大数据Flink编程实践
时间: 2023-12-19 07:03:43 浏览: 83
Flink是一个流式数据处理框架,它可以用于实时数据流处理和批处理。下面是Flink编程实践的一些步骤和方法:
1. 安装Flink:可以从Flink官网下载二进制文件并解压缩,然后启动Flink集群。
2. 编写Flink程序:Flink程序可以使用Java或Scala编写。Flink提供了DataStream和DataSet两个API,分别用于流处理和批处理。可以使用这些API来定义数据源、转换和汇聚操作。
3. 运行Flink程序:可以使用Flink命令行工具或Web界面提交Flink程序。Flink会将程序分发到集群中的所有节点上执行。
4. 监控Flink程序:Flink提供了Web界面和命令行工具来监控Flink程序的运行状态。可以使用这些工具来查看任务的状态、指标和日志信息。
5. 调试Flink程序:可以使用Flink提供的调试工具来调试Flink程序。可以在本地模式下运行程序,并使用调试器来单步执行程序并查看变量的值。
6. 部署Flink程序:可以将Flink程序打包成可执行的JAR文件,并将其部署到生产环境中。可以使用Flink提供的部署工具来管理Flink程序的部署和升级。
相关问题
flink初级编程实践wikilog
在flink初级编程实践wikilog中,你可以通过实验来掌握基本的Flink编程方法,并学会使用IntelliJ IDEA工具编写Flink程序。
在IDEA中进行调试时,需要注意先启动FlinkWordCount2词频统计程序,然后在NC程序窗口内连续输入一些hello world。你可以在个人电脑上打开一个浏览器,输入"http://101.132.242.168:8081"来访问Flink的WEB管理页面,通过点击左侧的"Task Managers",再点击链接来查看结果。
在编译FlinkWordCount项目时,你需要仿照之前的方法进行,但是在Project Structure->Module中要将maven文件的scope全部改为compile。<span class="em">1</span><span class="em">2</span><span class="em">3</span>
#### 引用[.reference_title]
- *1* *2* *3* [Flink初级编程实践(使用macOS上的IDEA远程调试服务器)——大数据基础编程实验之八](https://blog.csdn.net/weixin_44616879/article/details/120689033)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v93^chatsearchT3_2"}}] [.reference_item style="max-width: 100%"]
[ .reference_list ]
flink初级编程实践
Flink 是一个分布式流处理和批处理框架,可以用于大规模数据的实时处理和分析。下面是一个简单的 Flink 编程实践示例,用于计算输入流中每个单词的出现次数:
```java
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
public class WordCount {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 定义输入流
DataStream<String> input = env.addSource(new SimpleSource());
// 数据转换和处理
DataStream<Tuple2<String, Integer>> counts = input
.flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {
// 按空格拆分每行,并输出每个单词的次数
for (String word : value.split(" ")) {
out.collect(new Tuple2<>(word, 1));
}
})
.keyBy(0) // 按单词分组
.sum(1); // 求和
// 输出结果
counts.print();
// 执行程序
env.execute();
}
// 自定义数据源,用于提供输入数据
public static class SimpleSource implements SourceFunction<String> {
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (isRunning) {
ctx.collect("hello world");
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = f
相关推荐
最新推荐
优秀的java应届生个人简历模板.pdf
11. **流处理框架**:熟悉Spark和Flink,能使用它们进行数据的流处理和批处理,这是大数据实时分析的关键技术。 12. **项目经验**:通过图书商城、天狼星手机商城、微信订餐小程序后台管理和飞腾手机后台管理系统等...
99页PPT丨大型医药集团战略规划方案.pptx
99页PPT丨大型医药集团战略规划方案.pptx
数学建模题目等8个文件.7z
数学建模题目等8个文件.7z
个人经导师指导并认可通过的高分项目,评审分98分。主要针对计算机相关专业和需要项目实战练习的学习者,也可作为课程设计、期末大作业。
个人经导师指导并认可通过的高分项目,评审分98分。主要针对计算机相关专业和需要项目实战练习的学习者,也可作为课程设计、期末大作业。
个人经导师指导并认可通过的高分项目,评审分98分。主要针对计算机相关专业和需要项目实战练习的学习者,也可作为课程设计、期末大作业。
个人经导师指导并认可通过的高分项目,评审分98分。主要针对计算机相关专业和需要项目实战练习的学习者,也可作为课程设计、期末大作业。
音乐播放器的VHDL实现2.rar
音乐播放器的VHDL实现2
YF-S401水流量传感器
YF-S401水流量传感器
GO婚礼设计创业计划:技术驱动的婚庆服务
"婚礼GO网站创业计划书"
在创建婚礼GO网站的创业计划书中,创业者首先阐述了企业的核心业务——GO婚礼设计,专注于提供计算机软件销售和技术开发、技术服务,以及与婚礼相关的各种服务,如APP制作、网页设计、弱电工程安装等。企业类型被定义为服务类,涵盖了一系列与信息技术和婚礼策划相关的业务。
创业者的个人经历显示了他对行业的理解和投入。他曾在北京某科技公司工作,积累了吃苦耐劳的精神和实践经验。此外,他在大学期间担任班长,锻炼了团队管理和领导能力。他还参加了SYB创业培训班,系统地学习了创业意识、计划制定等关键技能。
市场评估部分,目标顾客定位为本地的结婚人群,特别是中等和中上收入者。根据数据显示,广州市内有14家婚庆公司,该企业预计能占据7%的市场份额。广州每年约有1万对新人结婚,公司目标接待200对新人,显示出明确的市场切入点和增长潜力。
市场营销计划是创业成功的关键。尽管文档中没有详细列出具体的营销策略,但可以推断,企业可能通过线上线下结合的方式,利用社交媒体、网络广告和本地推广活动来吸引目标客户。此外,提供高质量的技术解决方案和服务,以区别于竞争对手,可能是其市场差异化策略的一部分。
在组织结构方面,未详细说明,但可以预期包括了技术开发团队、销售与市场部门、客户服务和支持团队,以及可能的行政和财务部门。
在财务规划上,文档提到了固定资产和折旧、流动资金需求、销售收入预测、销售和成本计划以及现金流量计划。这表明创业者已经考虑了启动和运营的初期成本,以及未来12个月的收入预测,旨在确保企业的现金流稳定,并有可能享受政府对大学生初创企业的税收优惠政策。
总结来说,婚礼GO网站的创业计划书详尽地涵盖了企业概述、创业者背景、市场分析、营销策略、组织结构和财务规划等方面,为初创企业的成功奠定了坚实的基础。这份计划书显示了创业者对市场的深刻理解,以及对技术和婚礼行业的专业认识,有望在竞争激烈的婚庆市场中找到一席之地。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
【基础】PostgreSQL的安装和配置步骤
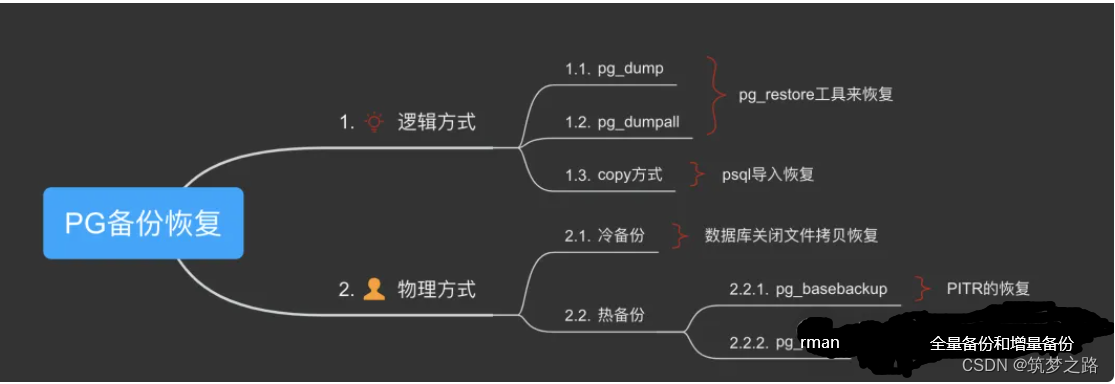
# 2.1 安装前的准备工作
### 2.1.1 系统要求
PostgreSQL 对系统硬件和软件环境有一定要求,具体如下:
- 操作系统:支持 Linux、Windows、macOS 等主流操作系统。
- CPU:推荐使用多核 CPU,以提高数据库处理性能。
- 内存:根据数据库规模和并发量确定,一般建议 8GB 以上。
- 硬盘:数据库文件和临时文件需要占用一定空间,建议预留足够的空间。
字节跳动面试题java
字节跳动作为一家知名的互联网公司,在面试Java开发者时可能会关注以下几个方面的问题:
1. **基础技能**:Java语言的核心语法、异常处理、内存管理、集合框架、IO操作等是否熟练掌握。
2. **面向对象编程**:多态、封装、继承的理解和应用,可能会涉及设计模式的提问。
3. **并发编程**:Java并发API(synchronized、volatile、Future、ExecutorService等)的使用,以及对并发模型(线程池、并发容器等)的理解。
4. **框架知识**:Spring Boot、MyBatis、Redis等常用框架的原理和使用经验。
5. **数据库相
微信行业发展现状及未来发展趋势分析
微信行业发展现状及未来行业发展趋势分析
微信作为移动互联网的基础设施,已经成为流量枢纽,月活跃账户达到10.4亿,同增10.9%,是全国用户量最多的手机App。微信的活跃账户从2012年起步月活用户仅为5900万人左右,伴随中国移动互联网进程的不断推进,微信的活跃账户一直维持稳步增长,在2014-2017年年末分别达到5亿月活、6.97亿月活、8.89亿月活和9.89亿月活。
微信月活发展历程显示,微信的用户数量增长已经开始呈现乏力趋势。微信在2018年3月日活达到6.89亿人,同比增长5.5%,环比上个月增长1.7%。微信的日活同比增速下滑至20%以下,并在2017年年底下滑至7.7%左右。微信DAU/MAU的比例也一直较为稳定,从2016年以来一直维持75%-80%左右的比例,用户的粘性极强,继续提升的空间并不大。
微信作为流量枢纽,已经成为移动互联网的基础设施,月活跃账户达到10.4亿,同增10.9%,是全国用户量最多的手机App。微信的活跃账户从2012年起步月活用户仅为5900万人左右,伴随中国移动互联网进程的不断推进,微信的活跃账户一直维持稳步增长,在2014-2017年年末分别达到5亿月活、6.97亿月活、8.89亿月活和9.89亿月活。
微信的用户数量增长已经开始呈现乏力趋势,这是因为微信自身也在重新寻求新的增长点。微信日活发展历程显示,微信的用户数量增长已经开始呈现乏力趋势。微信在2018年3月日活达到6.89亿人,同比增长5.5%,环比上个月增长1.7%。微信的日活同比增速下滑至20%以下,并在2017年年底下滑至7.7%左右。
微信DAU/MAU的比例也一直较为稳定,从2016年以来一直维持75%-80%左右的比例,用户的粘性极强,继续提升的空间并不大。因此,在整体用户数量开始触达天花板的时候,微信自身也在重新寻求新的增长点。
中国的整体移动互联网人均单日使用时长已经较高水平。18Q1中国移动互联网的月度总时长达到了77千亿分钟,环比17Q4增长了14%,单人日均使用时长达到了273分钟,环比17Q4增长了15%。而根据抽样统计,社交始终占据用户时长的最大一部分。2018年3月份,社交软件占据移动互联网35%左右的时长,相比2015年减少了约10pct,但仍然是移动互联网当中最大的时长占据者。
争夺社交软件份额的主要系娱乐类App,目前占比达到约32%左右。移动端的流量时长分布远比PC端更加集中,通常认为“搜索下載”和“网站导航”为PC时代的流量枢纽,但根据统计,搜索的用户量约为4.5亿,为各类应用最高,但其时长占比约为5%左右,落后于网络视频的13%左右位于第二名。PC时代的网络社交时长占比约为4%-5%,基本与搜索相当,但其流量分发能力远弱于搜索。
微信作为移动互联网的基础设施,已经成为流量枢纽,月活跃账户达到10.4亿,同增10.9%,是全国用户量最多的手机App。微信的活跃账户从2012年起步月活用户仅为5900万人左右,伴随中国移动互联网进程的不断推进,微信的活跃账户一直维持稳步增长,在2014-2017年年末分别达到5亿月活、6.97亿月活、8.89亿月活和9.89亿月活。
微信的用户数量增长已经开始呈现乏力趋势,这是因为微信自身也在重新寻求新的增长点。微信日活发展历程显示,微信的用户数量增长已经开始呈现乏力趋势。微信在2018年3月日活达到6.89亿人,同比增长5.5%,环比上个月增长1.7%。微信的日活同比增速下滑至20%以下,并在2017年年底下滑至7.7%左右。
微信DAU/MAU的比例也一直较为稳定,从2016年以来一直维持75%-80%左右的比例,用户的粘性极强,继续提升的空间并不大。因此,在整体用户数量开始触达天花板的时候,微信自身也在重新寻求新的增长点。
微信作为移动互联网的基础设施,已经成为流量枢纽,月活跃账户达到10.4亿,同增10.9%,是全国用户量最多的手机App。微信的活跃账户从2012年起步月活用户仅为5900万人左右,伴随中国移动互联网进程的不断推进,微信的活跃账户一直维持稳步增长,在2014-2017年年末分别达到5亿月活、6.97亿月活、8.89亿月活和9.89亿月活。
微信的用户数量增长已经开始呈现乏力趋势,这是因为微信自身也在重新寻求新的增长点。微信日活发展历程显示,微信的用户数量增长已经开始呈现乏力趋势。微信在2018年3月日活达到6.89亿人,同比增长5.5%,环比上个月增长1.7%。微信的日活同比增速下滑至20%以下,并在2017年年底下滑至7.7%左右。
微信DAU/MAU的比例也一直较为稳定,从2016年以来一直维持75%-80%左右的比例,用户的粘性极强,继续提升的空间并不大。因此,在整体用户数量开始触达天花板的时候,微信自身也在重新寻求新的增长点。
微信作为移动互联网的基础设施,已经成为流量枢纽,月活跃账户达到10.4亿,同增10.9%,是全国用户量最多的手机App。微信的活跃账户从2012年起步月活用户仅为5900万人左右,伴随中国移动互联网进程的不断推进,微信的活跃账户一直维持稳步增长,在2014-2017年年末分别达到5亿月活、6.97亿月活、8.89亿月活和9.89亿月活。
微信的用户数量增长已经开始呈现乏力趋势,这是因为微信自身也在重新寻求新的增长点。微信日活发展历程显示,微信的用户数量增长已经开始呈现乏力趋势。微信在2018年3月日活达到6.89亿人,同比增长5.5%,环比上个月增长1.7%。微信的日活同比增速下滑至20%以下,并在2017年年底下滑至7.7%左右。
微信DAU/MAU的比例也一直较为稳定,从2016年以来一直维持75%-80%左右的比例,用户的粘性极强,继续提升的空间并不大。因此,在整体用户数量开始触达天花板的时候,微信自身也在重新寻求新的增长点。