




R语言数据清洗术:Poisson分布下的异常值检测法

1. R语言与数据清洗概述
数据清洗作为数据分析的初级阶段,是确保后续分析质量的关键。在众多统计编程语言中,R语言因其强大的数据处理能力,成为了数据清洗的宠儿。本章将带您深入了解数据清洗的含义、重要性以及R语言在其中扮演的角色。
1.1 数据清洗的重要性
在数据分析的流程中,数据清洗不可或缺。未经清洗的数据往往包含缺失值、异常值、重复记录等问题,这些问题可能导致分析结果出现偏差,甚至得出错误结论。因此,数据清洗的目的是为了提高数据的质量,保证数据的一致性和准确性。
1.2 R语言在数据清洗中的作用
R语言提供了丰富的数据处理包,如dplyr、tidyr、stringr等,可以高效地处理各种数据问题。R语言的脚本功能使得数据清洗的过程可重复、可自动化,极大地提高了工作效率。此外,R语言在统计分析和可视化方面的强大功能,使得它成为了数据科学家在数据清洗阶段的首选工具。
1.3 R语言数据清洗的基本步骤
数据清洗大致可以分为以下几个步骤:
- 数据导入:读取数据集,无论是从CSV、Excel还是数据库中。
- 数据探索:理解数据集的结构和内容,包括数据类型、缺失值、异常值等。
- 数据清洗:针对发现的问题进行处理,如填充缺失值、移除重复记录、转换数据格式等。
- 数据验证:确保清洗后的数据满足分析需求。
下面,我们将深入探讨R语言如何具体应用于数据清洗的各个环节。
2. 理解Poisson分布与异常值
2.1 Poisson分布的理论基础
2.1.1 Poisson分布的定义和特性
Poisson分布是一种描述在固定时间或空间内发生某事件的次数的概率分布,它属于离散概率分布的一种。其定义如下:
- 设 ( X ) 是在区间 ( (0, t) ) 内发生某事件的次数,则 ( X ) 服从参数为 ( \lambda t ) 的Poisson分布,其中 ( \lambda ) 是单位时间(或单位面积)内事件的平均发生次数,也称作事件的强度。
- Poisson分布的概率质量函数(PMF)为: [ P(X=k) = \frac{e^{-\lambda t} (\lambda t)^k}{k!} ] 其中 ( k = 0, 1, 2, \ldots ),且 ( e ) 是自然对数的底数。
Poisson分布的主要特性包括:
- ( E(X) = Var(X) = \lambda t ),即期望和方差相等且都等于平均发生次数乘以时间区间长度。
- 事件的发生是独立的,即一个事件的发生不影响另一个事件的发生概率。
Poisson分布广泛应用于描述稀有事件在固定时间或空间的次数统计,如电话呼叫中心的来电次数、交通事故发生的频次等。
2.1.2 Poisson分布的应用场景
Poisson分布的应用非常广泛,尤其适用于以下场景:
- 金融服务行业:银行处理的交易数量、ATM机的现金提取次数。
- 生物统计学:放射性物质衰变的原子数目、实验室样本中的细菌数量。
- 工业生产:一定时间内机器的故障次数。
- 交通工程:一定时间内的交通事故数量、地铁或公交车在特定站点的到站次数。
- 网络流量分析:网络请求的到达次数。 在这些场景中,Poisson分布提供了一个便捷的模型来预测和分析事件的发生频率。然而,在实际应用中,数据往往可能存在异常值,这些异常值可能对模型的准确性和可靠性产生重大影响。因此,识别和处理异常值在利用Poisson分布进行建模时显得尤为重要。
2.2 异常值的识别与分类
2.2.1 异常值的定义和产生的原因
异常值,又称离群点,是统计学中一个重要的概念。在一组数据中,那些显著偏离大多数观测值的点可被认定为异常值。它们可能是由以下原因产生的:
- 测量或数据录入错误:数据在收集、记录或转移过程中的失误导致异常值的出现。
- 数据样本不具代表性:由于抽样方法不当或样本量不足,导致收集到的数据不能代表整个研究对象的真实情况。
- 多模态数据:数据分布中有多个不同的生成过程,导致数据呈现多个峰值。
- 真实的变异:在某些情况下,异常值可能是真实且有价值的信息来源,指示着数据背后的某种特殊现象或趋势。
识别异常值对于数据科学、机器学习和统计建模来说至关重要。它们可以扭曲数据的统计特征,导致模型参数估计不准确、误导分析结果或决策制定。
2.2.2 异常值的检测方法概述
异常值的检测方法多种多样,下面列举几种常见的方法:
- 基于统计的方法:
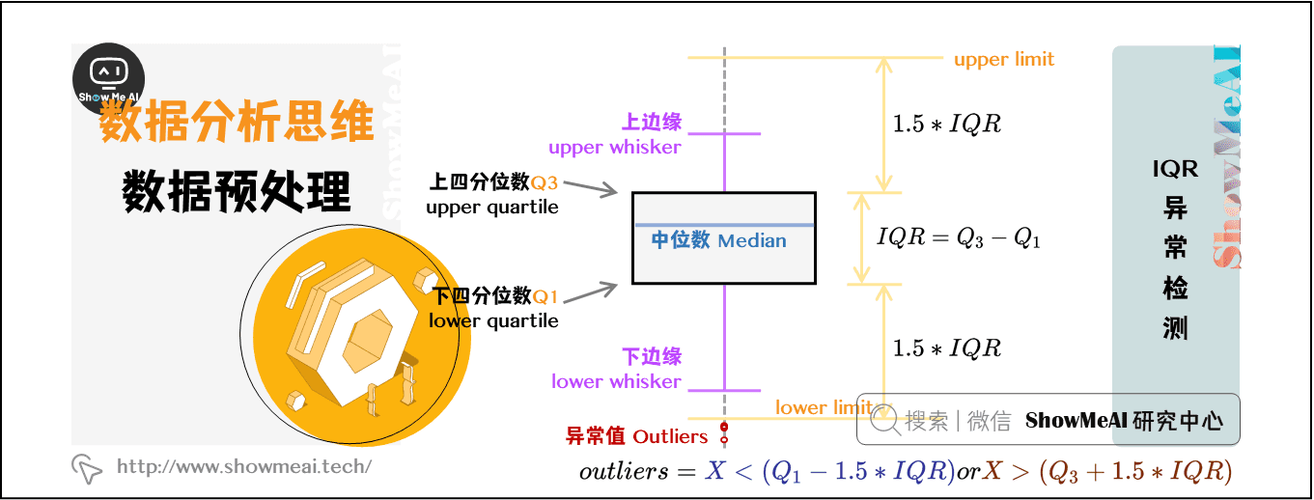
- 箱型图(Boxplot):基于四分位数的方法,任何超出箱体1.5倍四分位距(IQR)范围的值通常被视为异常值。
- Z-分数(Standard Score):通过比较数据点与数据集平均值的偏差,以标准差的倍数来表示。Z-分数高于某个阈值(如±3)的点可能是异常值。
- 基于聚类的方法:
- K-均值聚类:在K-均值聚类中,与聚类中心距离较远的点可能是异常点。
- 基于距离的方法:
- 局部异常因子(Local Outlier Factor, LOF):基于k近邻距离来评估数据点的局部密度偏差。与邻居相比密度显著小的点可能是异常值。
- 基于模型的方法:
- 高斯混合模型(Gaussian Mixture Models, GMM):通过拟合数据到多个高斯分布的组合中,识别概率密度较低的点。 每种方法都有其优缺点,需要根据数据的特性和分析目的来选择合适的方法。
2.3 Poisson分布下的异常值特征
2.3.1 为何选择Poisson分布进行异常值检测
在某些特定应用场景中,如电信呼叫中心的来电次数、交通事故发生的频率等,数据通常表现为稀有事件在固定时间或空间内的发生次数,这类数据往往服从Poisson分布。选择Poisson分布进行异常值检测的原因如下:
- 数据特点:Poisson分布特别适合于描述在固定时间或空间间隔内出现次数的随机事件。
- 模型特性:Poisson分布具有良好的数学性质,可以通过参数 ( \lambda ) 直接描述事件发生的平均频率,这使得模型容易理解和应用。
- 实际意义:在很多实际问题中,异常值可能代表重要的信息,如电信服务中的呼叫潮汐现象或交通事故高发区,因此异常值的检测和分析具有实际意义。
2.3.2 Poisson分布异常值的理论判定标准
在Poisson分布框架内,异常值的判定标准通常基于以下逻辑:
- 使用Poisson分布的期望值 ( E(X) = \lambda t ) 作为基准,任何显著偏离这个期望值的数据点都可能被认为是异常的。
- 给定显著性水平 ( \alpha ),可以计算Poisson分布的上下限值,超出这个范围的数据点可以被视为异常值。
- 由于Poisson分布的方差也等于 ( \lambda t ),在数据呈现Poisson分布特性时,可以使用 ( \lambda t \pm 3\sqrt{\lambda t} ) 的范围来界定异常值。
下面是一个简单的R语言代码示例,说明如何使用Poisson分布来识别异常值:
- # 设定Poisson分布的参数
- lambda <- 2 # 假设每单位时间平均发生2次事件
- # 生成模拟数据
- data <- rpois(100, lambda)
- # 基于Poisson分布理论来识别异常值
- threshold.lower <- lambda - 3 * sqrt(lambda)
- threshold.upper <- lambda + 3 * sqrt(lambda)
- # 标记异常值
- outliers <- (data < threshold.lower) | (data > threshold.upper)
通过上述代码,我们生成了一组符合Poisson分布的数据,并且计算了上下限值来确定可能的异常值。这个方法可以应用于实际数据中,帮助我们识别和分析异常情况。
3. R语言在数据清洗中的应用
3.1 R语言的数据处理

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SGMII传输层优化:延迟与吞吐量的双重提升技术
雷达数据压缩技术突破:提升效率与存储优化新策略
【EDEM仿真非球形粒子专家】:揭秘提升仿真准确性的核心技术
社交网络分析工具大比拼:Gephi, NodeXL, UCINET优劣全面对比
【信号异常检测法】:FFT在信号突变识别中的关键作用
SaTScan软件的扩展应用:与其他统计软件的协同工作揭秘
Java SPI与依赖注入(DI)整合:技术策略与实践案例
Python环境监控高可用构建:可靠性增强的策略
【矩阵求逆的历史演变】:从高斯到现代算法的发展之旅
原型设计:提升需求沟通效率的有效途径


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















