAVE",表明这是一个WAV文件。这个Chunk的作用是确认文件的整体类型。
2. Format Chunk
Format Chunk标识为"fmt",是WAV文件中至关重要的部分,因为它包含了音频数据的格式信息。例如,采样率、位深度、通道数等都在这个Chunk中定义。这些参数决定了音频的质量和大小。Format Chunk通常包括以下子字段:
- Audio Format:2字节,表示音频编码格式,如PCM(无损)或压缩格式。
- Num Channels:2字节,表示音频的声道数,如单声道(1)或立体声(2)。
- Sample Rate:4字节,表示每秒的样本数,如44100 Hz。
- Byte Rate:4字节,每秒音频数据的字节数,等于Sample Rate乘以Bits Per Sample和Num Channels。
- Block Align:2字节,每个样本数据的字节数,等于Bits Per Sample除以8乘以Num Channels。
- Bits Per Sample:2字节,每个样本的位深度,影响声音质量和文件大小。
3. Fact Chunk(可选)
Fact Chunk标识为'fact',虽然不是所有WAV文件都包含此Chunk,但它提供了额外的样本信息,如实际的样本数,对于非整数倍采样率的文件尤其有用。
4. Data Chunk
Data Chunk标识为'data',是WAV文件中真正包含音频样本数据的部分。其ID后面是4字节的Size字段,表示数据区域的大小,不包括ID和Size本身。这个Chunk的内容就是连续的音频样本值,根据Format Chunk定义的格式进行编码。
所有Chunk的大小字段都是以低字节在前,高字节在后的顺序存储,这是遵循了RIFF格式的规定。理解这些Chunk的结构和内容对于处理和分析WAV文件至关重要,无论是编程处理音频数据还是进行音频文件的转换和编辑。