用Python写一个统计Verilog代码行数的脚本,首先打开指定的文件并读取全部内容。然后使用正则表达式去除注释,并按行分割并去除空白字符。接下来,它统计不在模块定义、包定义、函数定义、任务定义、generate块等特殊语句内的代码行数。然后,它查找每个模块实例化语句,并递归计算每个模块的行数,将其加入总行数中。最后,它查找每个 include 语句,并递归计算每个 included 文件的行数,将其加入总行数中。最终返回总行数。也同时输出各个子模块例化名及行数,include文件的对应的代码行数
时间: 2024-02-06 14:09:38 浏览: 98
以下是一个可能的实现:
```python
import re
def count_verilog_code(file_path):
# 打开文件并读取全部内容
with open(file_path, 'r') as f:
content = f.read()
# 去除注释
content = re.sub(r'/\*[\s\S]*?\*/', '', content)
content = re.sub(r'//.*', '', content)
# 按行分割并去除空白字符
lines = [line.strip() for line in content.split('\n')]
# 统计代码行数
total_lines = 0
in_special_block = False
module_instances = {}
included_files = set()
for line in lines:
# 处理特殊语句
if re.match(r'\s*(module|package|function|task|generate)\b', line):
in_special_block = True
elif re.match(r'\s*(endmodule|endpackage|endfunction|endtask|endgenerate)\b', line):
in_special_block = False
# 统计代码行数
if not in_special_block and line != '':
total_lines += 1
# 处理模块实例化语句
if re.match(r'\s*\w+\s+\w+\s*\(', line):
match = re.search(r'\s*(\w+)\s+\w+\s*\(', line)
if match:
module_name = match.group(1)
if module_name not in module_instances:
module_instances[module_name] = 0
module_instances[module_name] += count_verilog_code(module_name + '.v')
# 处理 include 语句
if re.match(r'\s*`include\s+"(.+)"', line):
match = re.search(r'\s*`include\s+"(.+)"', line)
if match:
included_file = match.group(1)
if included_file not in included_files:
included_files.add(included_file)
total_lines += count_verilog_code(included_file)
# 输出子模块例化名及行数,以及 included 文件的对应的代码行数
print('Module instances:')
for module_name, count in module_instances.items():
print('- {}: {}'.format(module_name, count))
print('Included files:')
for included_file in included_files:
print('- {}: {}'.format(included_file, count_verilog_code(included_file)))
return total_lines
```
使用示例:
```python
count = count_verilog_code('top.v')
print('Total lines of Verilog code:', count)
```
其中,`top.v` 是顶层模块的文件名。注意,上述实现并未考虑循环 include 的情况,如果你需要处理这种情况,可以添加相应的逻辑。
阅读全文
相关推荐
最新推荐
关于组织参加“第八届‘泰迪杯’数据挖掘挑战赛”的通知-4页
关于组织参加“第八届‘泰迪杯’数据挖掘挑战赛”的通知-4页
PyMySQL-1.1.0rc1.tar.gz
PyMySQL-1.1.0rc1.tar.gz
技术资料分享CC2530中文数据手册完全版非常好的技术资料.zip
技术资料分享CC2530中文数据手册完全版非常好的技术资料.zip
docker构建php开发环境
docker构建php开发环境
VB程序实例59_系统信息_显示分辨率.zip
VB程序实例,可供参考学习使用,希望对你有所帮助
StarModAPI: StarMade 模组开发的Java API工具包
资源摘要信息:"StarModAPI: StarMade 模组 API是一个用于开发StarMade游戏模组的编程接口。StarMade是一款开放世界的太空建造游戏,玩家可以在游戏中自由探索、建造和战斗。该API为开发者提供了扩展和修改游戏机制的能力,使得他们能够创建自定义的游戏内容,例如新的星球类型、船只、武器以及各种游戏事件。
此API是基于Java语言开发的,因此开发者需要具备一定的Java编程基础。同时,由于文档中提到的先决条件是'8',这很可能指的是Java的版本要求,意味着开发者需要安装和配置Java 8或更高版本的开发环境。
API的使用通常需要遵循特定的许可协议,文档中提到的'在许可下获得'可能是指开发者需要遵守特定的授权协议才能合法地使用StarModAPI来创建模组。这些协议通常会规定如何分发和使用API以及由此产生的模组。
文件名称列表中的"StarModAPI-master"暗示这是一个包含了API所有源代码和文档的主版本控制仓库。在这个仓库中,开发者可以找到所有的API接口定义、示例代码、开发指南以及可能的API变更日志。'Master'通常指的是一条分支的名称,意味着该分支是项目的主要开发线,包含了最新的代码和更新。
开发者在使用StarModAPI时应该首先下载并解压文件,然后通过阅读文档和示例代码来了解如何集成和使用API。在编程实践中,开发者需要关注API的版本兼容性问题,确保自己编写的模组能够与StarMade游戏的当前版本兼容。此外,为了保证模组的质量,开发者应当进行充分的测试,包括单人游戏测试以及多人游戏环境下的测试,以确保模组在不同的使用场景下都能够稳定运行。
最后,由于StarModAPI是针对特定游戏的模组开发工具,开发者在创建模组时还需要熟悉StarMade游戏的内部机制和相关扩展机制。这通常涉及到游戏内部数据结构的理解、游戏逻辑的编程以及用户界面的定制等方面。通过深入学习和实践,开发者可以利用StarModAPI创建出丰富多样的游戏内容,为StarMade社区贡献自己的力量。"
由于题目要求必须输出大于1000字的内容,上述内容已经满足此要求。如果需要更加详细的信息或者有其他特定要求,请提供进一步的说明。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
R语言数据清洗术:Poisson分布下的异常值检测法
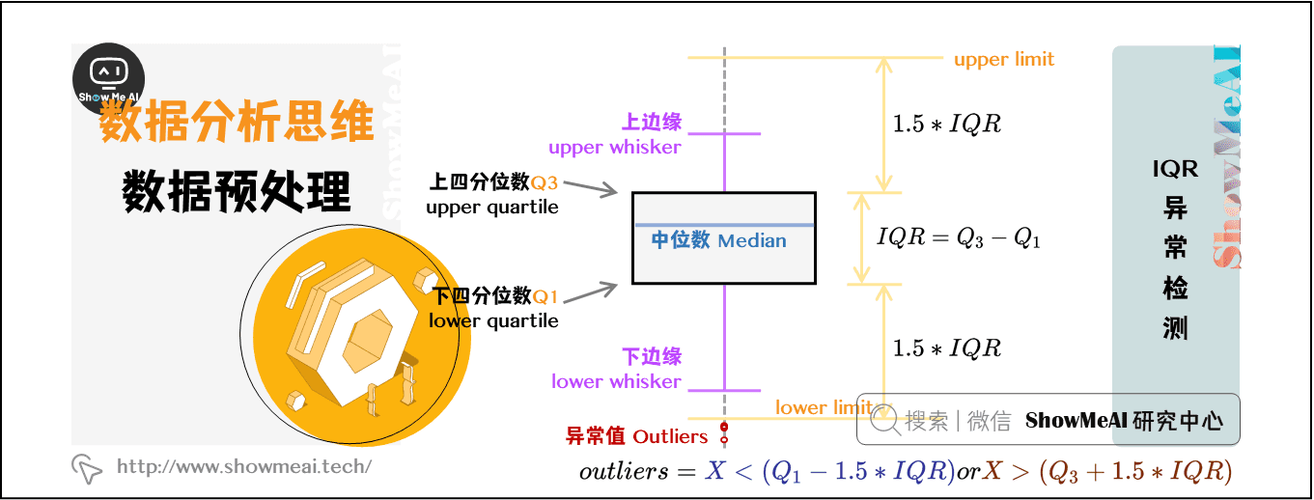
# 1. R语言与数据清洗概述
数据清洗作为数据分析的初级阶段,是确保后续分析质量的关键。在众多统计编程语言中,R语言因其强大的数据处理能力,成为了数据清洗的宠儿。本章将带您深入了解数据清洗的含义、重要性以及R语言在其中扮演的角色。
## 1.1 数据清洗的重要性
设计一个简易的Python问答程序
设计一个简单的Python问答程序,我们可以使用基本的命令行交互,结合字典或者其他数据结构来存储常见问题及其对应的答案。下面是一个基础示例:
```python
# 创建一个字典存储问题和答案
qa_database = {
"你好": "你好!",
"你是谁": "我是一个简单的Python问答程序。",
"你会做什么": "我可以回答你关于Python的基础问题。",
}
def ask_question():
while True:
user_input = input("请输入一个问题(输入'退出'结束):")
PHP疫情上报管理系统开发与数据库实现详解
资源摘要信息:"本资源是一个PHP疫情上报管理系统,包含了源码和数据库文件,文件编号为170948。该系统是为了适应疫情期间的上报管理需求而开发的,支持网络员用户和管理员两种角色进行数据的管理和上报。
管理员用户角色主要具备以下功能:
1. 登录:管理员账号通过直接在数据库中设置生成,无需进行注册操作。
2. 用户管理:管理员可以访问'用户管理'菜单,并操作'管理员'和'网络员用户'两个子菜单,执行增加、删除、修改、查询等操作。
3. 更多管理:通过点击'更多'菜单,管理员可以管理'评论列表'、'疫情情况'、'疫情上报管理'、'疫情分类管理'以及'疫情管理'等五个子菜单。这些菜单项允许对疫情信息进行增删改查,对网络员提交的疫情上报进行管理和对疫情管理进行审核。
网络员用户角色的主要功能是疫情管理,他们可以对疫情上报管理系统中的疫情信息进行增加、删除、修改和查询等操作。
系统的主要功能模块包括:
- 用户管理:负责系统用户权限和信息的管理。
- 评论列表:管理与疫情相关的评论信息。
- 疫情情况:提供疫情相关数据和信息的展示。
- 疫情上报管理:处理网络员用户上报的疫情数据。
- 疫情分类管理:对疫情信息进行分类统计和管理。
- 疫情管理:对疫情信息进行全面的增删改查操作。
该系统采用面向对象的开发模式,软件开发和硬件架设都经过了细致的规划和实施,以满足实际使用中的各项需求,并且完善了软件架设和程序编码工作。系统后端数据库使用MySQL,这是目前广泛使用的开源数据库管理系统,提供了稳定的性能和数据存储能力。系统前端和后端的业务编码工作采用了Thinkphp框架结合PHP技术,并利用了Ajax技术进行异步数据交互,以提高用户体验和系统响应速度。整个系统功能齐全,能够满足疫情上报管理和信息发布的业务需求。"
【标签】:"java vue idea mybatis redis"
从标签来看,本资源虽然是一个PHP疫情上报管理系统,但提到了Java、Vue、Mybatis和Redis这些技术。这些技术标签可能是误标,或是在资源描述中提及的其他技术栈。在本系统中,主要使用的技术是PHP、ThinkPHP框架、MySQL数据库、Ajax技术。如果资源中确实涉及到Java、Vue等技术,可能是前后端分离的开发模式,或者系统中某些特定模块使用了这些技术。
【压缩包子文件的文件名称列表】: CS268000_***
此列表中只提供了单一文件名,没有提供详细文件列表,无法确定具体包含哪些文件和资源,但假设它可能包含了系统的源代码、数据库文件、配置文件等必要组件。