机器学习综合处理电影数据
时间: 2023-10-02 14:05:46 浏览: 32
对于机器学习综合处理电影数据,可以考虑以下步骤:
1. 数据采集:收集与电影相关的数据,例如电影类型、演员、导演、上映时间、票房收入等。可以从互联网上的公开数据源或者购买商业数据服务来获取。
2. 数据清洗与预处理:对采集到的数据进行清洗和预处理,包括去重、空值填充、异常值处理、数据转换等操作,以确保数据的准确性和完整性。
3. 特征工程:对数据进行特征提取和特征选择,以便机器学习算法能够更好地识别和分类电影。例如,可以提取电影类型、演员和导演的特征,以及将电影票房收入转换为分类标签等。
4. 模型训练与评估:选择适合的机器学习算法,例如分类、聚类、回归等,对预处理后的数据进行训练和评估。可以使用交叉验证等技术来评估模型的性能和准确率。
5. 模型部署与应用:将训练好的模型部署到生产环境中,用于实际应用场景,例如电影推荐、票房预测等。
以上步骤可以通过使用Python编程语言和相关的机器学习库,例如Scikit-learn和TensorFlow等来实现。
相关问题
机器学习wine数据处理
处理Wine数据集可以帮助我们理解机器学习中的一些基本概念和技术。下面是一些处理Wine数据集的常见步骤:
1. 下载Wine数据集,可以从UCI Machine Learning Repository或Scikit-Learn库中获得。
2. 导入数据集并进行预处理,包括数据清洗、数据转换、特征选择等。这一步可以使用Python的Pandas和Numpy库来完成。
3. 将数据集分为训练集和测试集。通常,我们将70%的数据用于训练,30%的数据用于测试。
4. 选择一个适当的机器学习算法来训练模型,如决策树、随机森林、支持向量机等。
5. 使用训练数据集来训练模型,并使用测试数据集来评估模型的性能。可以采用交叉验证等技术来提高模型的准确性。
6. 对模型进行调整和优化,以获得更好的性能。
7. 使用模型来进行预测,根据模型的输出来做出决策或推荐。
总的来说,处理Wine数据集可以帮助我们了解机器学习的基本流程和技术,为进一步学习和应用机器学习提供了一个很好的起点。
机器学习数据处理绘图软件
推荐您使用Python语言的matplotlib库进行机器学习数据处理和绘图。matplotlib是一个功能强大的绘图库,可以生成各种类型的图表,包括线图、散点图、柱状图、饼图等。它与Python的科学计算库NumPy和pandas非常兼容,可以方便地处理和可视化机器学习中的数据。
您可以使用matplotlib绘制数据的分布图、特征之间的相关性图、预测结果的曲线等。此外,matplotlib还支持自定义图表的样式、标签、标题等属性,以及保存图像为各种格式。
以下是一个简单的示例代码,用于绘制一条曲线:
```python
import numpy as np
import matplotlib.pyplot as plt
# 生成数据
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 绘制曲线
plt.plot(x, y)
plt.xlabel('x')
plt.ylabel('y')
plt.title('Sin Curve')
plt.show()
```
运行以上代码,您将得到一条正弦曲线的图像。您可以根据需要调整数据和图表样式来满足您的需求。
除了matplotlib,还有其他一些用于数据处理和绘图的Python库,如seaborn、plotly等,您可以根据自己的需求选择适合的库进行使用。
相关推荐
最新推荐
机器学习试题-试卷.docx
机器学习笔试选择题及答案 1. 在回归模型中,下列哪一项在权衡欠拟合(under-fitting)和过拟合(over-fitting)中影响最大?
经济学中的数据科学:机器学习与深度学习方法
这篇论文提供了在新兴经济应用的数据科学的最新进展的全面的最先进的综述。在深度学习模型、混合深度学习模型、混合机器学习和集成模型四个单独的类别上对新的数据科学方法进行了分析。
机器学习-线性回归整理PPT
总结常见的机器学习线性回归的方法,最小二乘法、局部加权法、岭回归、Lasso回归、多项式回归公式推导过程
lammps-reaxff-机器学习-电化学.pdf
深度学习神经网络、经典机器学习模型、材料基因工程入门与实战、图神经网络与实践、机器学习+Science 案例:催化、钙钛矿、太阳能电池、团簇、同素异形体、材料指纹、描述符、无机材料、量子点发光材料、半导体材料...
基于机器学习的电网设备故障综合研判分析
通过开展电网设备故障综合研判,进行数据的高效融合与深度挖掘,大幅度提升电网安全稳定运行水平,融合多元数据实现主动抢修,准确定位电网公司目前客户服务薄弱点,从而有效提升客户满意度,提高电网公司配网管理...
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL数据库性能提升秘籍:揭秘性能下降幕后真凶及解决策略
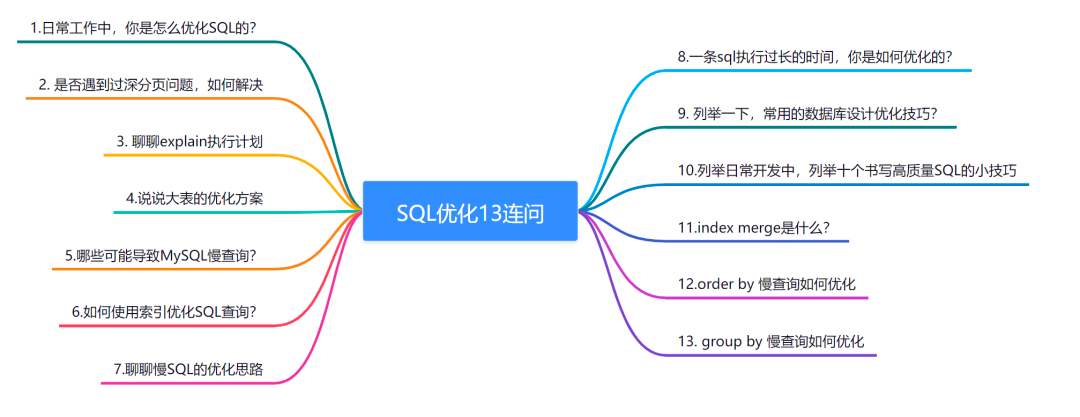
# 1. MySQL数据库性能优化概述**
MySQL数据库性能优化是一项至关重要的任务,可以显著提高应用程序的响应时间和整体用户体验。优化涉及识别和解决影响数据库性能的因素,包括硬件资源瓶颈、软件配置不当和数据库设计缺陷。通过采取适当的优化策略,可以显著提升数据库性能,满足业务需求并提高用户满意度。
# 2. MySQL数据库性能下降的幕后真凶
### 2.1 硬件资源瓶颈
#### 2.1.1 CPU利用率过高
**症状:
如何在unity创建按钮
在 Unity 中创建按钮的步骤如下:
1. 在 Unity 中创建一个 UI Canvas,选择 GameObject -> UI -> Canvas。
2. 在 Canvas 中创建一个按钮,选择 GameObject -> UI -> Button。
3. 在场景视图中调整按钮的位置和大小。
4. 在 Inspector 中设置按钮的文本、颜色、字体等属性。
5. 添加按钮的响应事件,选择按钮,在 Inspector 的 On Click () 中添加相应的方法。
这样就可以创建一个按钮了,你可以在游戏中使用它来触发相应的操作。
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。