chain.from_iterable用法
时间: 2023-03-31 13:01:43 浏览: 115
chain.from_iterable是一个函数,它可以将多个可迭代对象中的元素合并成一个迭代器,返回一个迭代器对象。它的用法如下:
from itertools import chain
iter1 = [1, 2, 3]
iter2 = [4, 5, 6]
iter3 = [7, 8, 9]
merged_iter = chain.from_iterable([iter1, iter2, iter3])
for item in merged_iter:
print(item)
输出结果为:
1
2
3
4
5
6
7
8
9
这个函数在处理多个可迭代对象时非常有用,可以避免多次循环,提高代码效率。
相关问题
list(filter(str.__len__, chain.from_iterable(map(partial(str.split, sep=separator), words)))) 讲讲这句python
这段代码是使用 Python 编写的,主要是对字符串进行处理和过滤。让我来解释一下每个部分的作用:
1. `map(partial(str.split, sep=separator), words)`:这部分代码使用 `map` 函数将 `words` 列表中的每个字符串按照指定的分隔符 `separator` 进行拆分。`str.split` 函数用于字符串分割,而 `partial` 函数用于创建一个新的函数,固定了 `str.split` 函数的第一个参数(即分隔符)。
2. `chain.from_iterable()`:这部分代码使用 `chain.from_iterable` 函数将多个可迭代对象合并成一个单一的可迭代对象。在这里,它将多个拆分后的字符串列表合并成一个单一的列表。
3. `filter(str.__len__, ...)`:这部分代码使用 `filter` 函数对可迭代对象中的元素进行过滤。`str.__len__` 是内置函数 `len` 的方法形式,用于判断字符串的长度是否为非零值,相当于过滤掉空字符串。
4. `list(...)`:最后,将过滤后的结果转换为列表。
总结起来,这段代码的作用是将一个字符串列表拆分成单个的单词,并过滤掉其中长度为零的字符串,最后返回一个列表。
[/public/home/pengjy/anaconda3] >>> PREFIX=/public/home/pengjy/anaconda3 WARNING: md5sum mismatch of tar archive expected: 8a581514493c9e0a1cbd425bc1c7dd90 got: 614f6284c34f91affd38a1be2e4be076 - Unpacking payload ... Traceback (most recent call last): File "entry_point.py", line 76, in <module> File "tarfile.py", line 2024, in extractall File "tarfile.py", line 2065, in extract File "tarfile.py", line 2137, in _extract_member File "tarfile.py", line 2186, in makefile File "tarfile.py", line 249, in copyfileobj tarfile.ReadError: unexpected end of data [210095] Failed to execute script entry_point concurrent.futures.process._RemoteTraceback: ''' Traceback (most recent call last): File "concurrent/futures/process.py", line 368, in _queue_management_worker File "multiprocessing/connection.py", line 251, in recv TypeError: __init__() missing 1 required positional argument: 'msg' ''' The above exception was the direct cause of the following exception: Traceback (most recent call last): File "entry_point.py", line 69, in <module> File "concurrent/futures/process.py", line 484, in _chain_from_iterable_of_lists File "concurrent/futures/_base.py", line 611, in result_iterator File "concurrent/futures/_base.py", line 439, in result File "concurrent/futures/_base.py", line 388, in __get_result concurrent.futures.process.BrokenProcessPool: A process in the process pool was terminated abruptly while the future was running or pending. [210105] Failed to execute script entry_point 是什么问题,如何解决?
根据您提供的错误信息,看起来是在解压缩文件时出现了问题,导致程序终止。错误信息中的"tarfile.ReadError: unexpected end of data"提示文件结束标记意外出现,可能是文件损坏或下载中断导致的。解决这个问题的方法是重新下载文件并确保完整性。
您可以尝试执行以下步骤来解决问题:
1. 删除当前下载的文件,确保没有残留的损坏文件。
2. 使用相同的下载链接重新下载文件。
3. 在下载完成后,验证文件的完整性。您可以使用md5sum或sha256sum等工具计算文件的哈希值,并与提供的预期哈希值进行比较,以确保文件完整无误。
4. 如果文件完整无误,再次尝试解压缩文件并运行程序。
如果问题仍然存在,请提供更多关于您的环境和操作的信息,以便更进一步地帮助您解决问题。
相关推荐
最新推荐
2848.png
2848
基于java的进销存或库存管理系统源码.zip
提供的源码资源涵盖了安卓应用、小程序、Python应用和Java应用等多个领域,每个领域都包含了丰富的实例和项目。这些源码都是基于各自平台的最新技术和标准编写,确保了在对应环境下能够无缝运行。同时,源码中配备了详细的注释和文档,帮助用户快速理解代码结构和实现逻辑。
适用人群:
这些源码资源特别适合大学生群体。无论你是计算机相关专业的学生,还是对其他领域编程感兴趣的学生,这些资源都能为你提供宝贵的学习和实践机会。通过学习和运行这些源码,你可以掌握各平台开发的基础知识,提升编程能力和项目实战经验。
使用场景及目标:
在学习阶段,你可以利用这些源码资源进行课程实践、课外项目或毕业设计。通过分析和运行源码,你将深入了解各平台开发的技术细节和最佳实践,逐步培养起自己的项目开发和问题解决能力。此外,在求职或创业过程中,具备跨平台开发能力的大学生将更具竞争力。
其他说明:
为了确保源码资源的可运行性和易用性,特别注意了以下几点:首先,每份源码都提供了详细的运行环境和依赖说明,确保用户能够轻松搭建起开发环境;其次,源码中的注释和文档都非常完善,方便用户快速上手和理解代码;最后,我会定期更新这些源码资源,以适应各平台技术的最新发展和市场需求。
计算机视觉+图片拼接+图片分割
计算机视觉+图片拼接+图片分割
onnxruntime-1.11.0-cp37-cp37m-linux_armv7l.whl.zip
python模块onnxruntime版本
onnxruntime-1.1.0-cp36-cp36m-linux_armv7l.whl.zip
python模块onnxruntime版本
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
确保MATLAB回归分析模型的可靠性:诊断与评估的全面指南
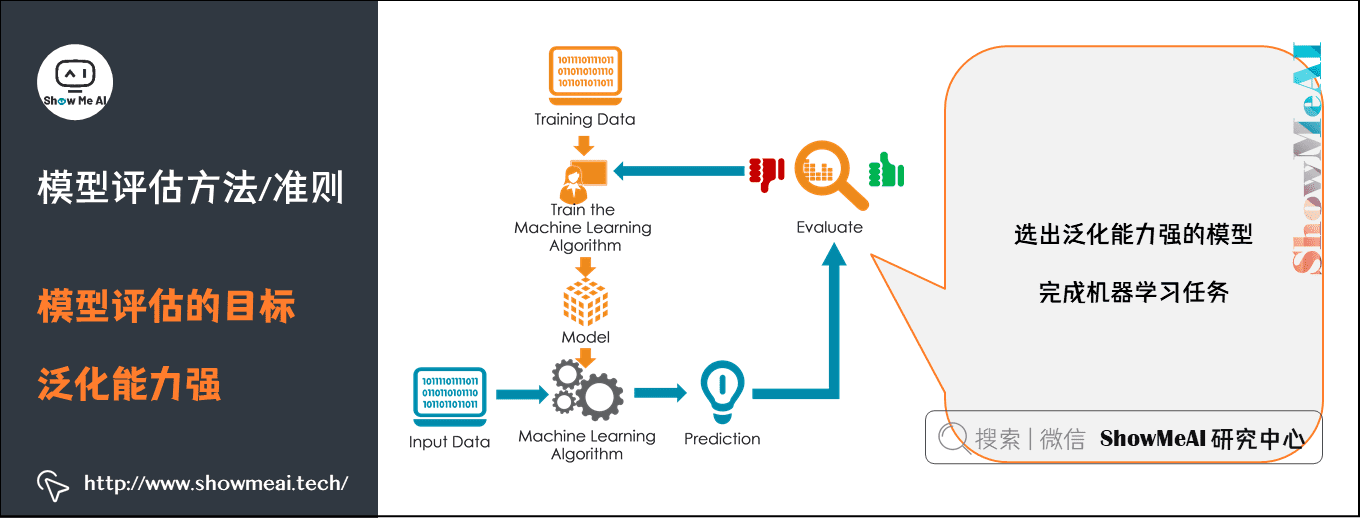
# 1. 回归分析模型的基础**
**1.1 回归分析的基本原理**
回归分析是一种统计建模技术,用于确定一个或多个自变量与一个因变量之间的关系。其基本原理是拟合一条曲线或超平面,以最小化因变量与自变量之间的误差平方和。
**1.2 线性回归和非线性回归**
线性回归是一种回归分析模型,其中因变量与自变量之间的关系是线性的。非线性回归模型则用于拟合因变量与自变量之间非
引发C++软件异常的常见原因
1. 内存错误:内存溢出、野指针、内存泄漏等;
2. 数组越界:程序访问了超出数组边界的元素;
3. 逻辑错误:程序设计错误或算法错误;
4. 文件读写错误:文件不存在或无法打开、读写权限不足等;
5. 系统调用错误:系统调用返回异常或调用参数错误;
6. 硬件故障:例如硬盘损坏、内存损坏等;
7. 网络异常:网络连接中断、网络传输中断、网络超时等;
8. 程序异常终止:例如由于未知原因导致程序崩溃等。
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。