简述内容页的编译原理是什么
时间: 2023-08-24 21:09:19 浏览: 86
内容页的编译原理是将网页中的HTML、CSS和JavaScript等静态资源解析、编译成浏览器可以识别和渲染的页面的过程。具体的步骤包括:
1. 解析HTML:浏览器将HTML代码解析成DOM树,DOM树是一种树形结构,它表示了HTML文档的结构和内容。
2. 解析CSS:浏览器将CSS代码解析成CSSOM树,CSSOM树是一种树形结构,它表示了CSS样式表的结构和样式。
3. 合并DOM和CSSOM:浏览器将DOM树和CSSOM树合并成一棵渲染树,渲染树是一种树形结构,它包含了所有需要渲染的元素以及它们的样式信息。
4. 布局:浏览器根据渲染树中的元素大小、位置等信息计算出它们在页面中的布局。
5. 绘制:浏览器将布局后的元素绘制成页面上的像素点。
6. JavaScript执行:浏览器将解析和编译JavaScript代码,并执行其中的逻辑,可以根据需要更新页面上的元素。
通过这些步骤,浏览器可以将网页的静态资源渲染成用户可以看到和交互的页面。
相关问题
简述执行JSP页面的原理。
JSP(Java Server Pages)是一种动态网页技术,其原理是将 HTML 页面中的 Java 代码嵌入到其中,服务器会在运行时动态地将 Java 代码解析成 Servlet,并最终生成 HTML 页面返回给客户端浏览器。
具体地说,当客户端请求一个 JSP 页面时,服务器会将该页面解析成一个 Servlet,并将其编译成 Java 字节码。然后服务器会创建一个 Servlet 实例并调用其 service() 方法,传入 HttpServletRequest 和 HttpServletResponse 对象,以便处理客户端的请求并生成相应的 HTML 页面。
在 service() 方法中,JSP 页面中的 Java 代码会被执行,并且可以通过内置对象(如 request、response、session、application 等)来访问客户端提交的请求数据或设置响应数据。最终,service() 方法会将生成的 HTML 页面作为响应返回给客户端浏览器。
简述AOP的实现原理
AOP(面向切面编程)的实现原理是基于动态代理。它通过在原有代码的基础上生成代理对象,并通过代理对象的方法来包装原有方法,从而实现对原有方法的增强。AOP的思想是将程序的功能分为不同的关注点(Aspect),通过预编译方式和运行期动态代理的方式,将这些关注点与主要业务逻辑进行解耦,从而提高程序的可维护性和可重用性。
AOP的应用场景广泛,可以用于日志记录、事务管理、权限控制等方面。通过AOP,我们可以将这些与主要业务逻辑无关的功能模块进行统一维护,提高代码的可读性和可维护性。
以下是一个使用AOP的简单示例:
```python
import time
# 定义一个装饰器函数,用于记录方法的执行时间
def log_execution_time(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
execution_time = end_time - start_time
print(f"方法 {func.__name__} 的执行时间为 {execution_time} 秒")
return result
return wrapper
# 应用装饰器
@log_execution_time
def calculate_sum(n):
sum = 0
for i in range(1, n+1):
sum += i
return sum
# 调用被装饰的方法
result = calculate_sum(1000000)
print(f"计算结果为:{result}")
```
在上述示例中,我们定义了一个装饰器函数`log_execution_time`,它用于记录方法的执行时间。通过在`calculate_sum`方法上应用该装饰器,我们可以在方法执行前后打印出方法的执行时间。这样,我们就实现了对方法的增强,而不需要修改原有的方法代码。
相关推荐
最新推荐
计算机组成原理第四次作业答案.doc
6.简述控制存储器存储的内容,以及与主存的区别。 7.微指令可分为哪两部分?各自作用是什么? 8.采用分段直接编译法时,微命令分组的原则是什么? 9.什么是功能转移? 10.后续微地址的形成方式有哪些? 11. ...
c++面试题基础分享.doc
18.C++文件编译与执行的四个阶段 19.extern关键字的作用 20.#define和const的区别 21.结构体struct和共同体union(联合)的区别 22.C++中vector和list的区别 23.结构体和类的区别 24.STL中map和set的原理...
基于FPGA的HDB3码的编码器
最后,对HDB3码的编译原理进行重点分析,并且以VHDL语言为主,分别对编码器部分和译码器部分的具体实现方法进行说明,给出具体设计的思考方案和程序流程图,并对设计方案进行软件仿真,同时给出仿真结果并对其进行...
net学习笔记及其他代码应用
23..net Remoting 的工作原理是什么? 答:服务器端向客户端发送一个进程编号,一个程序域编号,以确定对象的位置。 24.在C#中,string str = null 与 string str = “” 请尽量使用文字或图象说明其中的区别。 ...
“人力资源+大数据+薪酬报告+涨薪调薪”
人力资源+大数据+薪酬报告+涨薪调薪,在学习、工作生活中,越来越多的事务都会使用到报告,通常情况下,报告的内容含量大、篇幅较长。那么什么样的薪酬报告才是有效的呢?以下是小编精心整理的调薪申请报告,欢迎大家分享。相信老板看到这样的报告,一定会考虑涨薪的哦。
工业AI视觉检测解决方案.pptx
工业AI视觉检测解决方案.pptx是一个关于人工智能在工业领域的具体应用,特别是针对视觉检测的深入探讨。该报告首先回顾了人工智能的发展历程,从起步阶段的人工智能任务失败,到专家系统的兴起到深度学习和大数据的推动,展示了人工智能从理论研究到实际应用的逐步成熟过程。
1. 市场背景:
- 人工智能经历了从计算智能(基于规则和符号推理)到感知智能(通过传感器收集数据)再到认知智能(理解复杂情境)的发展。《中国制造2025》政策强调了智能制造的重要性,指出新一代信息技术与制造技术的融合是关键,而机器视觉因其精度和效率的优势,在智能制造中扮演着核心角色。
- 随着中国老龄化问题加剧和劳动力成本上升,以及制造业转型升级的需求,机器视觉在汽车、食品饮料、医药等行业的渗透率有望提升。
2. 行业分布与应用:
- 国内市场中,电子行业是机器视觉的主要应用领域,而汽车、食品饮料等其他行业的渗透率仍有增长空间。海外市场则以汽车和电子行业为主。
- 然而,实际的工业制造环境中,由于产品种类繁多、生产线场景各异、生产周期不一,以及标准化和个性化需求的矛盾,工业AI视觉检测的落地面临挑战。缺乏统一的标准和模型定义,使得定制化的解决方案成为必要。
3. 工业化前提条件:
- 要实现工业AI视觉的广泛应用,必须克服标准缺失、场景多样性、设备技术不统一等问题。理想情况下,应有明确的需求定义、稳定的场景设置、统一的检测标准和安装方式,但现实中这些条件往往难以满足,需要通过技术创新来适应不断变化的需求。
4. 行业案例分析:
- 如金属制造业、汽车制造业、PCB制造业和消费电子等行业,每个行业的检测需求和设备技术选择都有所不同,因此,解决方案需要具备跨行业的灵活性,同时兼顾个性化需求。
总结来说,工业AI视觉检测解决方案.pptx着重于阐述了人工智能如何在工业制造中找到应用场景,面临的挑战,以及如何通过标准化和技术创新来推进其在实际生产中的落地。理解这个解决方案,企业可以更好地规划AI投入,优化生产流程,提升产品质量和效率。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL运维最佳实践:经验总结与建议
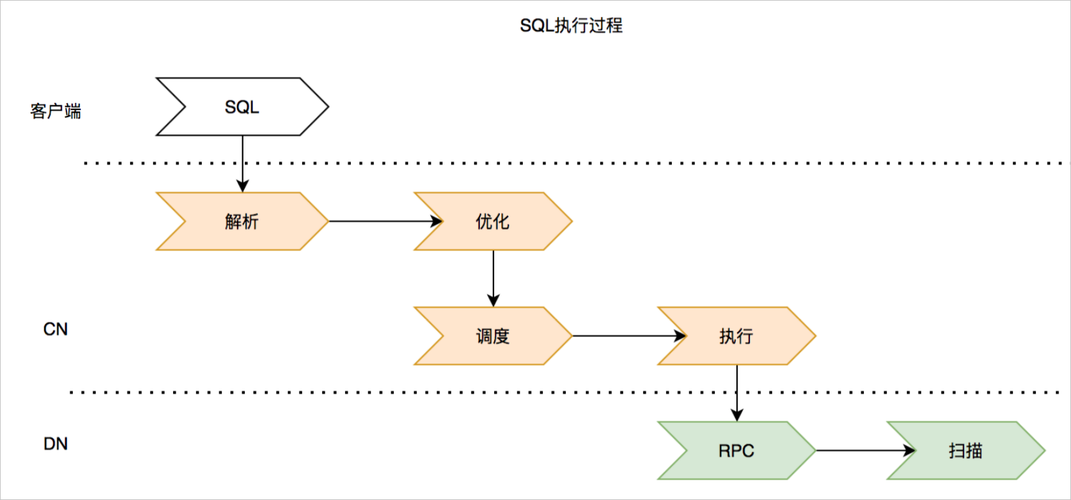
# 1. MySQL运维基础**
MySQL运维是一项复杂而重要的任务,需要深入了解数据库技术和最佳实践。本章将介绍MySQL运维的基础知识,包括:
- **MySQL架构和组件:**了解MySQL的架构和主要组件,包括服务器、客户端和存储引擎。
- **MySQL安装和配置:**涵盖MySQL的安装过
stata面板数据画图
Stata是一个统计分析软件,可以用来进行数据分析、数据可视化等工作。在Stata中,面板数据是一种特殊类型的数据,它包含了多个时间段和多个个体的数据。面板数据画图可以用来展示数据的趋势和变化,同时也可以用来比较不同个体之间的差异。
在Stata中,面板数据画图有很多种方法。以下是其中一些常见的方法
智慧医院信息化建设规划及愿景解决方案.pptx
"智慧医院信息化建设规划及愿景解决方案.pptx"
在当今信息化时代,智慧医院的建设已经成为提升医疗服务质量和效率的重要途径。本方案旨在探讨智慧医院信息化建设的背景、规划与愿景,以满足"健康中国2030"的战略目标。其中,"健康中国2030"规划纲要强调了人民健康的重要性,提出了一系列举措,如普及健康生活、优化健康服务、完善健康保障等,旨在打造以人民健康为中心的卫生与健康工作体系。
在建设背景方面,智慧医院的发展受到诸如分级诊疗制度、家庭医生签约服务、慢性病防治和远程医疗服务等政策的驱动。分级诊疗政策旨在优化医疗资源配置,提高基层医疗服务能力,通过家庭医生签约服务,确保每个家庭都能获得及时有效的医疗服务。同时,慢性病防治体系的建立和远程医疗服务的推广,有助于减少疾病发生,实现疾病的早诊早治。
在规划与愿景部分,智慧医院的信息化建设包括构建完善的电子健康档案系统、健康卡服务、远程医疗平台以及优化的分级诊疗流程。电子健康档案将记录每位居民的动态健康状况,便于医生进行个性化诊疗;健康卡则集成了各类医疗服务功能,方便患者就医;远程医疗技术可以跨越地域限制,使优质医疗资源下沉到基层;分级诊疗制度通过优化医疗结构,使得患者能在合适的层级医疗机构得到恰当的治疗。
在建设内容与预算方面,可能涉及硬件设施升级(如医疗设备智能化)、软件系统开发(如电子病历系统、预约挂号平台)、网络基础设施建设(如高速互联网接入)、数据安全与隐私保护措施、人员培训与技术支持等多个方面。预算应考虑项目周期、技术复杂性、维护成本等因素,以确保项目的可持续性和效益最大化。
此外,"互联网+医疗健康"的政策支持鼓励创新,智慧医院信息化建设还需要结合移动互联网、大数据、人工智能等先进技术,提升医疗服务的便捷性和精准度。例如,利用AI辅助诊断、物联网技术监控患者健康状态、区块链技术保障医疗数据的安全共享等。
智慧医院信息化建设是一项系统工程,需要政府、医疗机构、技术供应商和社会各方共同参与,以实现医疗服务质量的提升、医疗资源的优化配置,以及全民健康水平的提高。在2023年的背景下,这一进程将进一步加速,为我国的医疗健康事业带来深远影响。