high load database
时间: 2023-04-26 14:01:52 浏览: 93
高负载数据库是指在高并发访问下,数据库需要处理大量的请求和数据,需要具备高性能、高可用、高可靠等特点。为了应对高负载的情况,需要采用优化数据库结构、增加硬件资源、使用缓存技术、分布式部署等手段来提高数据库的性能和可用性。
相关问题
loadrunner error -27760
The LoadRunner error -27760 indicates a socket timeout error during a performance test. This error occurs when the server fails to respond within the configured timeout period.
To troubleshoot this error, you can try the following steps:
1. Verify the server's availability: Make sure that the server you are testing is up and running. Check if it is accessible from the LoadRunner machine.
2. Adjust the timeout settings: Increase the timeout value in the script or scenario settings to allow more time for the server to respond. You can find and modify these settings in the script or scenario properties.
3. Check network connectivity: Ensure that there are no network issues between the LoadRunner machine and the server under test. Check for any firewall or proxy configurations that may be blocking the communication.
4. Analyze server performance: If the server is responding slowly, investigate its performance and identify any bottlenecks that may be causing the timeout. This could include issues such as high CPU or memory usage, database queries taking too long, or any other performance-related problems.
5. Consider load balancing: If the application uses multiple servers or a load balancer, verify that the load is properly distributed among the servers. Uneven load distribution can cause timeouts on certain servers.
Additionally, you can review the LoadRunner logs and server logs for more detailed information about the error. If the issue persists, you may need to consult with your application or network administrators for further assistance in resolving the problem.
keepalived+mysql
Keepalived is a software that provides high availability and load balancing for Linux systems. It works by monitoring the health of servers and automatically redirecting traffic to healthy servers in case of failure. MySQL is an open-source relational database management system that is widely used in web applications. When combined, Keepalived and MySQL can provide a highly available and scalable database solution.
To set up Keepalived with MySQL, you need to have at least two MySQL servers running on different machines. Keepalived should be installed on both machines. The first step is to configure Keepalived to monitor the health of the MySQL servers. This can be done by setting up a health check script that checks the status of the MySQL service.
Once the health check is configured, Keepalived can be set up to redirect traffic to the healthy MySQL server. This can be done by configuring virtual IP addresses (VIPs) that are managed by Keepalived. The VIPs are assigned to the active MySQL server, and if the active server fails, the VIP is moved to the standby server.
To ensure data consistency between the MySQL servers, you can use MySQL replication. This involves setting up a master-slave configuration where one MySQL server acts as the master and the other as the slave. The master server replicates its data to the slave server in real-time, ensuring that both servers have the same data.
Overall, Keepalived and MySQL can provide a highly available and scalable database solution for web applications. By using Keepalived to monitor the health of MySQL servers and redirect traffic to healthy servers, and using MySQL replication to ensure data consistency, you can ensure that your database is always available and can handle high traffic loads.
相关推荐
最新推荐
微软内部资料-SQL性能优化3
An application should maintain the consistency of a database. For example, if you defer constraint checking, it is your responsibility to ensure that the database is consistent. Isolation Concurrent ...
nginx-1.24.0.tar
Nginx 1.24.0 是 Nginx 开源项目发布的一个重要更新版本,该版本在性能优化、功能增强以及安全性提升方面带来了诸多改进。当您下载 Nginx 1.24.0 的压缩包时,您将获得一个包含 Nginx 源代码的压缩文件,通常命名为 nginx-1.24.0.tar.gz(对于 GNU/Linux 和 macOS 系统)或类似的格式,具体取决于发布平台。
这个压缩包包含了编译 Nginx 服务器所需的所有源代码文件、配置文件模板(如 nginx.conf)、模块源码以及构建和安装说明。通过解压这个压缩包,您可以在支持 C 语言编译器的操作系统上编译并安装 Nginx 1.24.0。
Nginx 1.24.0 引入了一系列新特性和优化,可能包括但不限于对 HTTP/2 和 HTTP/3 协议的进一步支持、性能提升、新的模块或模块更新,以及对已知安全漏洞的修复。这使得 Nginx 能够在保持其作为高性能 HTTP 和反向代理服务器的声誉的同时,继续满足不断发展的网络需求。
智能化病虫害标注系统前端.zip
图像识别技术在病虫害检测中的应用是一个快速发展的领域,它结合了计算机视觉和机器学习算法来自动识别和分类植物上的病虫害。以下是这一技术的一些关键步骤和组成部分:
1. **数据收集**:首先需要收集大量的植物图像数据,这些数据包括健康植物的图像以及受不同病虫害影响的植物图像。
2. **图像预处理**:对收集到的图像进行处理,以提高后续分析的准确性。这可能包括调整亮度、对比度、去噪、裁剪、缩放等。
3. **特征提取**:从图像中提取有助于识别病虫害的特征。这些特征可能包括颜色、纹理、形状、边缘等。
4. **模型训练**:使用机器学习算法(如支持向量机、随机森林、卷积神经网络等)来训练模型。训练过程中,算法会学习如何根据提取的特征来识别不同的病虫害。
5. **模型验证和测试**:在独立的测试集上验证模型的性能,以确保其准确性和泛化能力。
6. **部署和应用**:将训练好的模型部署到实际的病虫害检测系统中,可以是移动应用、网页服务或集成到智能农业设备中。
7. **实时监测**:在实际应用中,系统可以实时接收植物图像,并快速给出病虫害的检测结果。
8. **持续学习**:随着时间的推移,系统可以不断学习新的病虫害样本,以提高其识别能力。
9. **用户界面**:为了方便用户使用,通常会有一个用户友好的界面,显示检测结果,并提供进一步的指导或建议。
这项技术的优势在于它可以快速、准确地识别出病虫害,甚至在早期阶段就能发现问题,从而及时采取措施。此外,它还可以减少对化学农药的依赖,支持可持续农业发展。随着技术的不断进步,图像识别在病虫害检测中的应用将越来越广泛。
Python 小游戏 (贪吃蛇、五子棋、扫雷、俄罗斯方块)
python
MATLAB/simulink 电力系统之变压器仿真-变压器空载运行仿真,磁通饱和+励磁电流
MATLAB/simulink 电力系统之变压器仿真- 变压器空载运行仿真,磁通饱和+励磁电流
AirKiss技术详解:无线传递信息与智能家居连接
AirKiss原理是一种创新的信息传输技术,主要用于解决智能设备与外界无物理连接时的网络配置问题。传统的设备配置通常涉及有线或无线连接,如通过路由器的Web界面输入WiFi密码。然而,AirKiss技术简化了这一过程,允许用户通过智能手机或其他移动设备,无需任何实际连接,就能将网络信息(如WiFi SSID和密码)“隔空”传递给目标设备。
具体实现步骤如下:
1. **AirKiss工作原理示例**:智能插座作为一个信息孤岛,没有物理连接,通过AirKiss技术,用户的微信客户端可以直接传输SSID和密码给插座,插座收到这些信息后,可以自动接入预先设置好的WiFi网络。
2. **传统配置对比**:以路由器和无线摄像头为例,常规配置需要用户手动设置:首先,通过有线连接电脑到路由器,访问设置界面输入运营商账号和密码;其次,手机扫描并连接到路由器,进行子网配置;最后,摄像头连接家庭路由器后,会自动寻找厂商服务器进行心跳包发送以保持连接。
3. **AirKiss的优势**:AirKiss技术简化了配置流程,减少了硬件交互,特别是对于那些没有显示屏、按键或网络连接功能的设备(如无线摄像头),用户不再需要手动输入复杂的网络设置,只需通过手机轻轻一碰或发送一条消息即可完成设备的联网。这提高了用户体验,降低了操作复杂度,并节省了时间。
4. **应用场景扩展**:AirKiss技术不仅适用于智能家居设备,也适用于物联网(IoT)场景中的各种设备,如智能门锁、智能灯泡等,只要有接收AirKiss信息的能力,它们就能快速接入网络,实现远程控制和数据交互。
AirKiss原理是利用先进的无线通讯技术,结合移动设备的便利性,构建了一种无需物理连接的设备网络配置方式,极大地提升了物联网设备的易用性和智能化水平。这种技术在未来智能家居和物联网设备的普及中,有望发挥重要作用。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
交叉验证全解析:数据挖掘中的黄金标准与优化策略
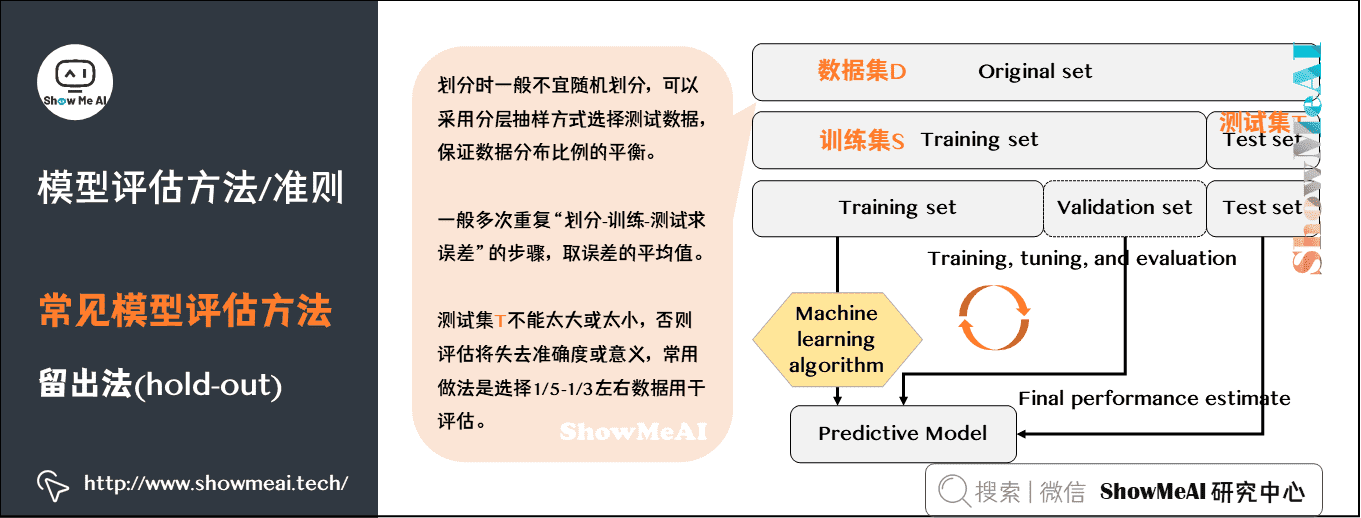
# 1. 交叉验证的基本概念和重要性
## 1.1 交叉验证的定义
交叉验证是一种统计方法,用于评估并改进机器学习模型的泛化能力。它通过将数据集分为几个小的“折”(或称为“子集”),然后迭代使用这些数据子集来训练和测试模型,从而得到模型性能的更准确估计。
## 1.2 交叉验证的重要性
在机器学习过程中,我们通常面临一个重要的问题:模型可能对训练数据过度拟合,而不能很好地推广到新数据
在交换机上创建 VLAN10、VLAN20和VLAN30,将交换机 B 的 2-5 接口加入到 VLAN 10 中 用ensp写出配置命令
在交换机上配置VLAN并分配接口到特定的VLAN中,通常需要登录到交换机的命令行界面。以下是在华为交换机上使用eNSP(Enterprise Network Simulation Platform,企业网络模拟平台)模拟器进行VLAN配置的基本步骤和命令:
首先,进入系统视图:
```
system-view
```
然后创建VLAN10、VLAN20和VLAN30:
```
vlan 10
vlan 20
vlan 30
```
接下来,将交换机B的2到5端口加入到VLAN10中,假设交换机B的接口编号为GigabitEthernet0/0/2至GigabitEthernet0/0/5
Hibernate主键生成策略详解
"Hibernate各种主键生成策略与配置详解"
在关系型数据库中,主键是表中的一个或一组字段,用于唯一标识一条记录。在使用Hibernate进行持久化操作时,主键的生成策略是一个关键的配置,因为它直接影响到数据的插入和管理。以下是Hibernate支持的各种主键生成策略的详细解释:
1. assigned: 这种策略要求开发者在保存对象之前手动设置主键值。Hibernate不参与主键的生成,因此这种方式可以跨数据库,但并不推荐,因为可能导致数据一致性问题。
2. increment: Hibernate会从数据库中获取当前主键的最大值,并在内存中递增生成新的主键。由于这个过程不依赖于数据库的序列或自增特性,它可以跨数据库使用。然而,当多进程并发访问时,可能会出现主键冲突,导致Duplicate entry错误。
3. hilo: Hi-Lo算法是一种优化的增量策略,它在一个较大的范围内生成主键,减少数据库交互。在每个session中,它会从数据库获取一个较大的范围,然后在内存中分配,降低主键碰撞的风险。
4. seqhilo: 类似于hilo,但它使用数据库的序列来获取范围,适合Oracle等支持序列的数据库。
5. sequence: 这个策略依赖于数据库提供的序列,如Oracle、PostgreSQL等,直接使用数据库序列生成主键,保证全局唯一性。
6. identity: 适用于像MySQL这样的数据库,它们支持自动增长的主键。Hibernate在插入记录时让数据库自动为新行生成主键。
7. native: 根据所连接的数据库类型,自动选择最合适的主键生成策略,如identity、sequence或hilo。
8. uuid: 使用UUID算法生成128位的唯一标识符,适用于分布式环境,无需数据库支持。
9. guid: 类似于uuid,但根据不同的实现可能会有所不同,通常在Windows环境下生成的是GUID字符串。
10. foreign: 通过引用另一个表的主键来生成当前表的主键,适用于关联实体的情况。
11. select: 在插入之前,通过执行SQL查询来获取主键值,这种方式需要开发者提供定制的SQL语句。
12. 注释方式配置: 可以通过在Java实体类的@Id和@GeneratedValue注解中指定generator属性来配置自定义的主键生成策略。
13. 小结: Hibernate的主键生成策略选择应基于数据库特性、性能需求以及是否需要跨数据库兼容等因素。在实际应用中,需要根据项目具体需求选择最适合的策略。
注意,合理选择主键生成策略对于数据库性能和数据一致性至关重要。例如,increment策略在多进程环境下可能会出现问题,而sequence和identity策略则更安全,但可能不适合所有数据库系统。因此,开发者应充分理解每种策略的优缺点,并结合实际情况作出决策。